
































Leonardo Petrini
PhD Student @ Physics of Complex Systems Lab, EPFL Lausanne
Candidate: Leonardo Petrini
Thesis Advisor: Prof. Matthieu Wyart
Physics of Complex Systems Lab
November 17, 2023
(supervised learning)
Example: predict person height based on age.
age
height
(supervised learning)
Example: predict person height based on age.
age
height
train point
prediction
test point
true value
predicted value
Supervised learning aims for accurate predictions on test data
(supervised learning)
Example: predict person height based on age.
age
height
train point
prediction
test point
predicted value
true value
true value
predicted value
Modern supervised learning can handle more complex tasks as recognizing images.
model
"cat"
"dog"
What's in the black box?
model
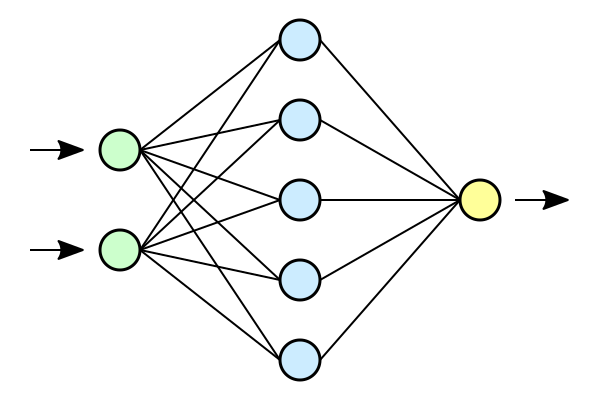
Solving supervised learning tasks with deep neural networks.
depth
neurons
?
input
output
model
CAT
DOG
CAT
DOG
CAT
DOG
CAT
DOG
CAT
DOG
repeat for thousands of images
CAT
DOG
new image
Surprising as this is a complicated task for computers to solve!
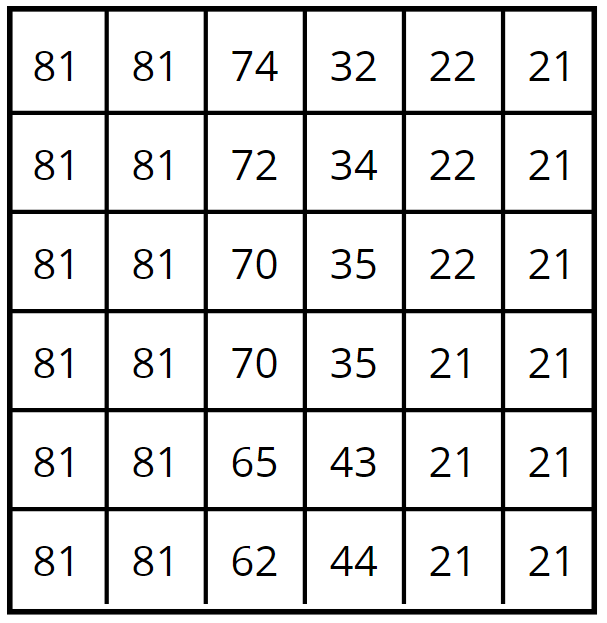
81
81
81
81
81
81
81
81
81
81
81
81
74
72
70
70
65
62
32
34
35
35
43
44
22
22
22
21
21
21
21
21
21
21
21
21
pixel
0 100
One number can be represented on a line
(one dimension)
81
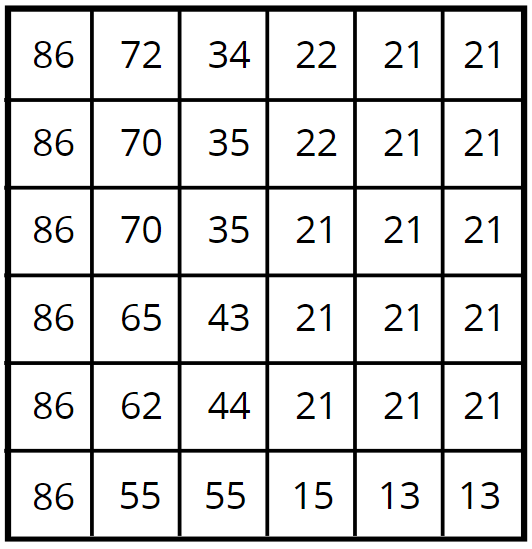
still a dog?
86
86
86
86
86
72
70
70
65
62
34
35
35
43
44
22
22
21
21
21
21
21
21
21
21
86
55
55
15
13
21
21
21
21
21
13
0 100
Two numbers on a square
(two dimensions)
(81, 81)
100
0 100
Three numbers on a cube
(three dimensions)
(81, 81, 74)
100
as the dimensionality increases, images are further and further apart
Step 1: Locate the object
usually pixels at the border do not matter for recognizing the object
Step 2: hierarchically recognize edges \(\rightarrow\) parts \(\rightarrow\) full object
lines \(\rightarrow\) textures \(\rightarrow\) paws, eyes etc. \(\rightarrow\) head etc. \(\rightarrow\) dog
Still a dog, though many things changed
Bottomline: many irrelevant details for solving the task
pixels here can be of different colors without affecting the class
position does not affect the class
Bottomline: many irrelevant details for solving the task
label:
input:
Neural networks perform well as they can learn linear invariance
Bruna and Mallat '13, Mallat '16
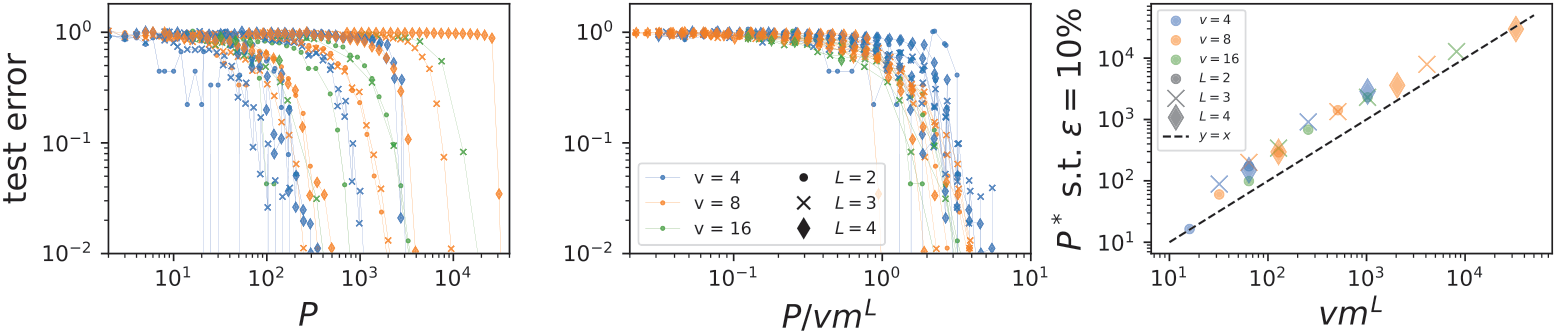
Can we test this hypothesis?
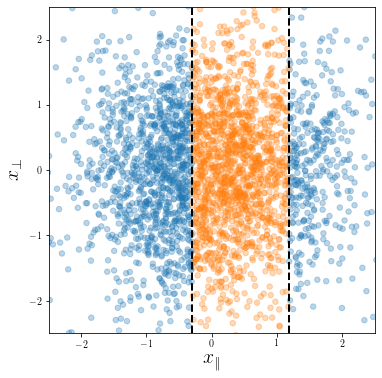
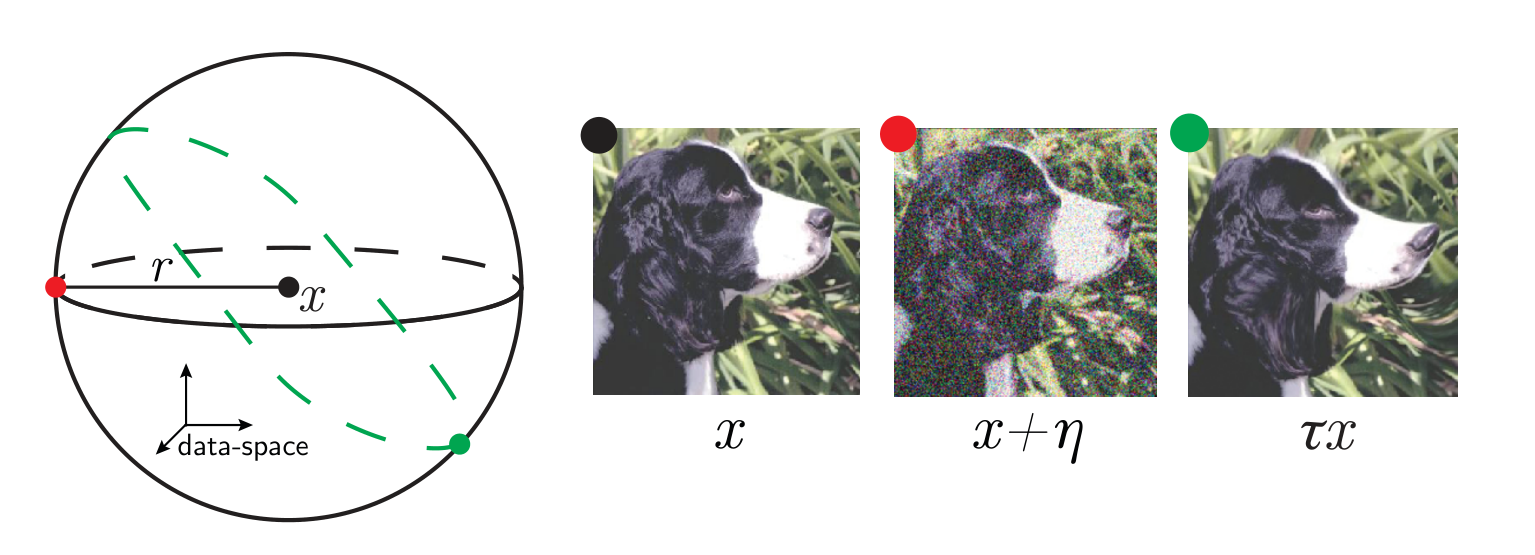
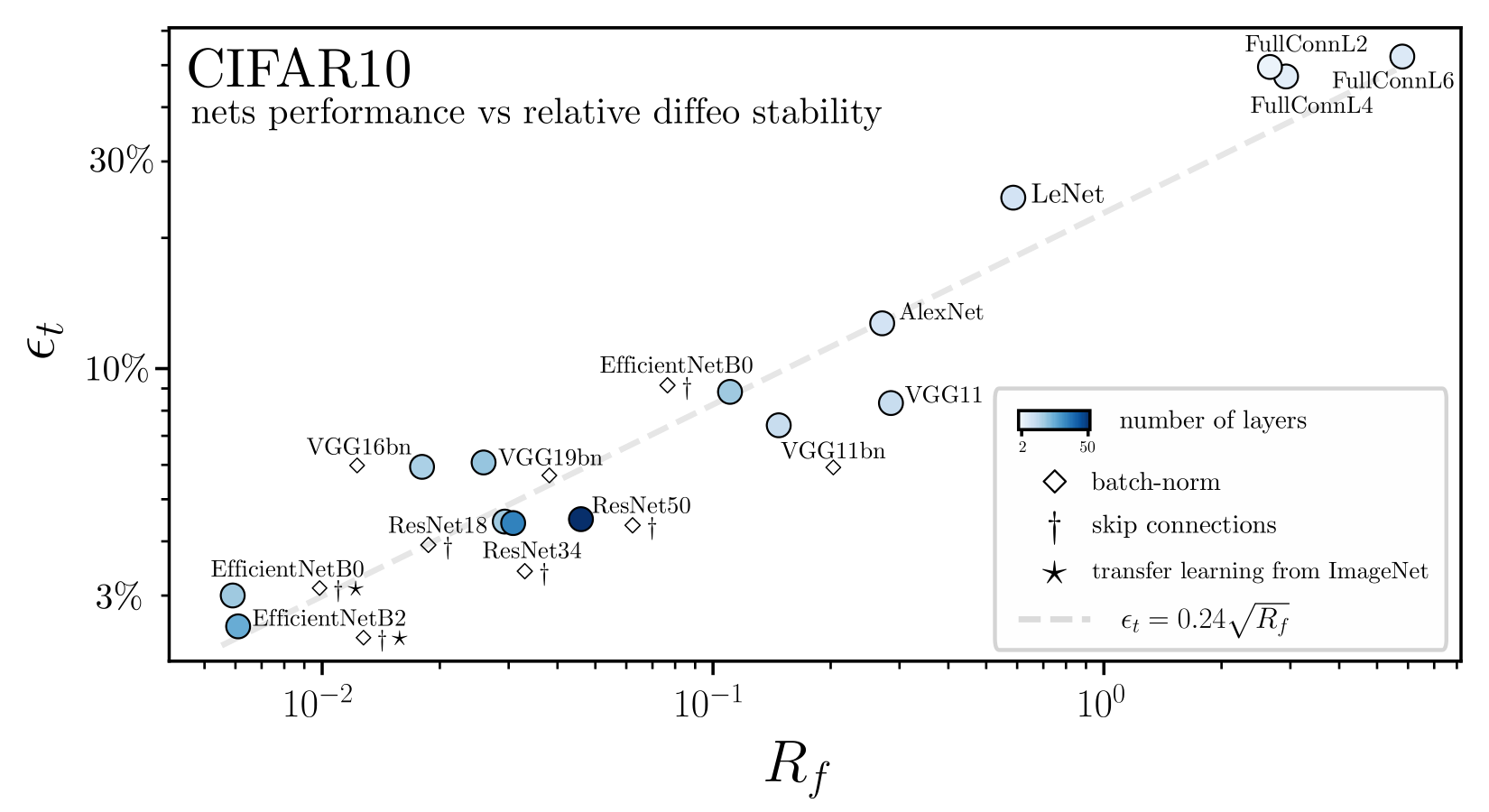
Invariance measure: relative stability
(normalized such that is =1 if no diffeo stability)
we introduced a model to generate deformations of controlled magnitude
more invariant
initialization: \(R_f \sim 1\)
more performant
Suggest that understanding deformation invariance is crucial for solving image classification
...
dog
face
paws
eyes
nose
mouth
ear
edges
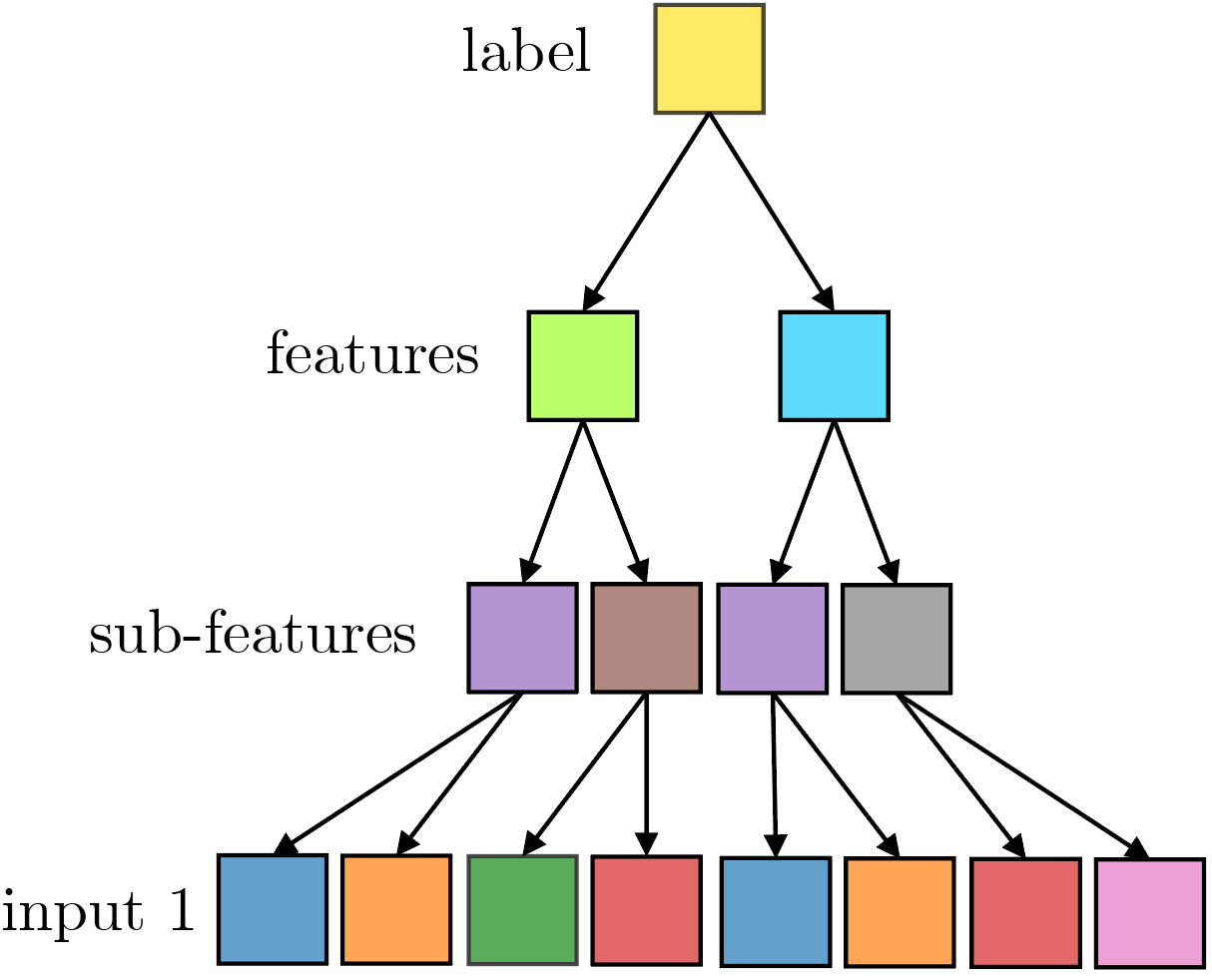
Hard to formally characterize the hierarchical structure in real tasks like images or text:
Physicist approach:
Introduce a simplified model of data
classes:
high-level
features:
etc...
low-level
features:
etc...
synonyms
start from class:
intermediate
representations
inputs
synonyms
original
rescaled \(x-\)axis
number of training points
Invariance to:
"dog"
DL model
Matthieu Wyart, Francesco Cagnetta, Mario Geiger, Alessandro Favero, Umberto Tomasini, Jonas Paccolat, Eric Vanden-Eijden, Kevin Tyloo
Thank you PCSL for these nice years :)
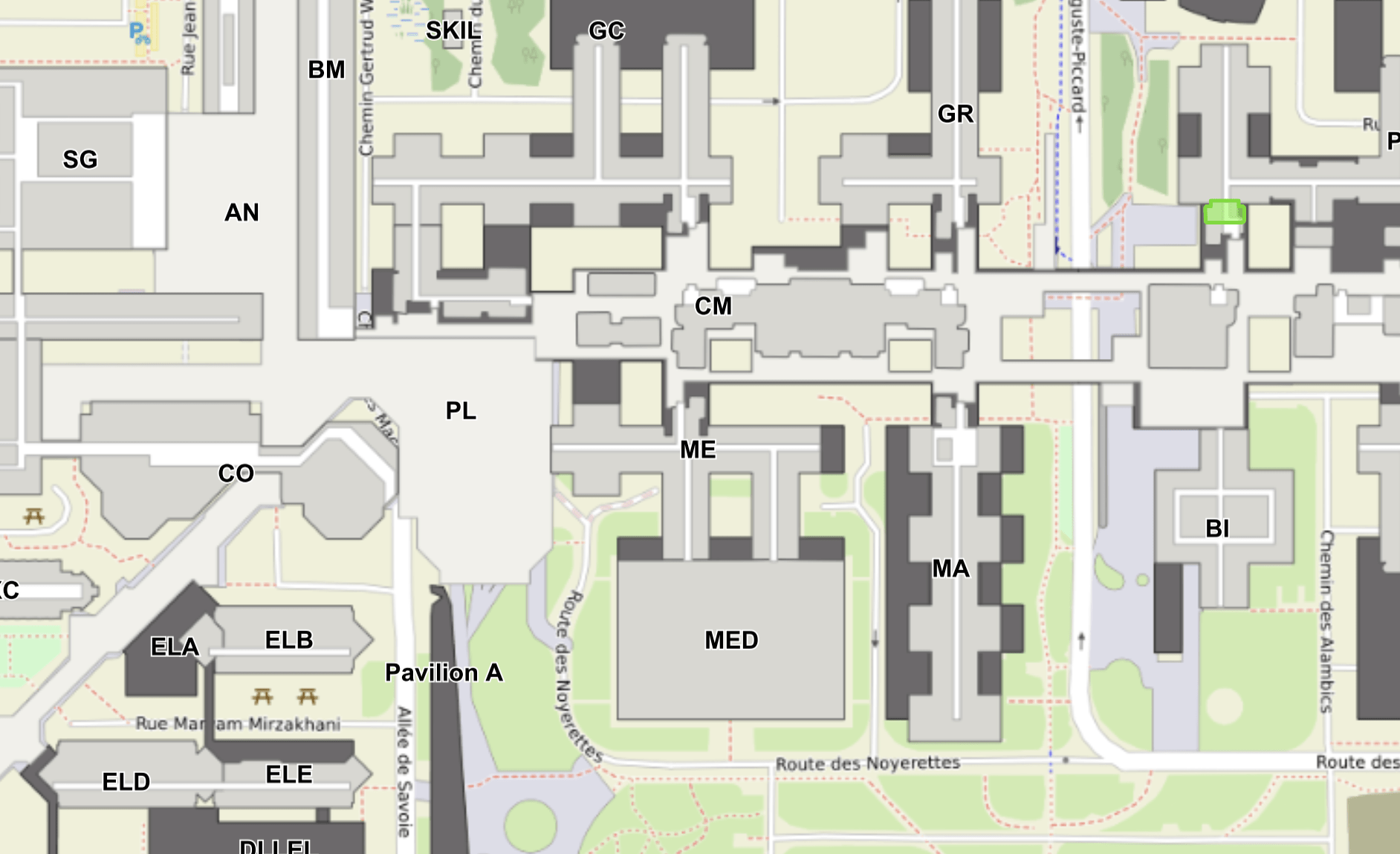
We are here (floor 0)
Apero here
Cafeteria PH
Room A3 364
floor 3
By Leonardo Petrini




