























J.D Nicholls
Founder at @marketx_ai | Digital nomad 🎒 | Mentor 👨🏫 | Speaker 🗣️ | Developer 👨💻 | Creator of @proyecto26 #opensource #developer
Digital nomad 🎒 | Mentor 👨🏫 | Speaker 🗣️ |
Full-Stack Web3 Engineer (JS, Python, C#) 👨💻 |
Open Source Contributor 🍫 |
Creator of @proyecto26 🧚
👷 Founder of MarketX 🤖 + 📇 + ₿ = 🛍️
MarkertX, the next generation of e-commerce powered by GenAI and 3D printing
Imitar funciones cognitivas humanas, simular la inteligencia de los seres vivos para solucionar problemas.
Con la AI se busca que las máquinas aprendan de los datos y usen esos resultados en las tomas de decisiones.
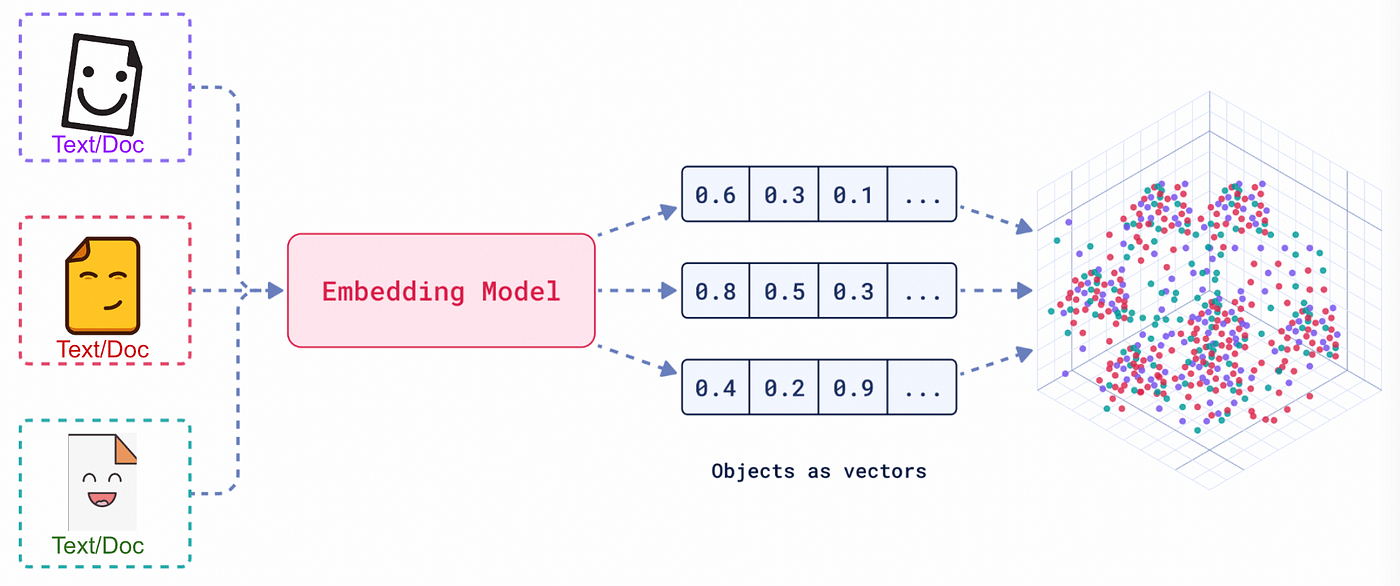
Convirtiendo todos los datos (texto, imágenes, video, audio, etc) en representaciones numéricas, usando NLP (procesamiento del lenguaje natural)
Es la ciencia de desarrollo de Algoritmos y modelos estadísticos que usan los sistemas de computación con el fin de llevar a cabo tareas sin instrucciones explícitas
- Automatización de procesos robóticos (RPA)
- Negociación bursátil automatizada
- Servicios de atención al cliente
- Reconocimiento de voz
- Computer visión
- Motores de recomandación
- Detección del fraude
- Unsupervised Learning
- Reinforcement Learning
- Supervised Learning: Regression, Classification
- Multivariate Calculus
- Algorithm & Complexity
- Optimization
- Probability Theory & Statistics
- Linear Algebra
- TensorFlow
- Keras
- Neural networks
- CNN, RNN, GAN, LSTM
- Linear logistic Regression
- KNN
- K-means
- Random forest
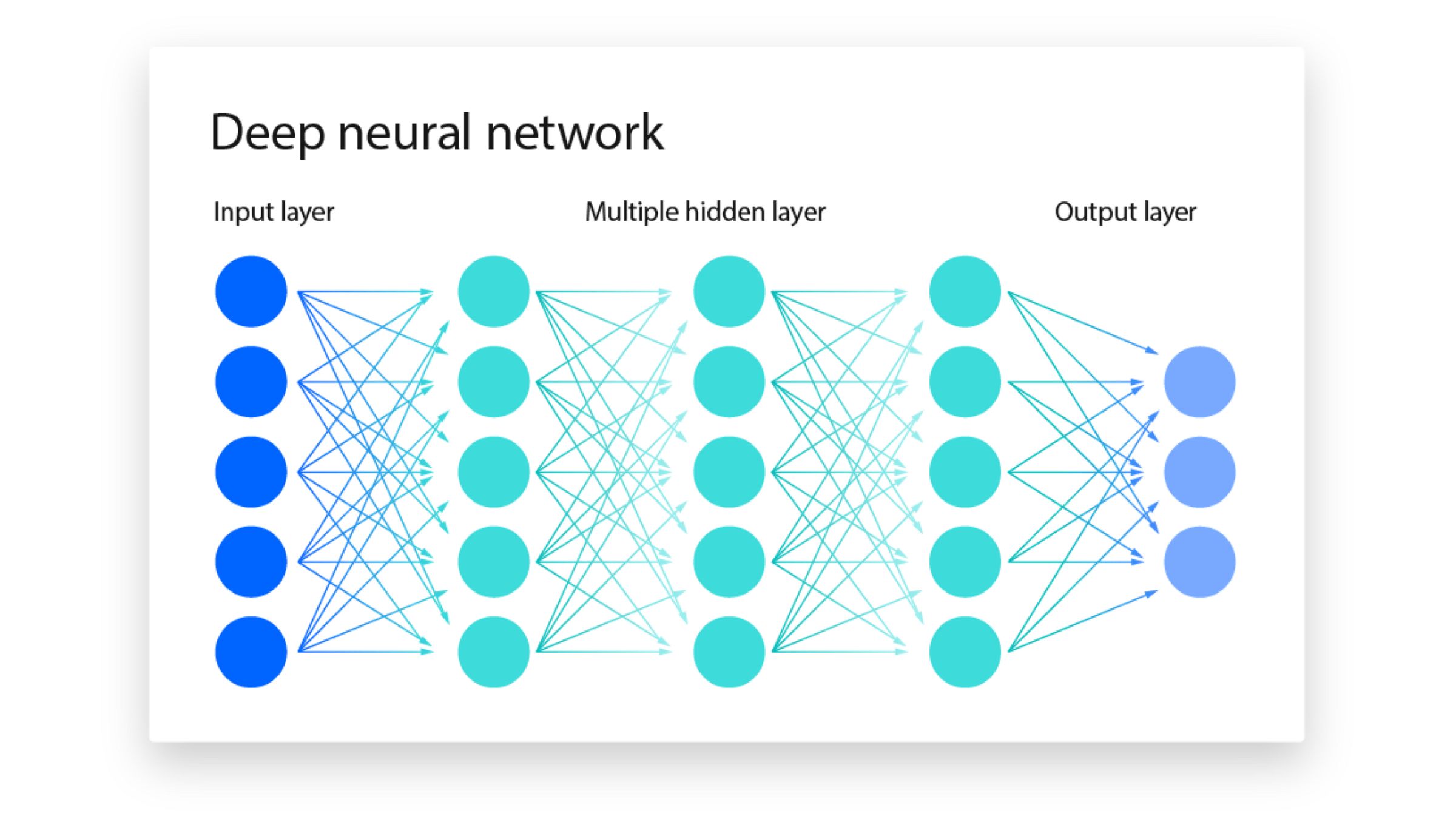
El aprendizaje profundo extiende el Machine learning para aprender y procesar la información, usando operaciones micromatemáticas en pequeños datos para resolver un problema mayor.
A diferencia del Machine Learning, no requiere de intervención humana, por lo tanto no requiere datos estructurados por humanos.
Forman el núcleo de las tecnologías de IA, reflejando el procesamiento que sucede en el cerebro.
El cerebro contiene millones de neuronas que trabajan para procesar y analizar la información. Por tanto la AI usa redes neuronales artificiales que procesan toda la información en conjunto.
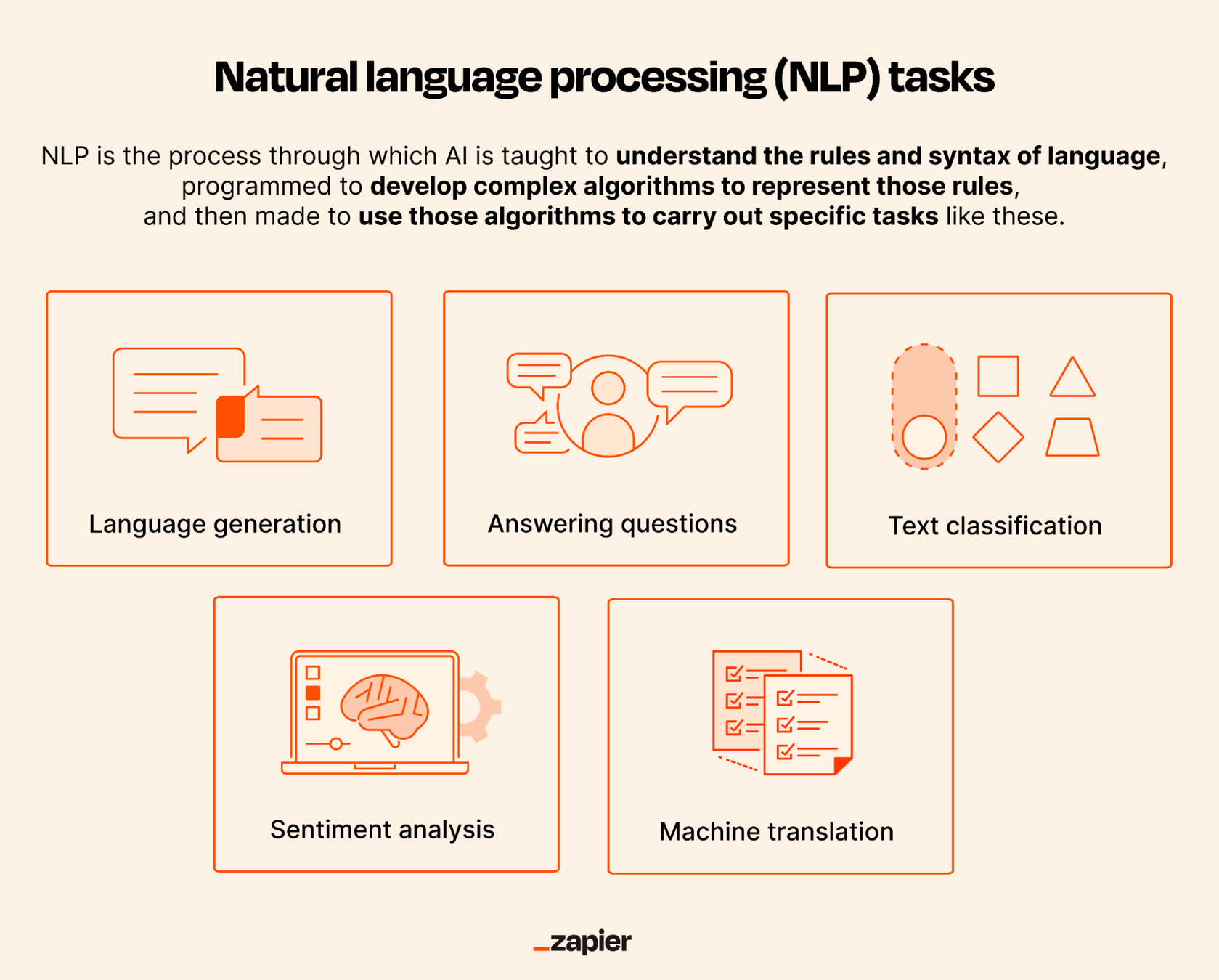
El NLP usa redes neuronales para interpretar, comprender y recopilar el significado de los datos, usando técnicas informáticas para decodificar y comprender el lenguaje.
Las máquinas logran procesar palabras, sintaxis gramaticales y combinaciones de palabras para procesar texto.
Usa técnicas de aprendizaje profundo para extraer información de documentos, vídeos, etc.
🎭
Sistemas de AI que crean contenido, generando artefactos a partir de simples peticiones de texto. La GenAI aprovecha el aprendizaje profundo y datos masivos para crear nuevos resultados creativos similares a los producidos por humanos.
Son modelos de AI diseñados para comprender y generar lenguaje natural, archivos multimedia, código fuente y cualquier prompt.
Se creean mediante:
- Entrenamiento con grandes cantidades de datos (Millones de parámetros)
- Aprenden patrones, estructuras y matices del lenguaje
- Arquitectura Transformer: usando Deep learning con un algoritmo de "Atención" (Encoder y Decoder) para comprender las relaciones entre las palabras y frases que contienen
- OpenAI Platform
- Google AI Studio
- Claude
- Azure AI Studio
- Ollama, Groq
Es un parámetro que controla el nivel de aleatoriedad en las respuestas generadas por el modelo.
Alucinaciones
Ocurre cuando el modelo genera info incorrecta, pueden parecer confiables porque el LLM no tiene la capacidad de discernimiento.
Proceso que consta de tomar el set de datos para ajustar el modelo pre-entrenado y adaptarlo a una tarea particular o dominio concreto. Permite que el modelo mejore su rendimiento en un contexto específico.
- Clasificación de texto
- Búsqueda semántica
- Reconocimiento de entidades nombradas
- Chatbots
- Generación de contenido (GenAI)
- Asistencia en código (CodeLlama, Codestral)
- Educación asistida (Tutores virtuales)
- Traducción
- Resumen, paráfrasis
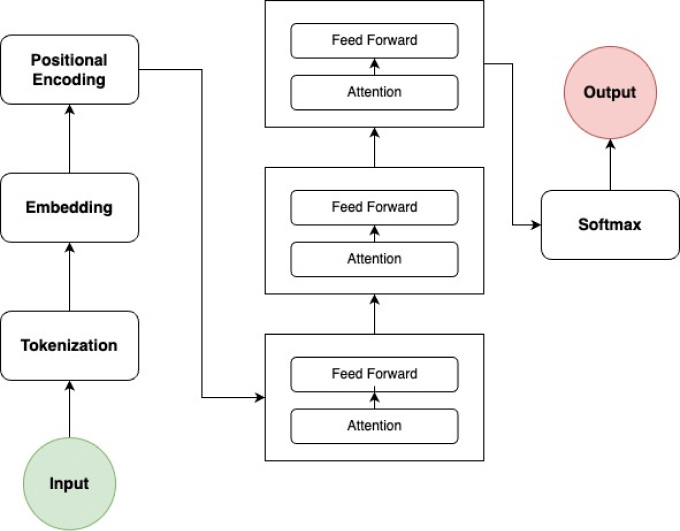
Son LLMs capaces de entrenarse sin supervisión (autoaprendizaje). Con un mecanismo de atención aprenden a entender la gramática, los idiomas y los conocimientos básicos (enfoque).
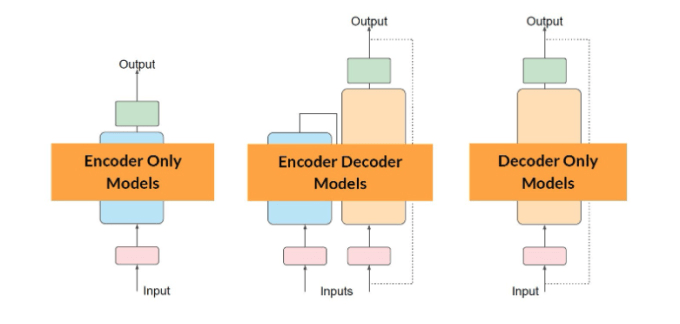
Están compuestos de dos cosas:
1. Codificador: convierte el texto en representaciones numéricas mediante vectores multidimensionales, organizando las palabras en un espacio vectorial según su significado contextual.
2. Decodificador: usa esta información para generar una salida coherente y natural, produciendo texto fluido y con contexto
Los transformadores procesan secuencias de texto enteras en paralelo
Encoder
Input: Datos (texto, media)
Ouput: representación (embedding)
Decoder
Genera nuevos tokens para completar una secuencia (un token al tiempo)
Seq2Seq
Input: procesa la secuencia en un embedding de contexto
Output: secuencia
The objective of a LLM is to predict the next token, given a sequence of previous tokens.
Es cada uno de los bloques que conforman nuestra secuencia de datos (palabras, carácteres o sub-palabras) para tener una unidad de información que los LLMs puedan procesar.
Para lograrlo se asigna un vector a cada uno de estos tokens, el cual está compuesto de etiquetas por cada dimensión a representar.
Cada LLM tiene tokens especiales específicos del modelo. Estos tokens son usados para abrir y cerrar los componentes estructurados de su generación.
Los special tokens permiten indicar el inicio y final de una secuencia, mensaje o respuesta.
Las indicaciones de entrada (input prompts) están estructuradas con tokens especiales, las cuales varían según el proveedor del modelo, y el más importante es el token de fin de secuencia (EOS).
You can check out the configuration of the model in its Hub repository. For example, you can find the special tokens of the SmolLM2 model in its tokenizer_config.json
| Model | Provider | EOS Token | Functionality |
|---|---|---|---|
| GPT4 | OpenAI | <|endoftext|> | End of message text |
| Llama 3 | Meta (Facebook AI Research) | <|eot_id|> | End of sequence |
| Deepseek-R1 | DeepSeek | <|end_of_sentence|> | End of message text |
| SmolLM2 | Hugging Face | <|im_end|> | End of instruction or message |
| Gemma | <end_of_turn> | End of conversation turn |
El modelo seguirá generando tokens hasta que encuentre un EOS token (End of Sequence, o “Fin de Secuencia”).
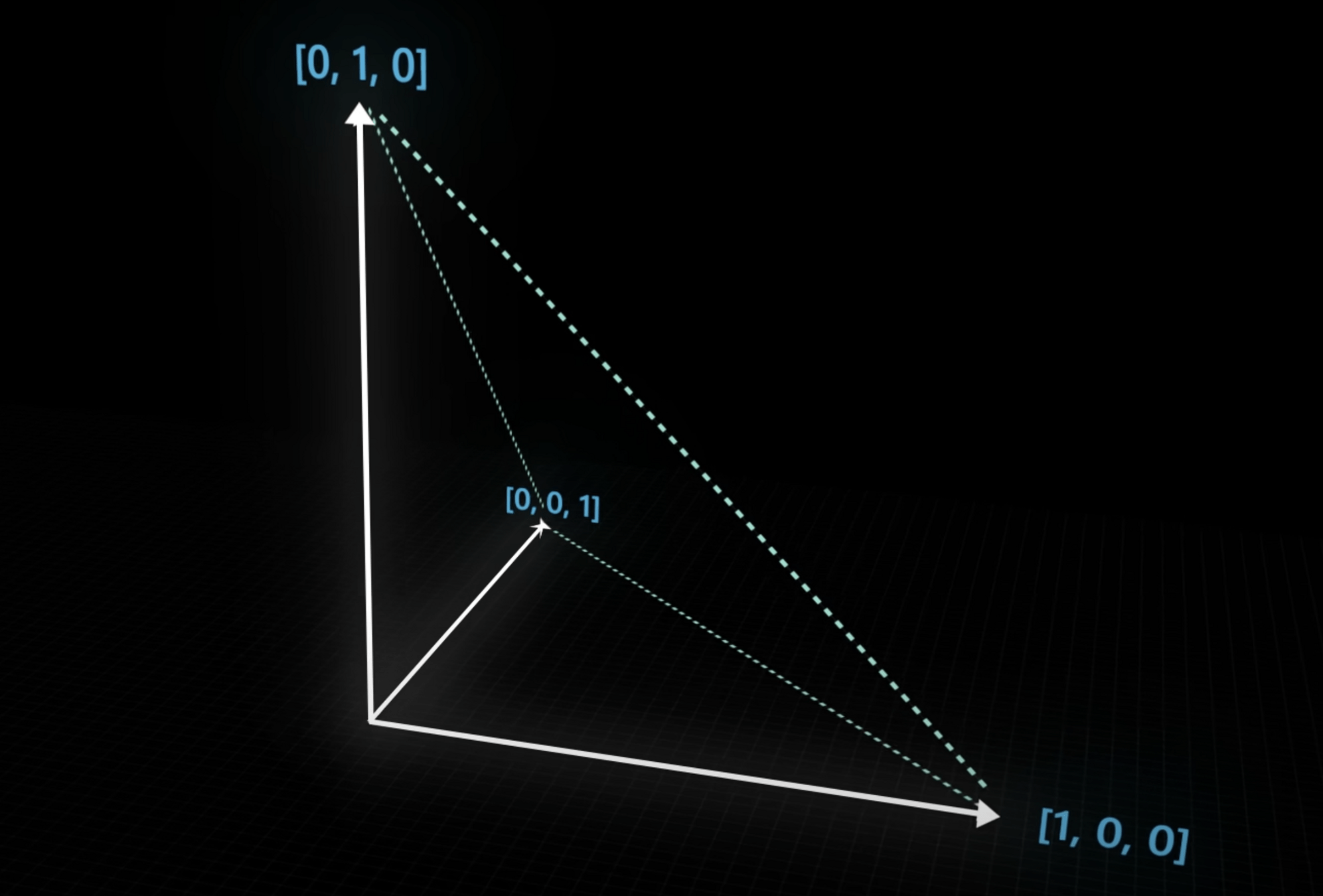
Es una técnica donde cada una de las posiciones de un vector representa una palabra
Cada palabra ocupa su propia dimensión, por lo que la distancia entre cada palabra siempre es la misma.
Los tokens son representaciones de vectores que permiten que el modelo entienda la relación y el significado de las palabas en un espacio numérico.
Se logra una estructura de nuestro vocabulario, mediante un proceso de compactación (reducir dimensionalidad), donde las palabras o sub-palabras similares van a ser representadas de manera próxima (cluster)
Los LLMs son autorregresivos, por lo que la salida de un paso se convierte en la entrada del siguiente.
Este ciclo continua hasta que el modelo predice que el próximo token será el EOS y se detiene.
Un LLM decodifica el texto hasta alcanzar el EOS. Con estos tokens se calcula una representación de la secuencia que captura el significado y posición de cada token en la secuencia:
El modelo usa la representación y asigna puntajes a cada token para estimar su probabilidad de ser el siguiente en la secuencia.
La idea es seleccionar los tokens que completen la secuencia, y para esto hay varias estrategias basado en estos puntajes.
The easiest decoding strategy would be to always take the token with the maximum score.
Explora múltiples secuencias candidatas para encontrar aquella con el puntaje total más alto, incluso si algunos tokens individuales tienen puntajes más bajos.
Es un aspecto clave de la Arquitectura Transformer. Al predecir el siguiente token, no todas las partes de la sentencia tienen la misma importancia (significado).
Este mecanismo de Atención para identificar las palabras más relevantes y predecir el siguiente token ha demostrado ser muy efectivo. En los LLMs, la longitud de contexto nos determina el número máximo de tokens que el modelo puede procesar y la capacidad máxima de atención que tiene.
1. Self-Attention: Cada token atiende a todos los demás tokens de la misma secuencia (incluyéndose a sí mismo) para capturar dependencias contextuales.
2. Masked Self-Attention: Variante que bloquea tokens futuros en tareas de generación (como en GPT) para evitar mirar palabras aún no generadas.
3. Cross-Attention: Un conjunto de tokens (como el decodificador) atiende a otro conjunto diferente (como el codificador), común en traducción automática y modelos encoder-decoder.
4. Multi-Head Attention: Usa múltiples “cabezas” de atención en paralelo para capturar distintas relaciones o patrones entre tokens.
5. Sparse Attention: Solo se permite atención entre algunos tokens seleccionados (no todos), para reducir el costo computacional en secuencias largas.
6. Global/Local Attention: Algunos tokens tienen acceso global (pueden atender a toda la secuencia) y otros solo de forma local (ventanas cercanas). Usado en modelos como Longformer.
7. Linear Attention: Aproximación matemática que reduce la complejidad de atención de O(n²) a O(n), haciéndola mucho más escalable. Usado en modelos como Performer y Linear Transformer.
8. Ghost Attention: Técnica de Meta para mantener las instrucciones del mensaje del sistema a lo largo de la conversación sin tener que repetirlas explícitamente, su propósito es mantener las instrucciones del system prompt activas durante múltiples turnos de conversación.
La redacción de la secuencia de entrada es muy importante, teniendo en cuenta que el LLM predice el siguiente token observando cada token de entrada y elegiendo que tokens son importantes, a esta secuencia de entrada es lo que se denomina un prompt.
El modelo usa Inferencia a partir de un prompt, prediciendo el siguiente fragmento de texto basado en las instrucciones que se le da.
Token
Unidad de texto para entender el lenguaje, dividen el prompt en tokens para analizar y generar respuestas.
Context Window
El modelo tiene un límite de tokens, una cantidad máxima que puede procesar a la vez. Esta ventana limita la calidad de la respuesta.
Diseñar entradas específicas para mejorar la calidad de las respuestas de LLMs.
Técnicas
- Few-shot learning: Proporcionar ejemplos en el prompt.
- Role prompting: Asignar un rol específico.
- Uso del contexto: Incluir detalles relevantes en el prompt.
Los modelos pueden tener sesgos debido a datos de entrenamiento, por lo que hay que usarlos de manera ética.
Los LLMs se entrenan con grandes conjuntos de texto para predecir la siguiente palabra mediante aprendizaje auto-supervisado o modelado de lenguaje enmascarado, lo que les permite captar la estructura del lenguaje y generalizar a nuevos datos.
Tras este pre-entrenamiento, pueden ajustarse (fine-tuning) para tareas específicas como conversación, clasificación o generación de código.
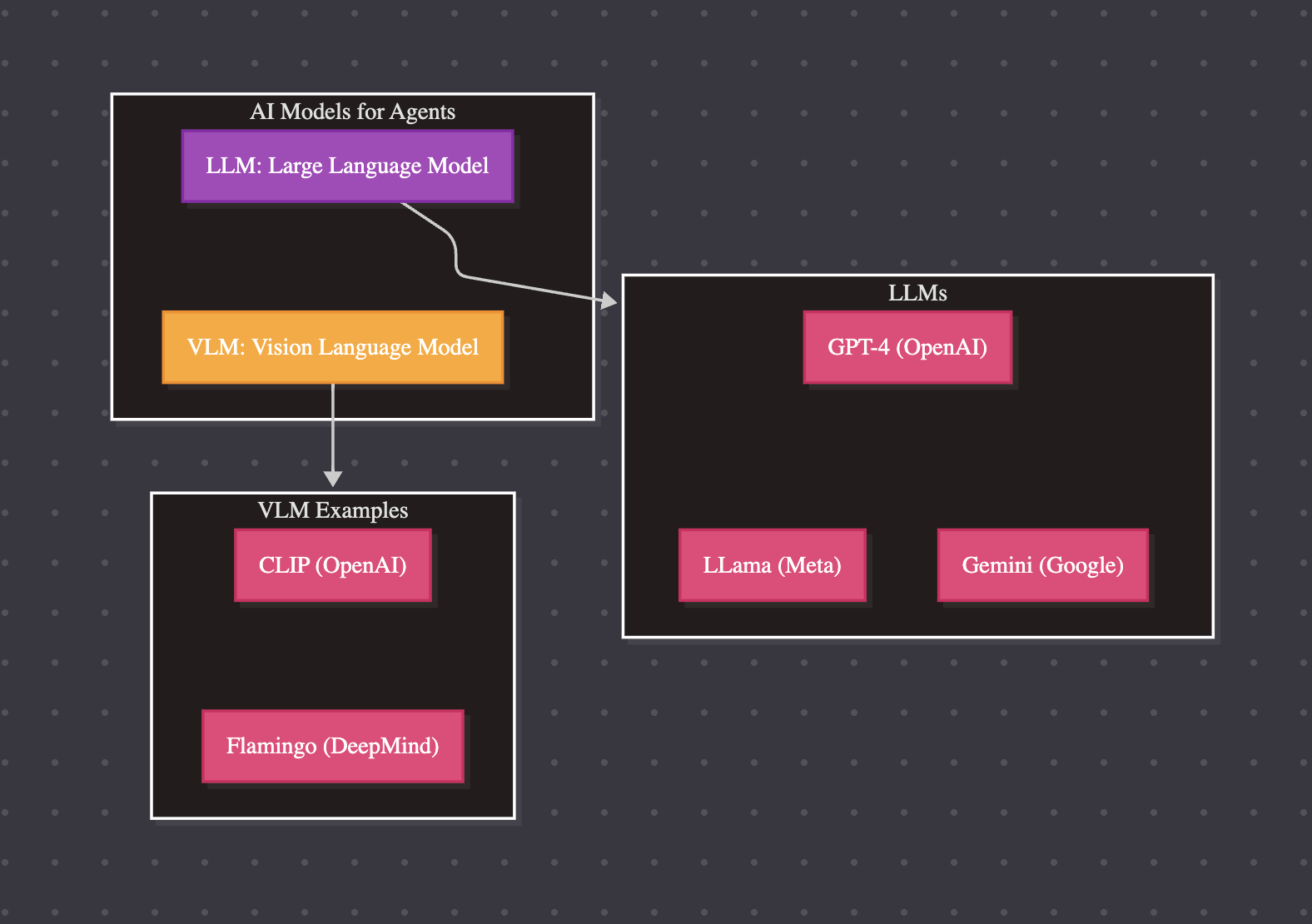
Los LLMs son un componente clave en los Agentes de IA, ya que proporcionan la base para comprender y generar lenguaje humano.
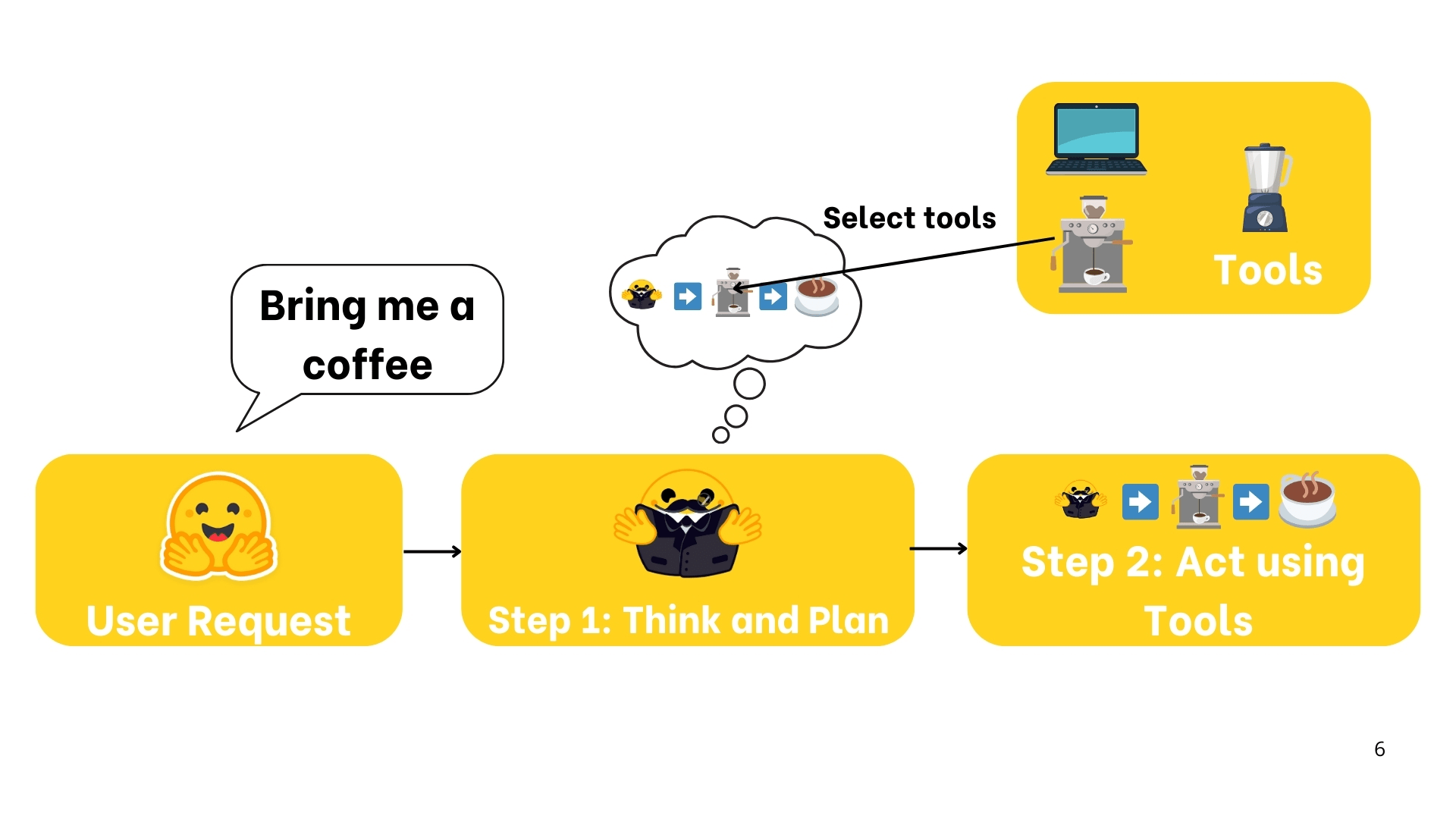
Los LLMs actuan como el cerebro detás de los agentes; interpretan instrucciones de usuarios, mantienen el contexto en las conversaciones, definen un plan y deciden que herramienta usar.
Al entender el Lenguaje Natural, es un sistema que puede:
- Razonar y planificar, logrando determinar los pasos y herramientas que necesitará para conseguir su objetivo.
- Selecciona las herramientas que tiene a su disposición para ejecutar su plan.
- Actua para ejecutar el plan.
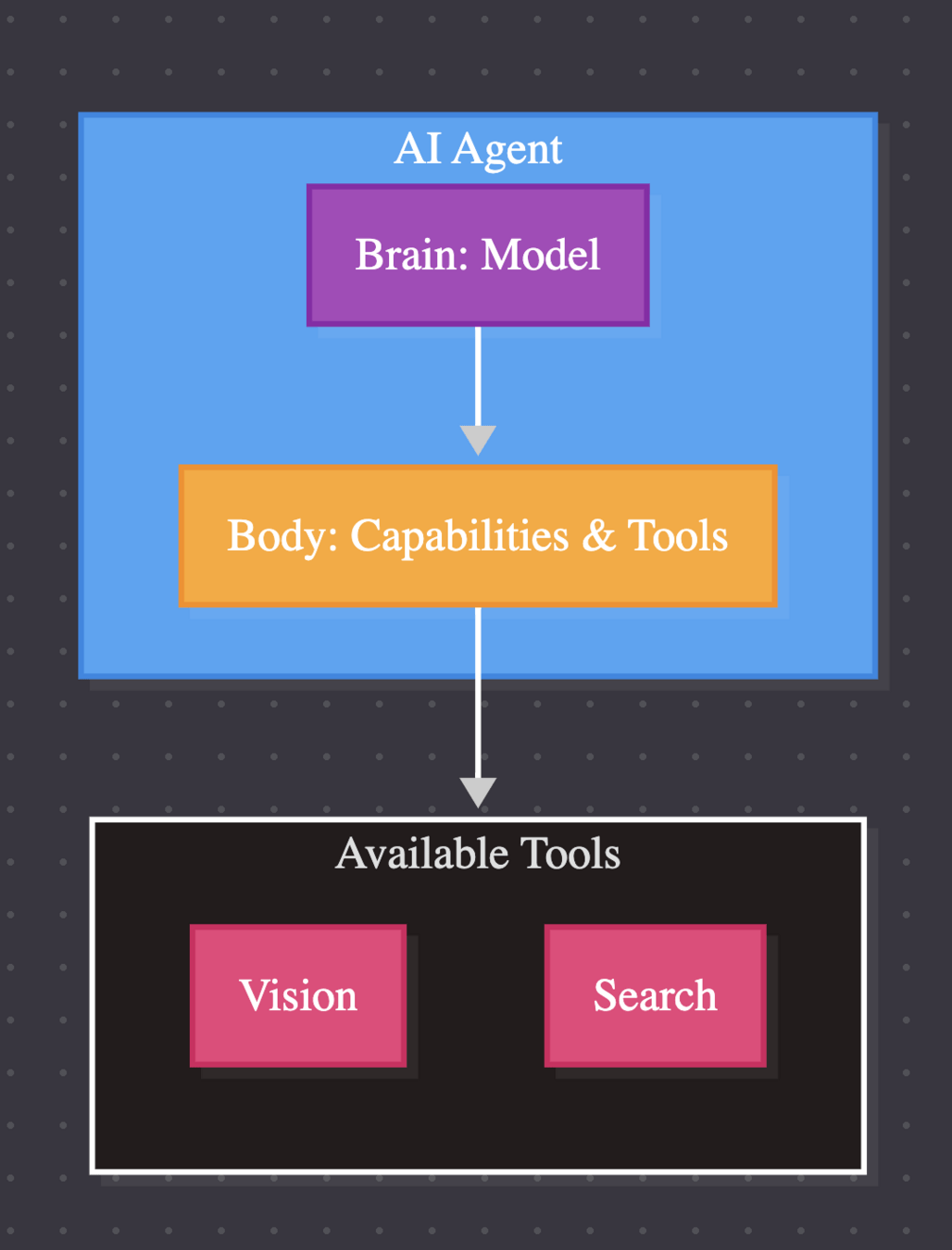
AI model capable of reasoning, planning and interacting with its environment.
An Agent is a system that leverages an AI model to interact with its environment in order to achieve a user-defined objective. It combines reasoning, planning and the execution of actions (often via external tools) to fulfill tasks.
Understand instructions and plan actions
Model; the brain
Tools; the hands
Orchestration layer; the conductor.
Reasoning engine; Manage the context window (semantic filter), curates and prioritizes data inputs, deciding what's important right now and selecting the tool to complete the current step of the cycle
Manage the connection to the outside world or internal systems (code functions, APIs, DBs, vector stores)
Governor of the process; Manage the operational loop (think, act, observe 🔁),
planning (Set a goal, scan the scene, think it through, take action, observe and iterate), keeping track of the memory state and executing the reasoning strategy (Chain of thought, React, etc)
Un agente puede realizar cualquier tarea por medio de herramientas para completar acciones.
El diseño de las tools es muy importante y tiene un gran impacto en la calidad del agente. Tenemos por tanto herramientas:
- Uso general (Web search, etc)
- Específicas (Integraciones de terceros, etc)
Actions are not the same as Tools. An Action, for instance, can involve the use of multiple Tools to complete.
Ayudan a mejorar:
- Atienden consultas
- Analizan el contexto
- Consultan de la DB
- Dan respuestas e Inician acciones
Asistentes Personales
Chatbots
AI Non-Playable Character
- Responder preguntas
- Guiar al usuario (User satisfaction)
- Completar transacciones
- Personajes impredecibles
- Comportamiento basado en interacciones
...
Los Jupyter notebooks son un formato muy popular para compartir código y análisis de datos para el aprendizaje automático y la ciencia de datos. Son documentos interactivos que pueden contener código, visualizaciones y texto. Más detalles aquí
- Dummy Agent Library: https://huggingface.co/agents-course/notebooks/
You need a Hugging Face token to run Notebooks https://hf.co/settings/tokens.
Existen modelos que podemos solicitar acceso como Developers
- Meta Llama Models: https://huggingface.co/meta-llama/Llama-3.2-3B-Instruct
Affiliation: I’m a Software Engineer and I’m requesting access to this model because I’m doing the Hugging Face AI Agents Course as a Developer
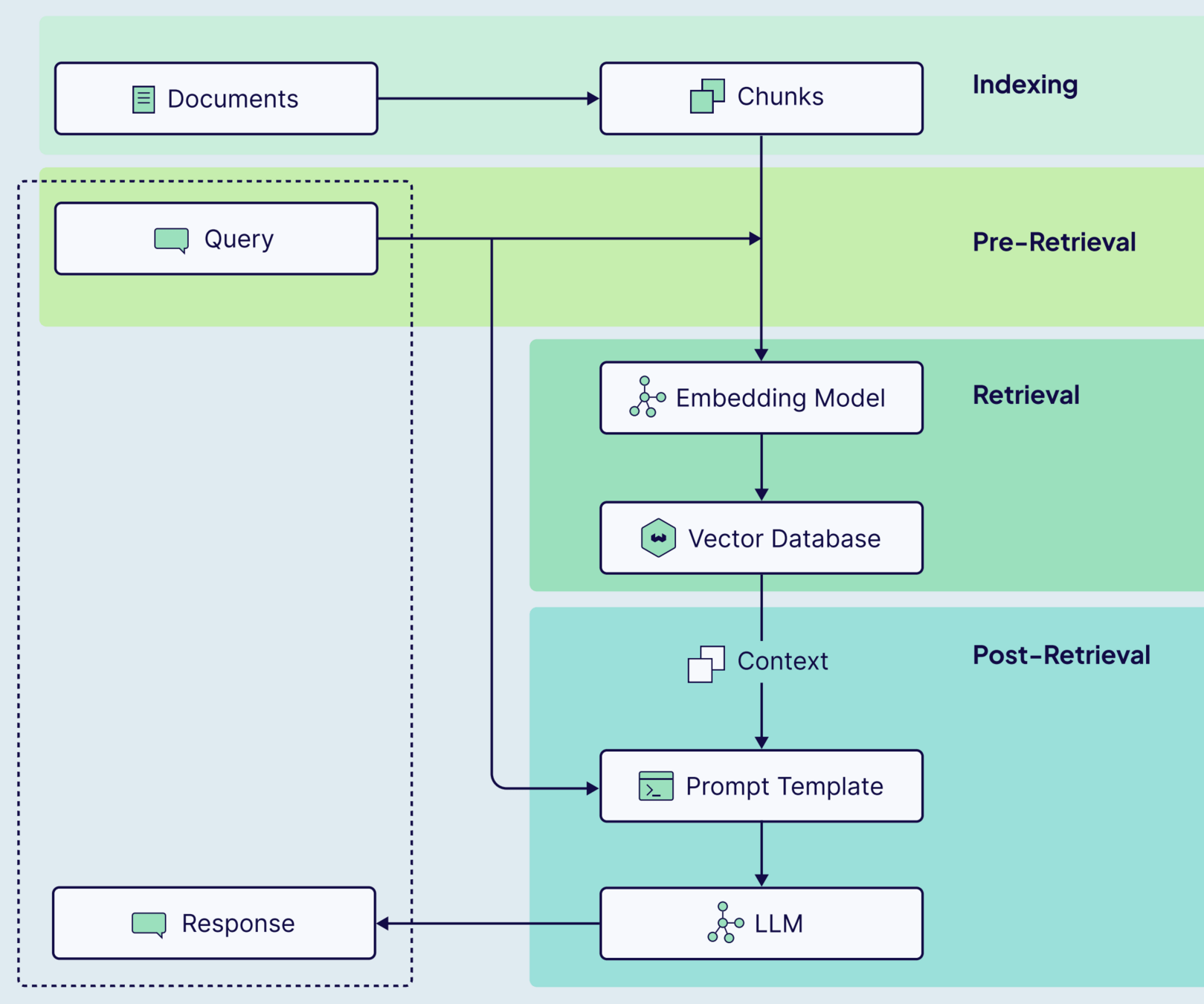
Se refiere a combinar la capacidad de generación con un mecanismo de recuperación.
const openai = new OpenAI();
async function runOpenAI() {
try {
const result = await openai.chat.completions.create({
model: 'gpt-4o-mini',
messages: [
{
role: 'user',
content: 'My prompt is here',
}
]
})
console.log(result.choices[0].message.content)
} catch (error) {
console.error('Error', error)
}
}const genAI = new GoogleGenerativeAI(process.env.GOOGLE_API_KEY);
const model = genAI.getGenerativeModel({
model: 'gemini-1.5-flash'
});
async function runGemini() {
try {
const prompt = "Tell me a fun fact about space.";
const result = await model.generateContent(prompt);
const response = await result.response; // Obtener la respuesta del modelo
const text = response.text(); // Convertir la respuesta en texto
console.log("Gemini Response:", text);
} catch (error) {
console.error('Error:', error);
}
}Framework para desarrollar aplicaciones que implementen LLMs.
AI SDK de Vercel es una librería para crear apps usando LLMs, no cuenta con todas las herramientas de un framework completo, pero la implementación puede ser más sencilla y menos optimizada
Framework para conectar datos estructurados y no estructurados con modelos de lenguaje (LLMs) como GPT, Gemini, Claude, LLaMA, y más. Su propósito es facilitar la integración de modelos de IA con fuentes de datos personalizadas, mejorando las capacidades de respuesta basadas en conocimiento específico.
Framework para construir app con AI agents y flujos de trabajo inteligente.
...
Existen datasets que podemos usar desde esta plataforma por medio de GitHub Codespaces.
- Free GitHub models: https://github.com/marketplace/models
Existen modelos que podemos usar desde esta plataforma por medio de GitHub Codespaces.
- Free GitHub models: https://github.com/marketplace/models
By J.D Nicholls
A talk about AI and Generative AI (GenAI) for Developers




