















Leonardo Petrini
PhD Student @ Physics of Complex Systems Lab, EPFL Lausanne
PCSL retreat
Verbier, April 2022
vs.
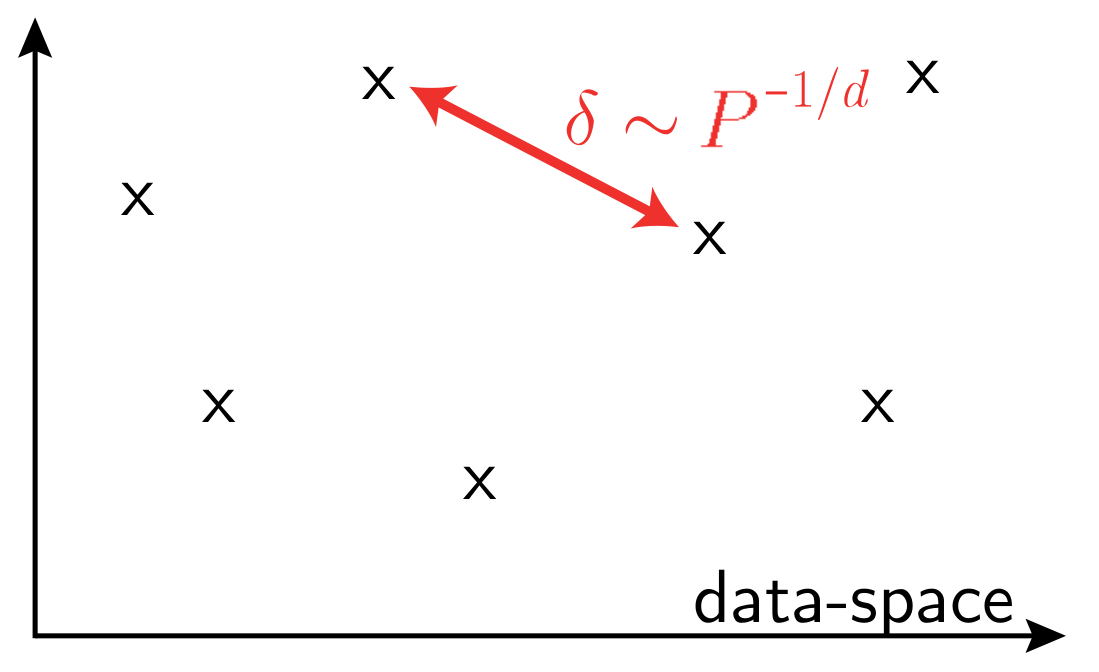
\(P\): training set size
\(d\) data-space dimension
What is the structure of real data?
Cat
\(L=1\)
The volume of the cube is 1, we want to allocate that volume to \(P\) smaller cubes, each containing a data-point.
Each smaller cube will have a volume of \(1/P\) and side length:
$$l = \left( \frac{1}{P}\right)^{1/d}$$
\(l\)
Bruna and Mallat (2013), Mallat (2016), ...
How to characterize such invariance?
\(x-\)translations
\(y-\)translations
(only two degrees of freedom)
= "cat"
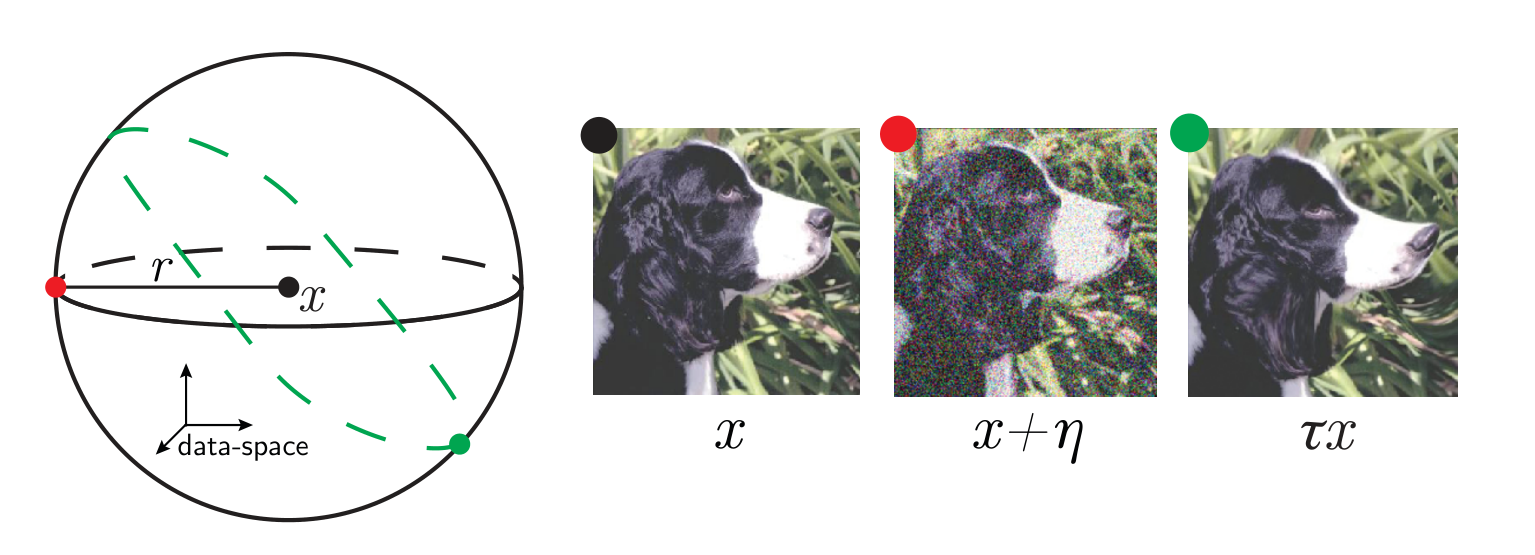
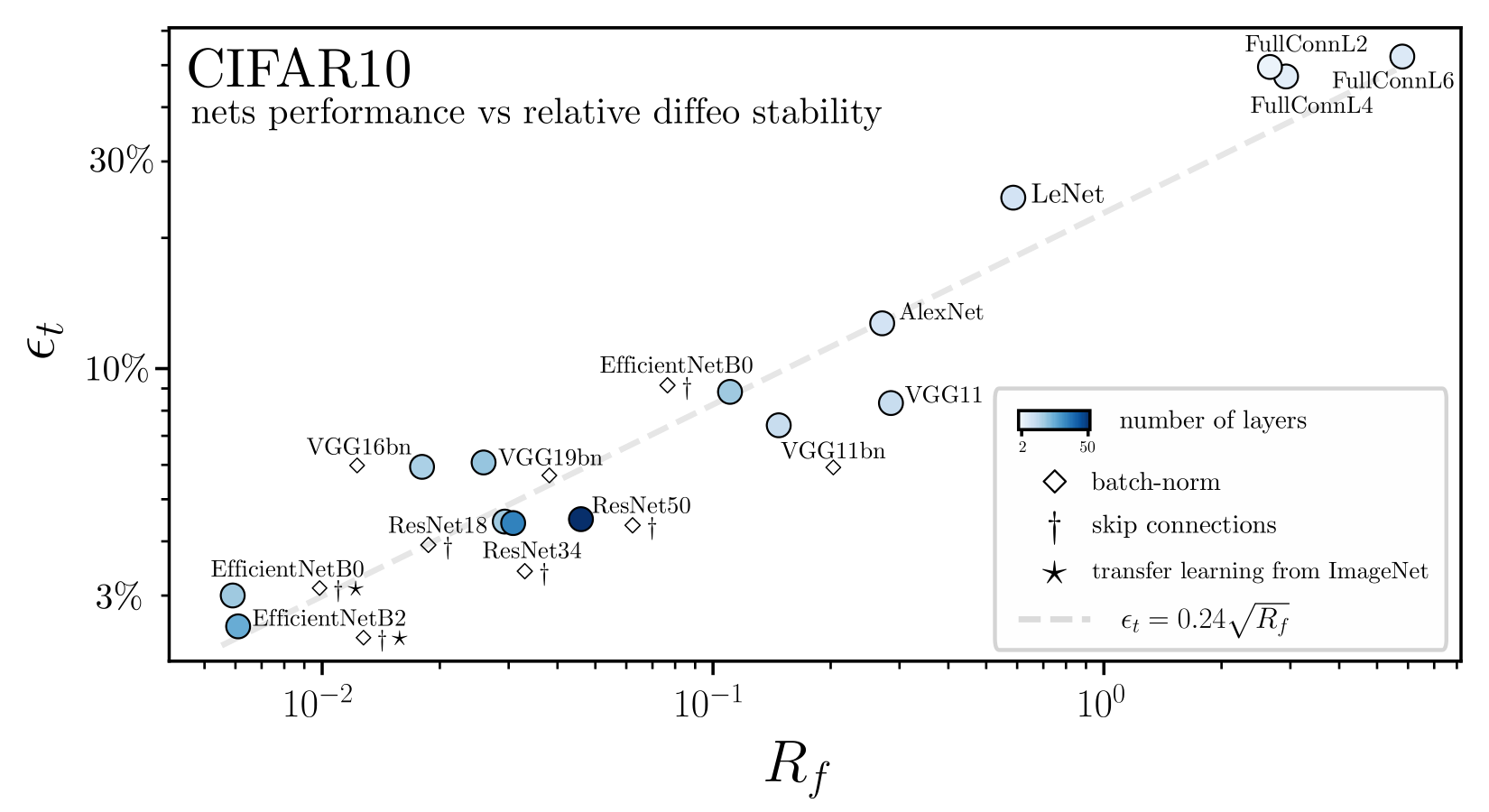
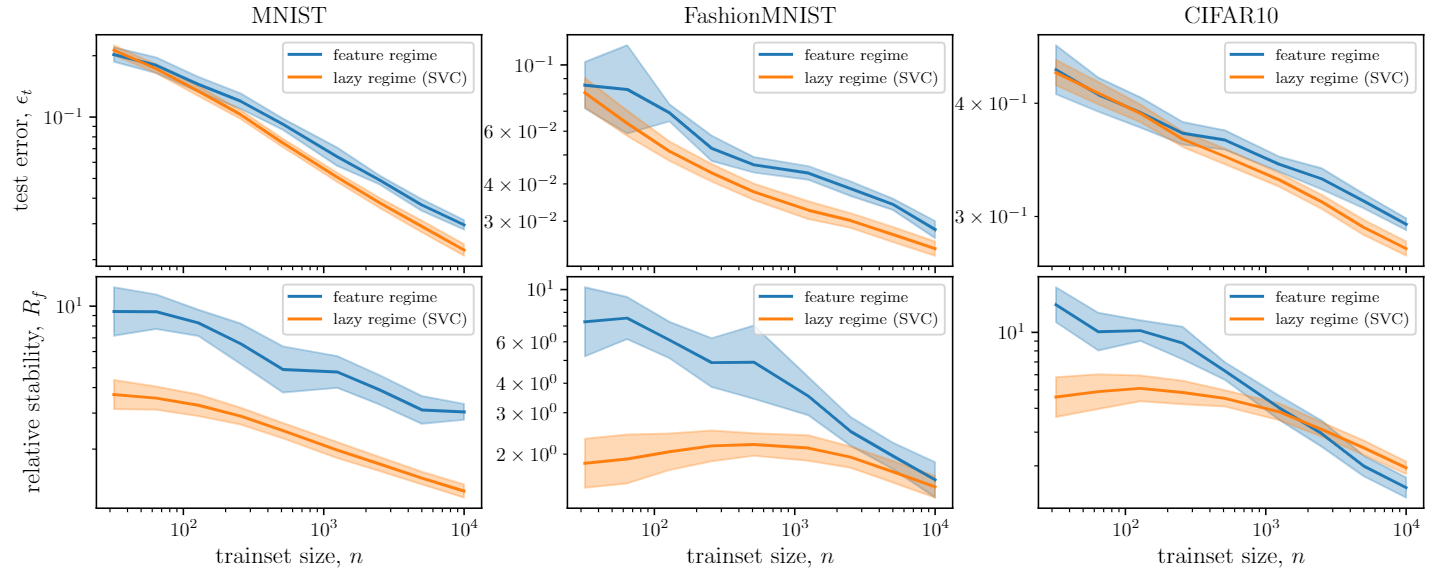
We define the relative stability to diffeomorphisms as
Is this hyp. true?
Can we test it?
\(x\) input image
\(\tau\) smooth deformation
\(\eta\) isotropic noise with \(\|\eta\| = \langle\|\tau x - x\|\rangle\)
\(f\) network function
Goal: quantify how a deep net learns to become less sensitive
to diffeomorphisms than to generic data transformations
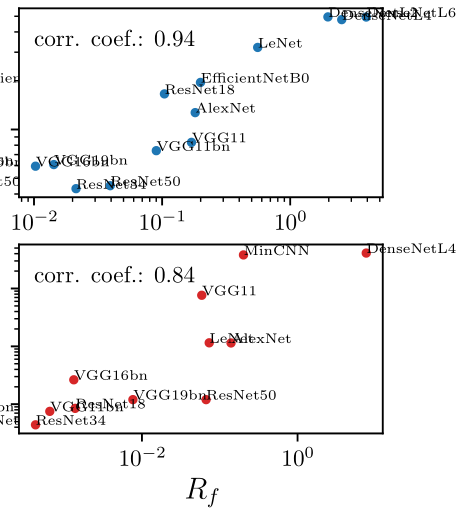
$$R_f = \frac{\langle \|f(\tau x) - f(x)\|^2\rangle_{x, \tau}}{\langle \|f(x + \eta) - f(x)\|^2\rangle_{x, \eta}}$$
Relative stability:
2. How do CNNs build diffeo stability and perform well?
1. How to rationalize this behavior?
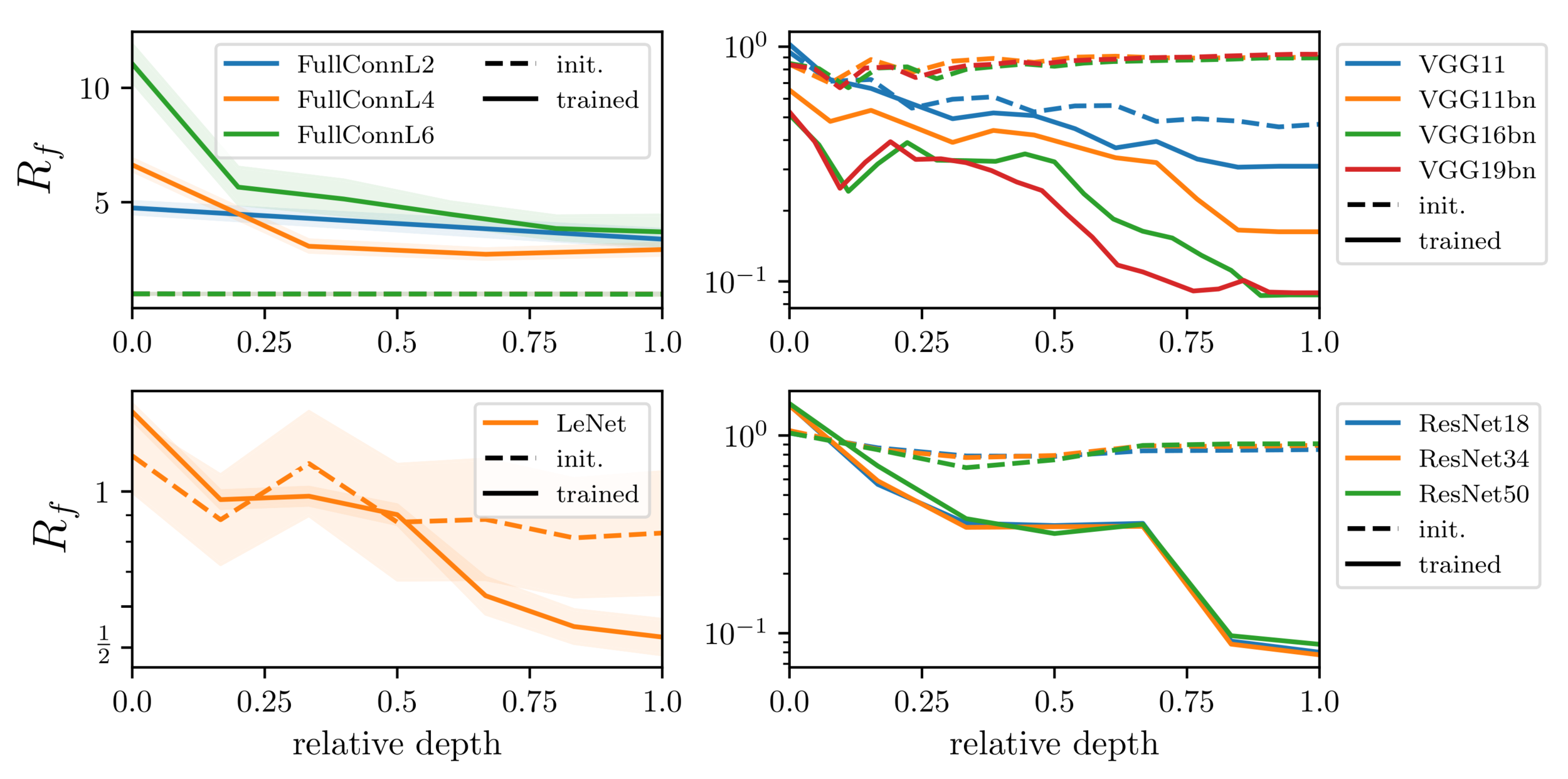
Why FC nets unlearn diffeo stability?
How do CNNs build diffeo stability?
weights \(\mathbf w_h\) before training
after training the
symmetry is preserved
after training the
symmetry is BROKEN
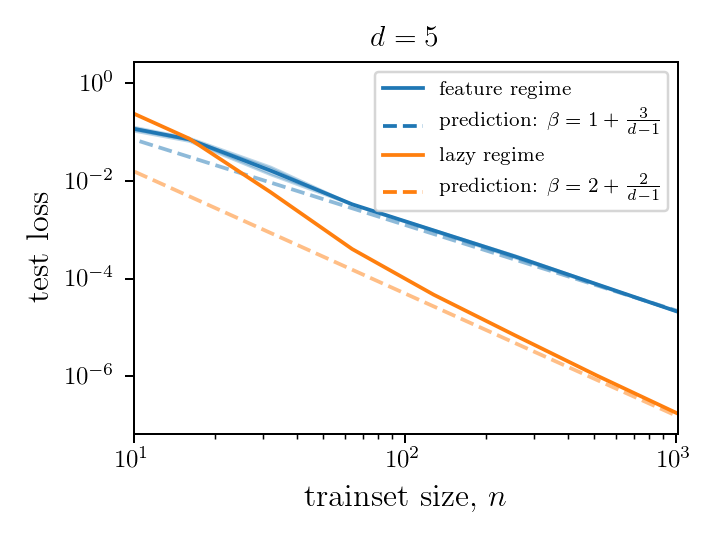
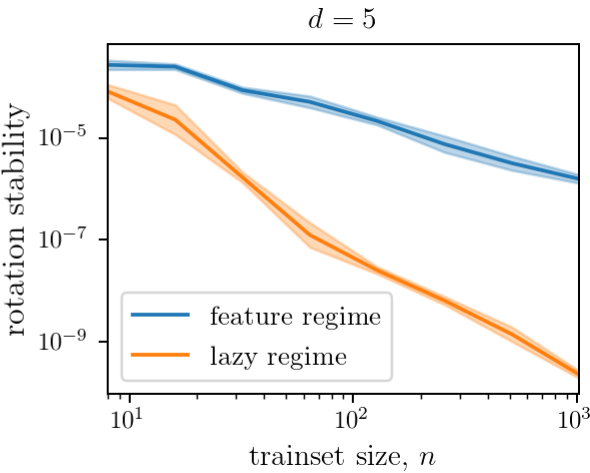
lazy regime
feature regime
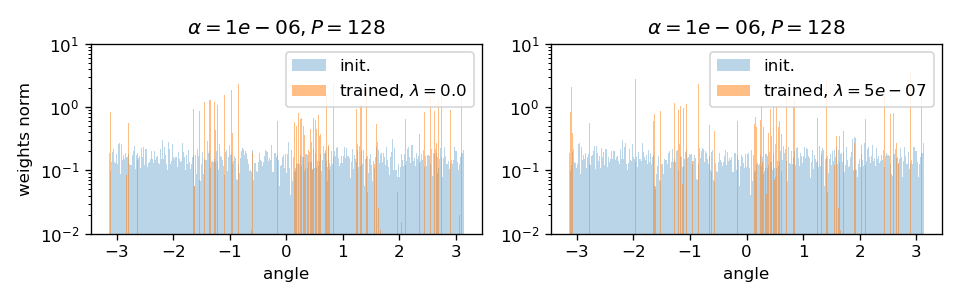
evidence: sparsification
LAZY REGIME
FEATURE REGIME
weights \(\mathbf w_h\) after training
As a result, lazy performs better and is more stable to rotations.
Rotation stability: $$S = \langle \|f(x) - f(R_\theta x)\|^2\rangle_{x, \theta}$$
If we are given a dataset with a spherical symmetry and our model is correctly initialized:
Spherical model
Images
4 neigh. pixels
arrows: deformation
Why FC nets unlearn diffeo stability?
How do CNNs build diffeo stability?
The poor choice of architecture is such that the feature regime breaks the symmetry by overfitting pixels.
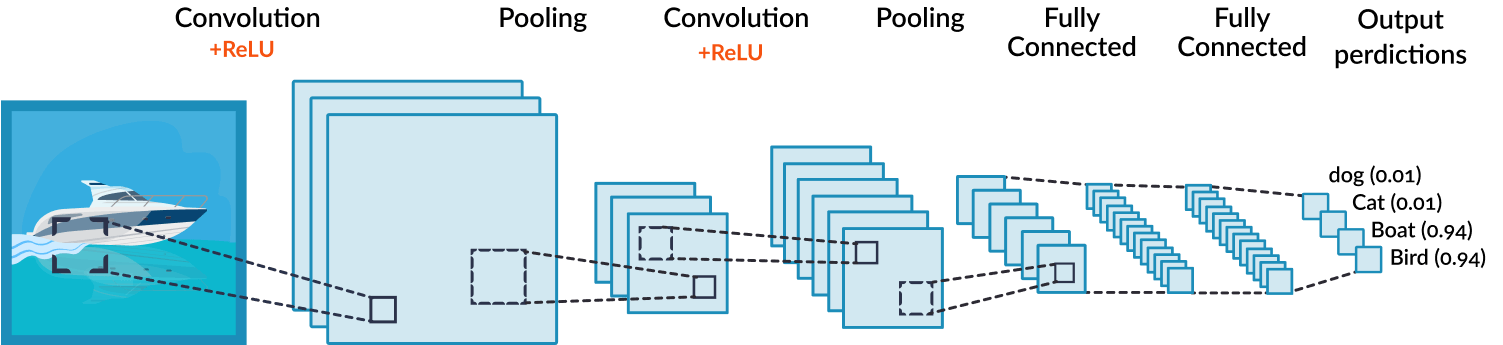
2.
channel 1
channel 2
output (activation map)
input image
a non-linearity is applied here element-wise,
e.g. \(\text{ReLU}(x) = \max(0, x)\)
Stacking together many convolutional layers
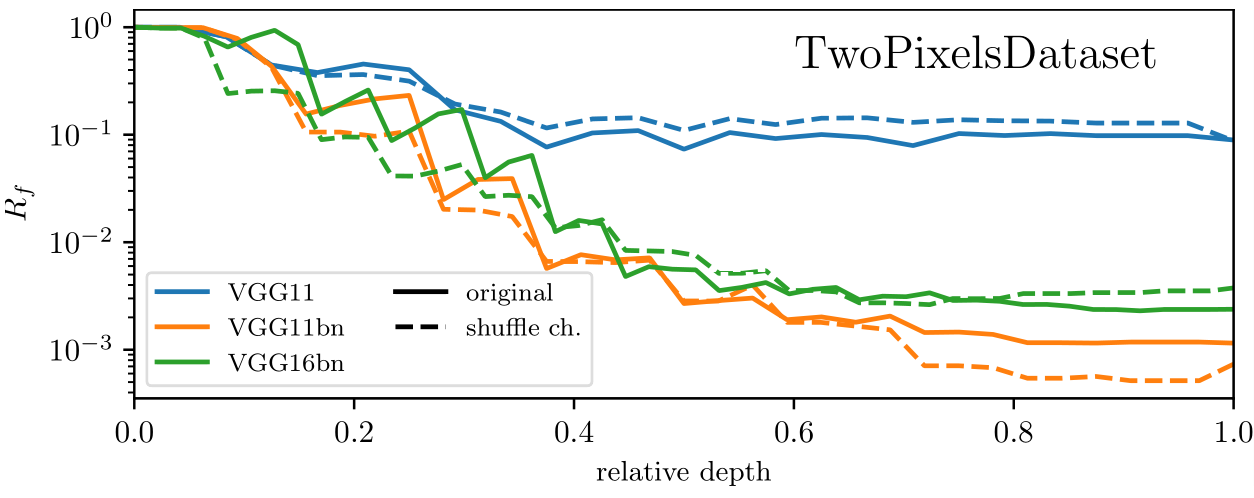
Relative stability to diffeo is achieved layer-by-layer:
Which mechanism(s) can give stability in a layer?
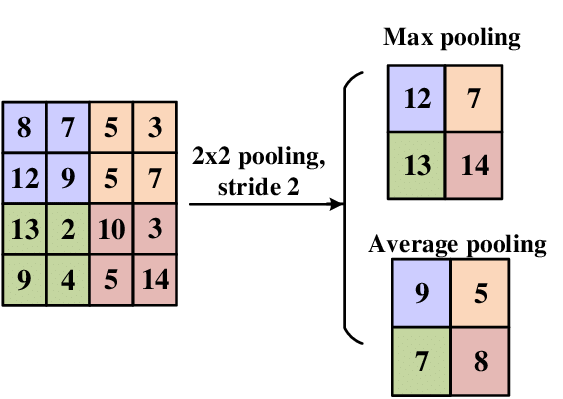
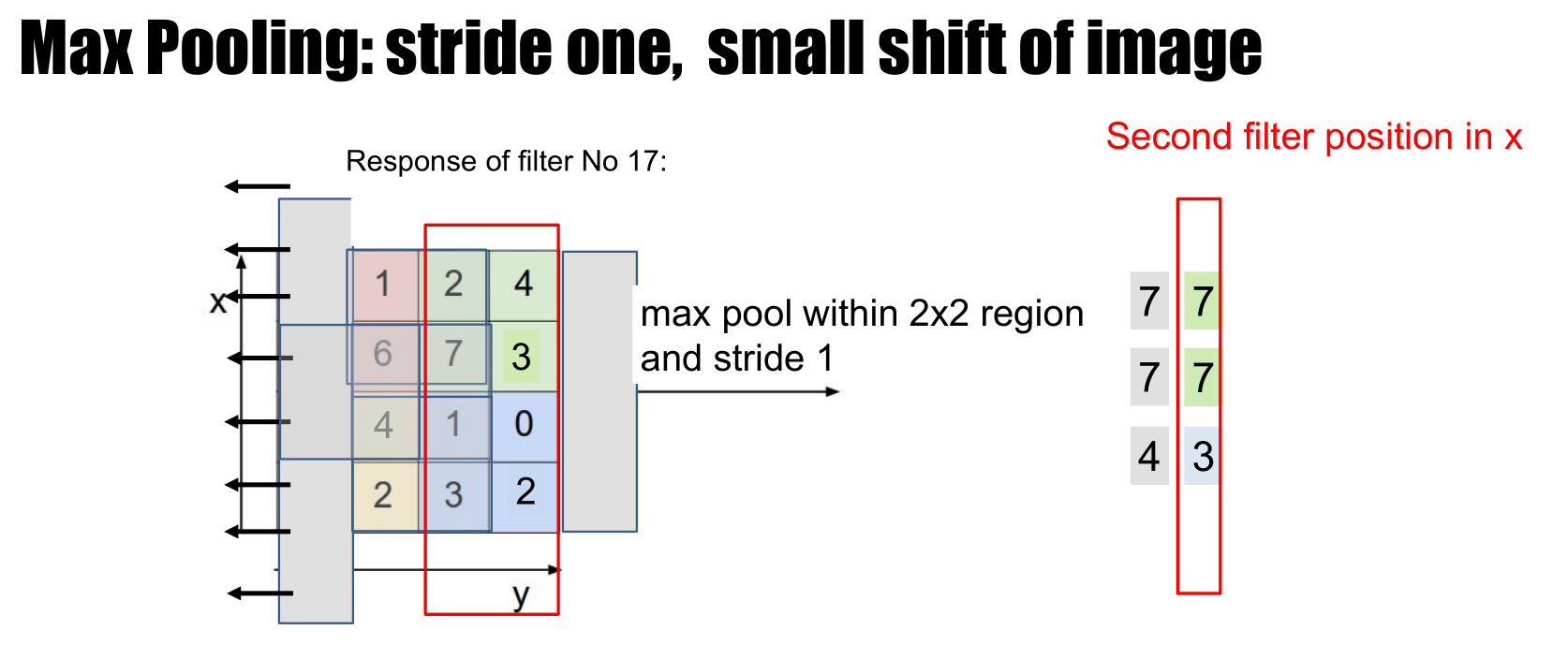
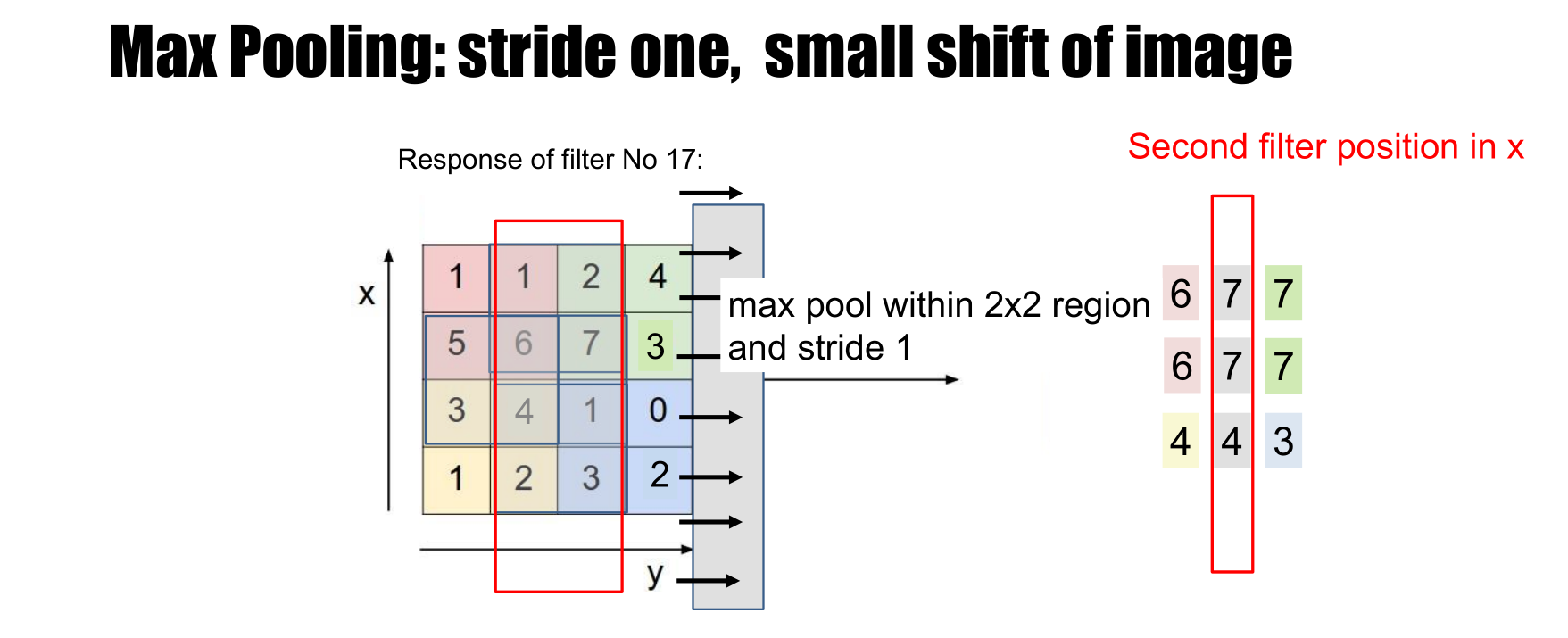
Spatial pooling
Channel pooling
Average pooling can be learned by making filters low pass
Channel pooling can be learned by properly coupling filters together
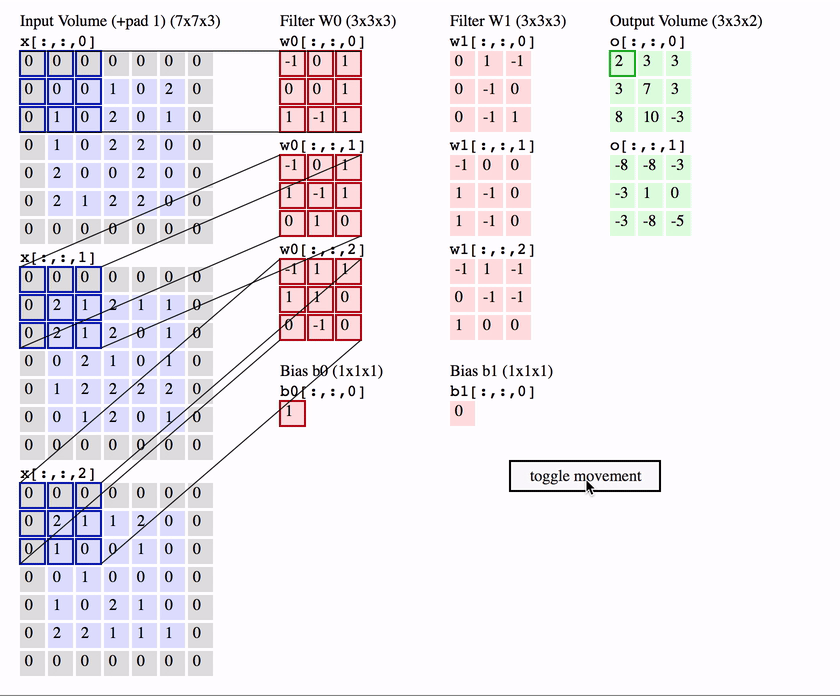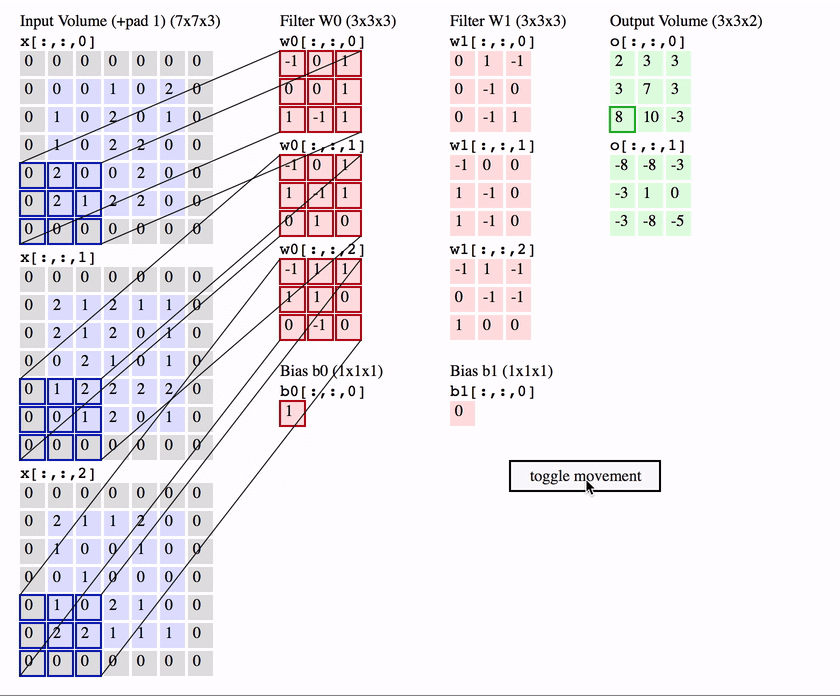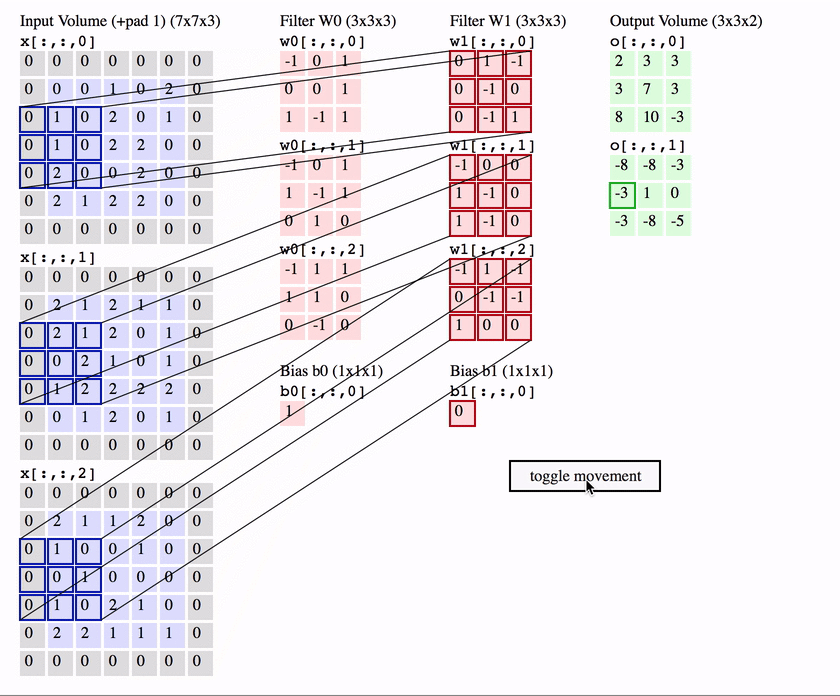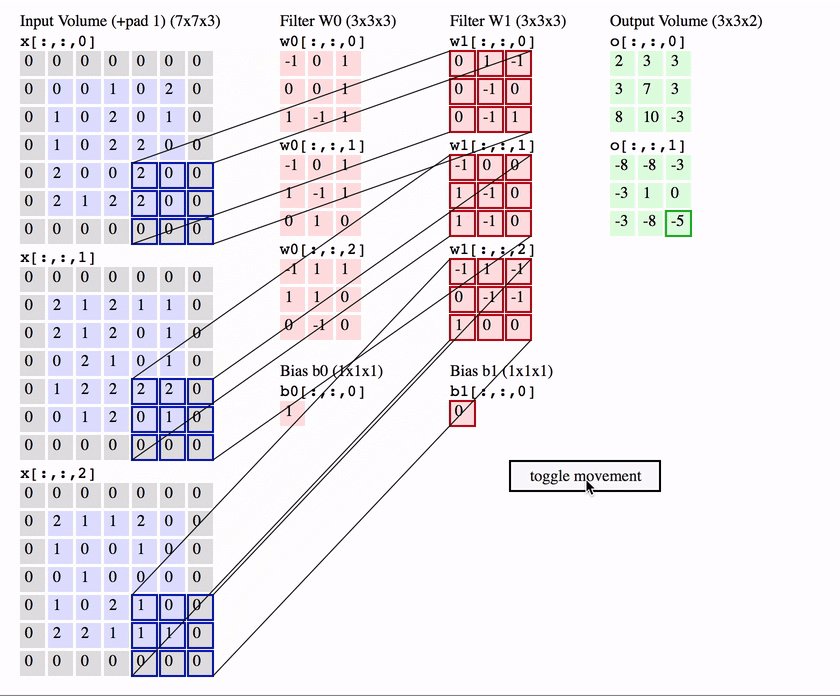
\(w\cdot x=\)
\(1.0\)
0.2
filters \(w\)
1
input \(x\)
0.2
\(1.0\)
1
rotated input
1
filters \(w\)
input \(x\)
\(w\cdot x=\)
\(1.0\)
0.2
1
\(1.0\)
0.2
rotated input
1
filters \(w\)
input \(x\)
\(w\cdot x=\)
\(1.0\)
0.2
0.1
1
\(1.0\)
0.2
0.1
rotated input
Which one gives the observed relative stability in DNNs?
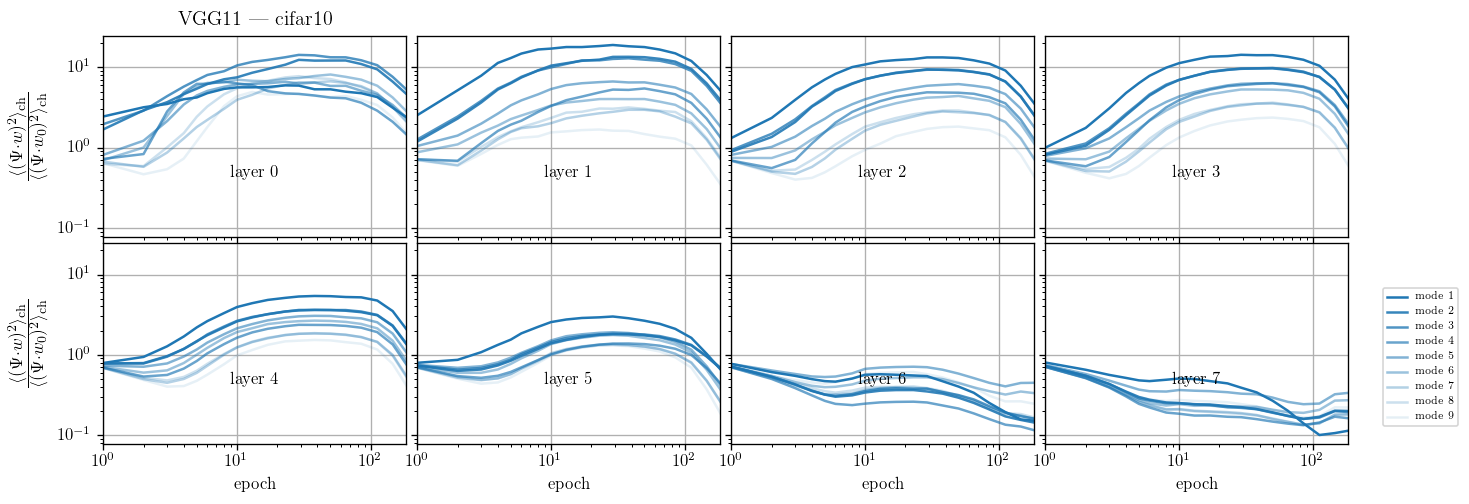
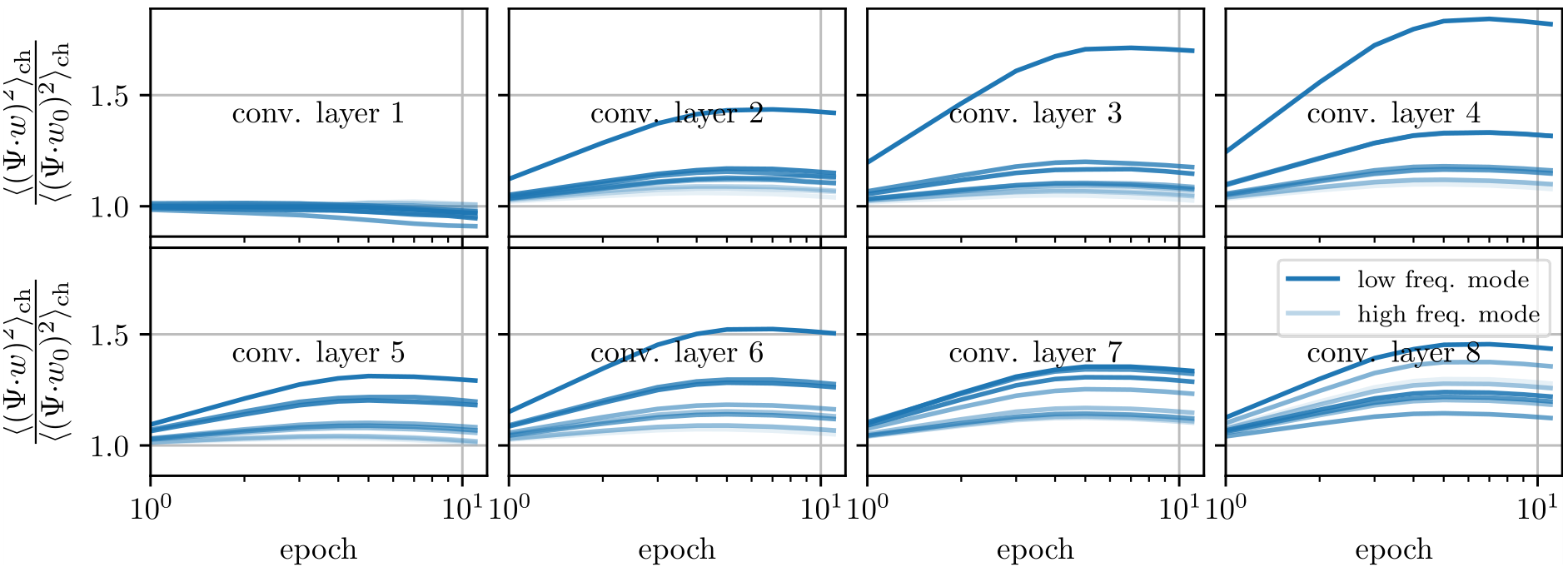
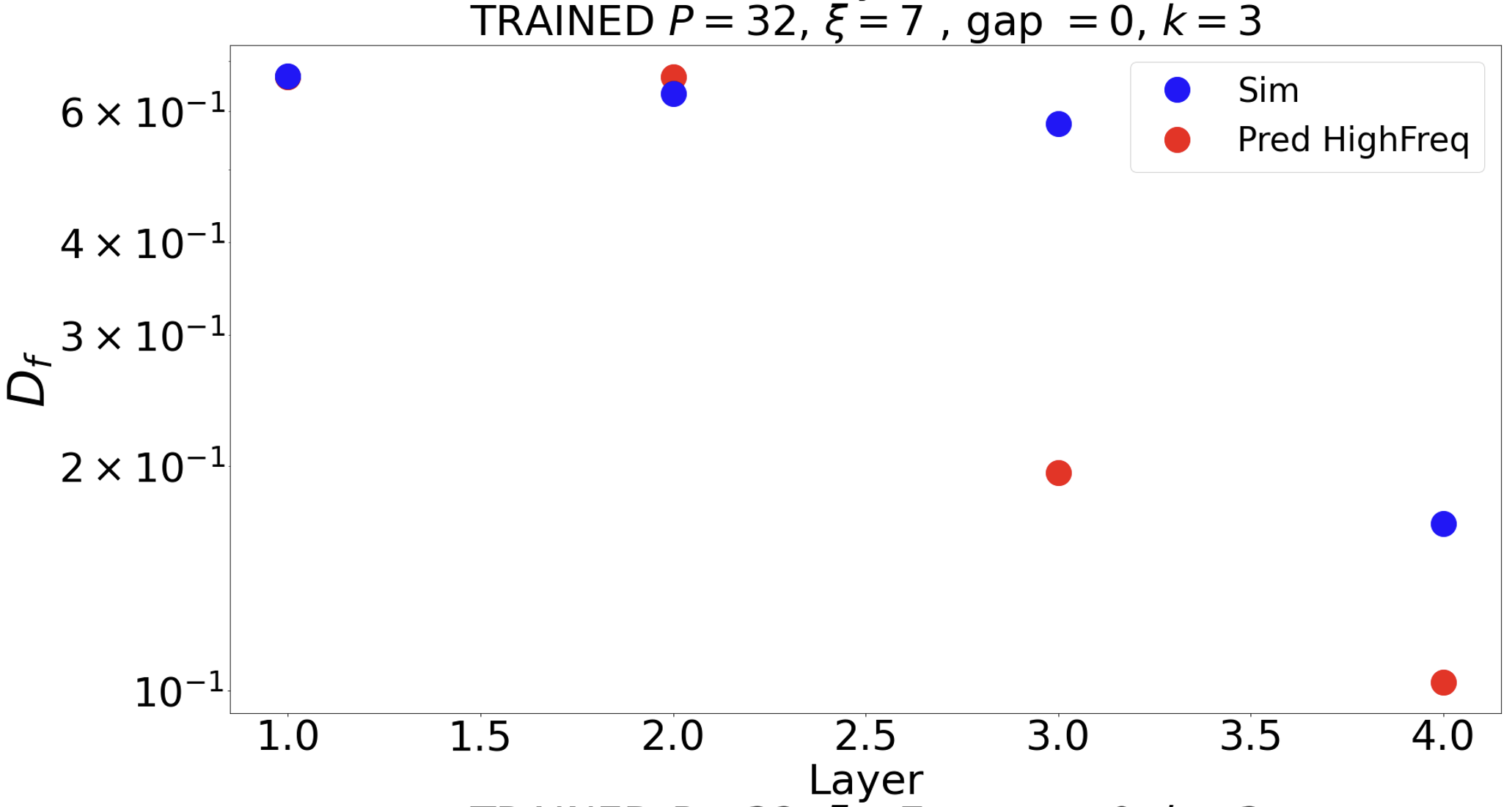
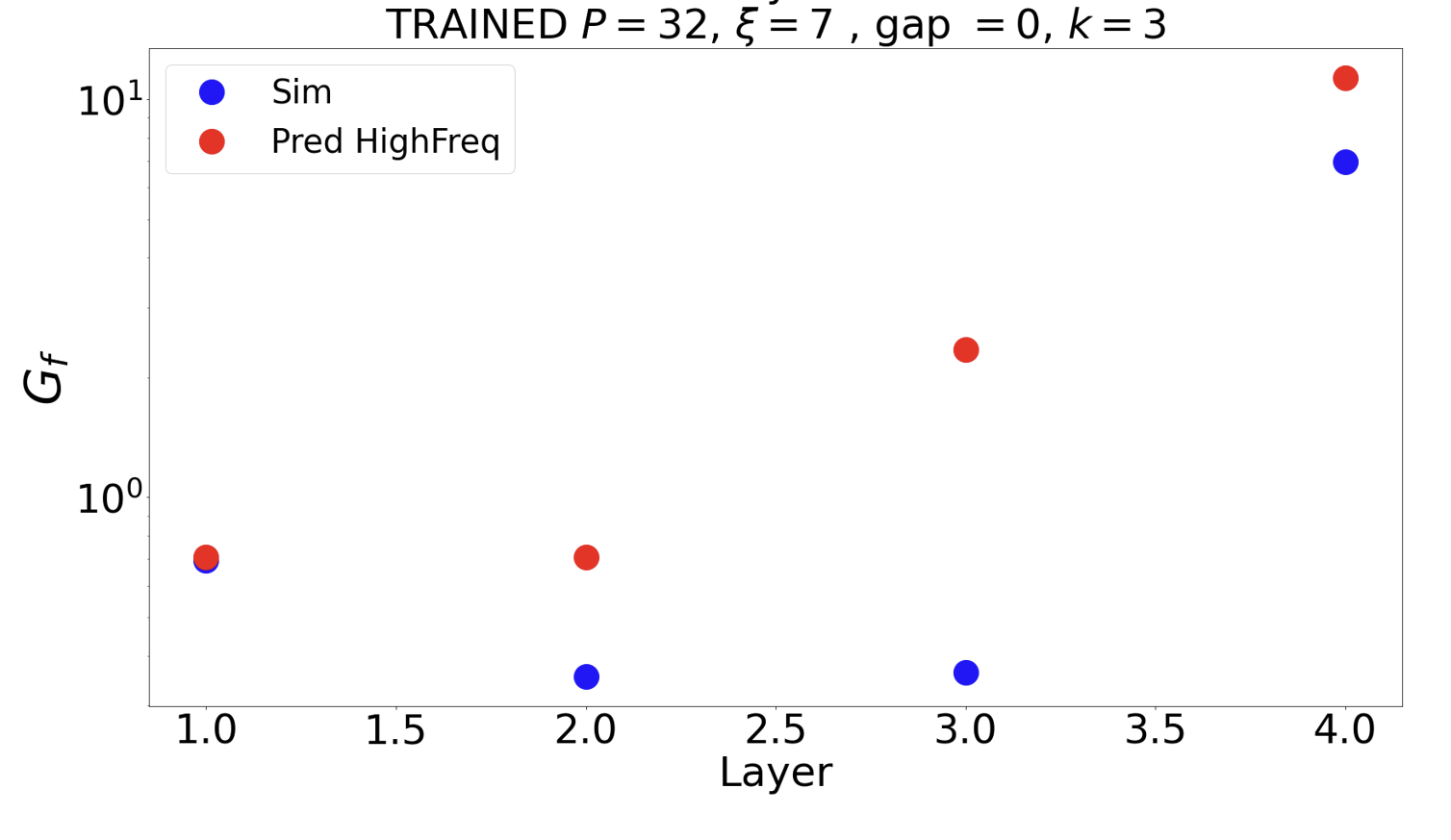
We take a basis that is the eigenvectors of the Laplacian on the 3x3 grid and follow weigths evolution on each of the components and average over the channels:
$$c_{t, \lambda} = \langle (w_{\rm{ch}, t} \cdot \Psi_\lambda )^2\rangle_{\rm{ch}}$$
we plot $$\frac{c_{t, \lambda}}{c_{t=0, \lambda}}$$
Weights become low-pass with training
+
0
-
Filters actually learn to pool!
Goal: build a data model in which learning to do filter pooling is needed to learn the task
image frame (e.g. 32x32 pixels)
Euclidean distance, \(\delta_\mu\)
$$y_\mu = \text{sign} (\xi - \delta_\mu)$$
A network needs to learn to pool at the good length-scale \(\xi\) to generalize
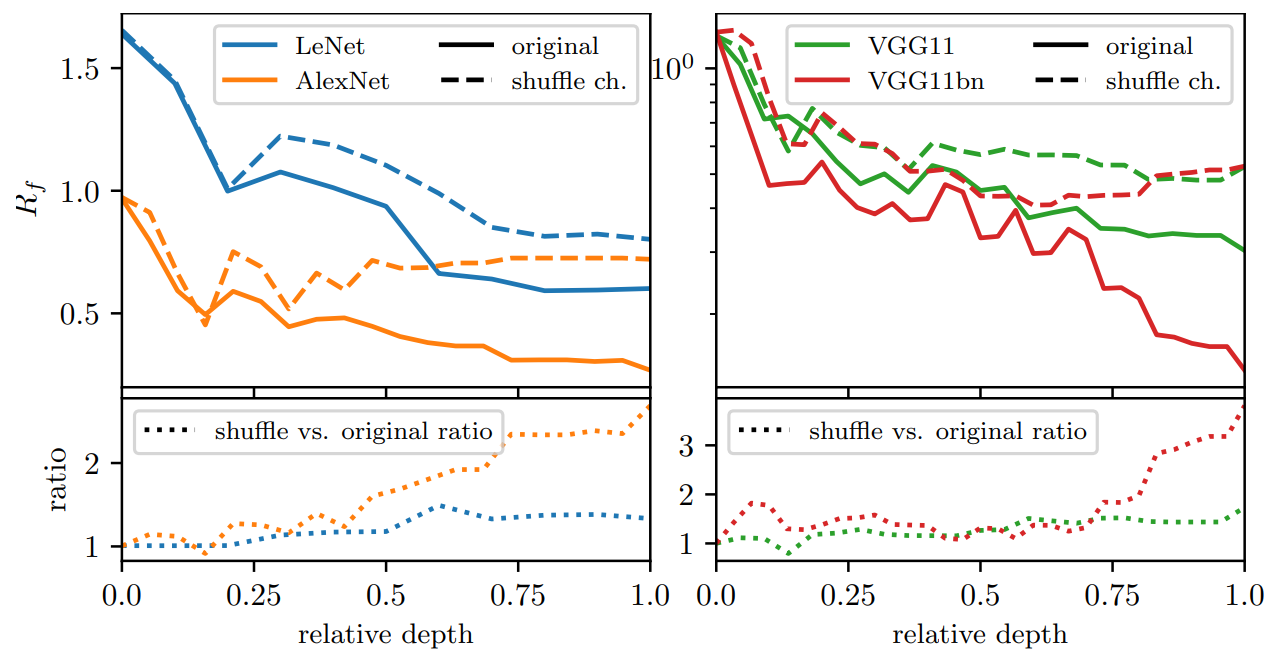
As expected, channel pooling is not present (i.e. shuffling channels has no effect in terms of relative stability).
Why FC nets unlearn diffeo stability?
How do CNNs build diffeo stability?
The poor choice of architecture is such that the feature regime breaks the symmetry by overfitting pixels.
Input
Channel 1
Channel H
Channel 1
Channel H
L hidden layers
Channel 1
Channel H
Global Average Pooling of each channel:
to enforce translational invariance within it
Output \(f_p\)
Layer 1
Input
All filters like that, zero bias
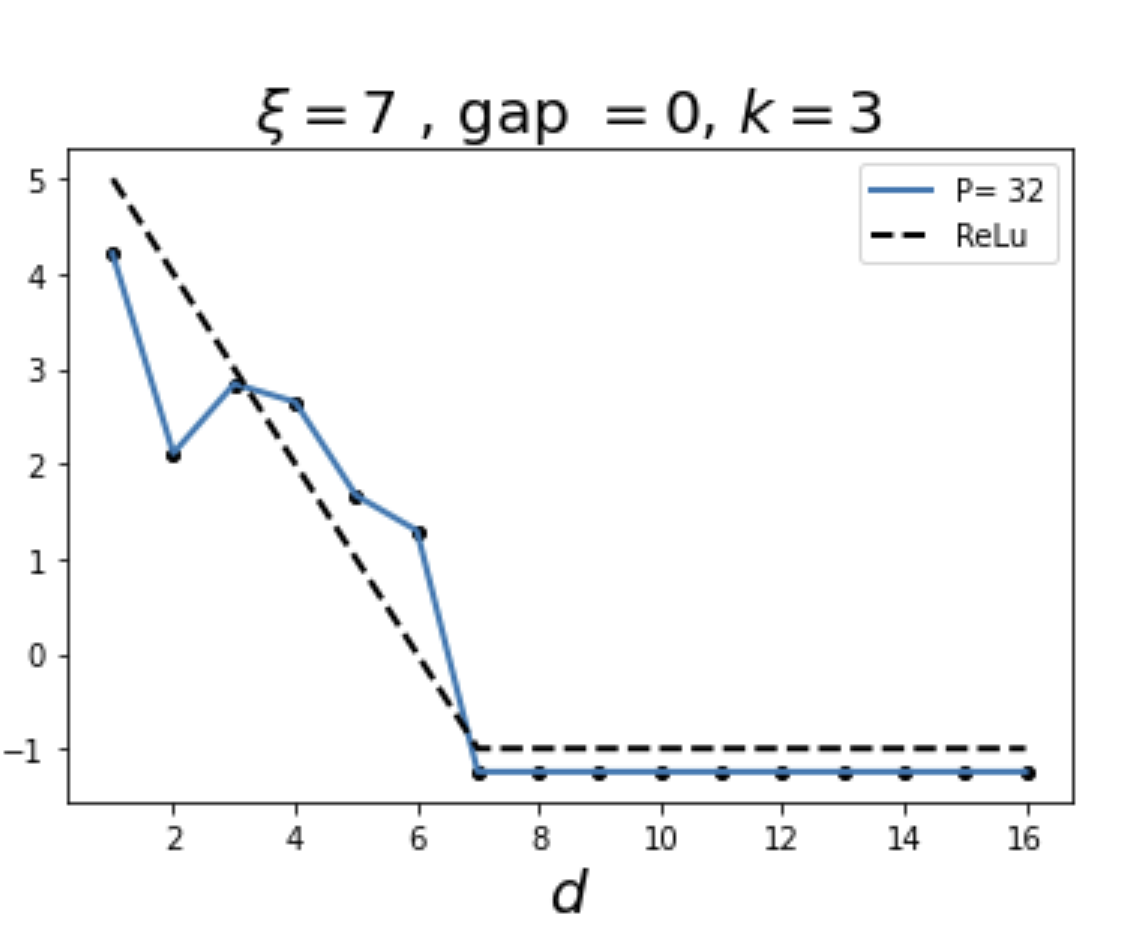
We choose \(\xi =7\) and filter size \(s = 3\)
At layer \(k\), the receptive field of a single neuron is \((2k+1)\): given \(\xi=7\), the layer \(\tilde{k}\) where the scale can be seen is at \(\tilde{k}=3\)
For layers \(k<\tilde{k}\): as above.
Layer \(\tilde{k}\)
-1 bias
Sign of positive interference!
Output: \(f_p(x)=f_p(d)=\text{ReLu}(\xi-d)\)
-1
Input
Layer 1,
3 channels
Layer \(\tilde{k}\)
-1 bias
Sign of positive interference!
Output: \(f_p(x)=f_p(d)=\text{ReLu}(\xi-d)\)
-1
What does a diffeo \(\tau\) do here?
Prob 1/3
Prob 1/3
Prob 1/3
Goal:
compute stability to diffeo for the output and internal layer representation
What does adding noise \(\eta\) do here?
Goal:
compute stability to noise for the output and internal layer representation
where \(\eta_i\) are \(l\) indipendent and identically distributed gaussian noises with mean 0 and standard deviation \(\sigma\) such that:
By Leonardo Petrini




