Philo van Kemenade
Creating tools, stories and things in between to amplify human connection with arts and culture.
Structured in databases
Extracting data from a web page’s source
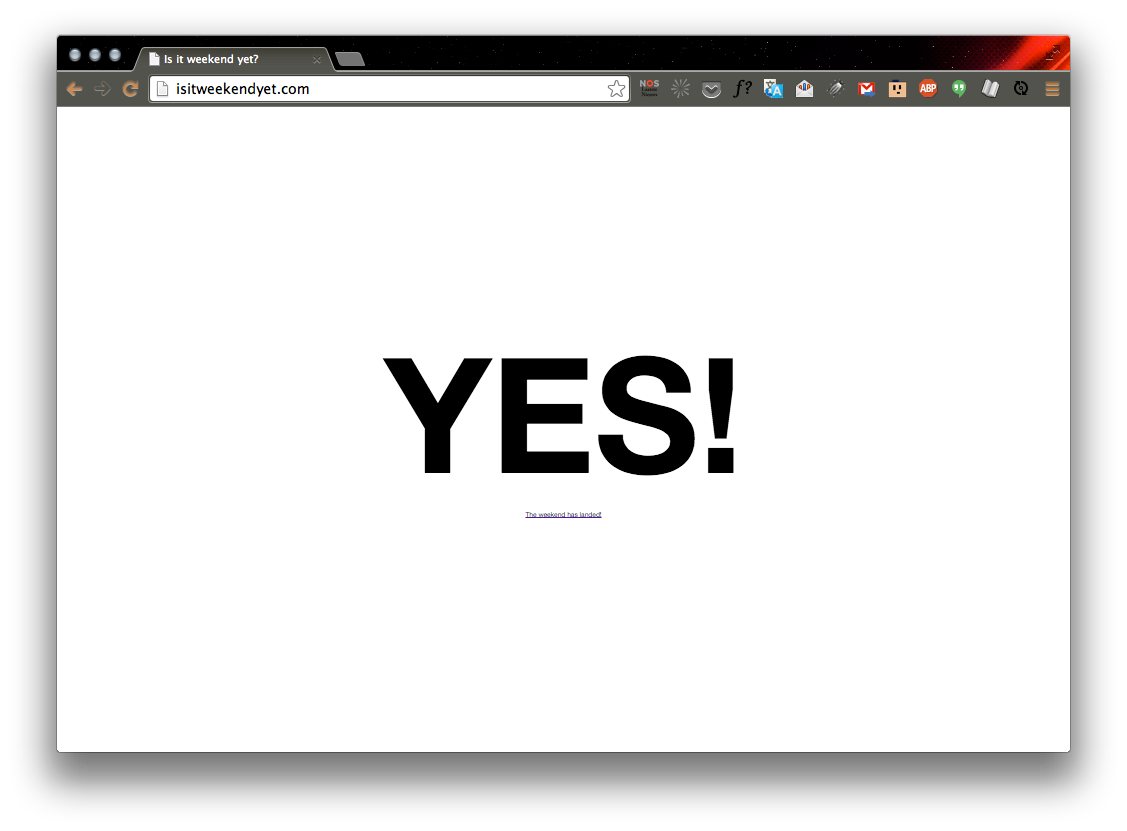
For example: http://isitweekendyet.com/
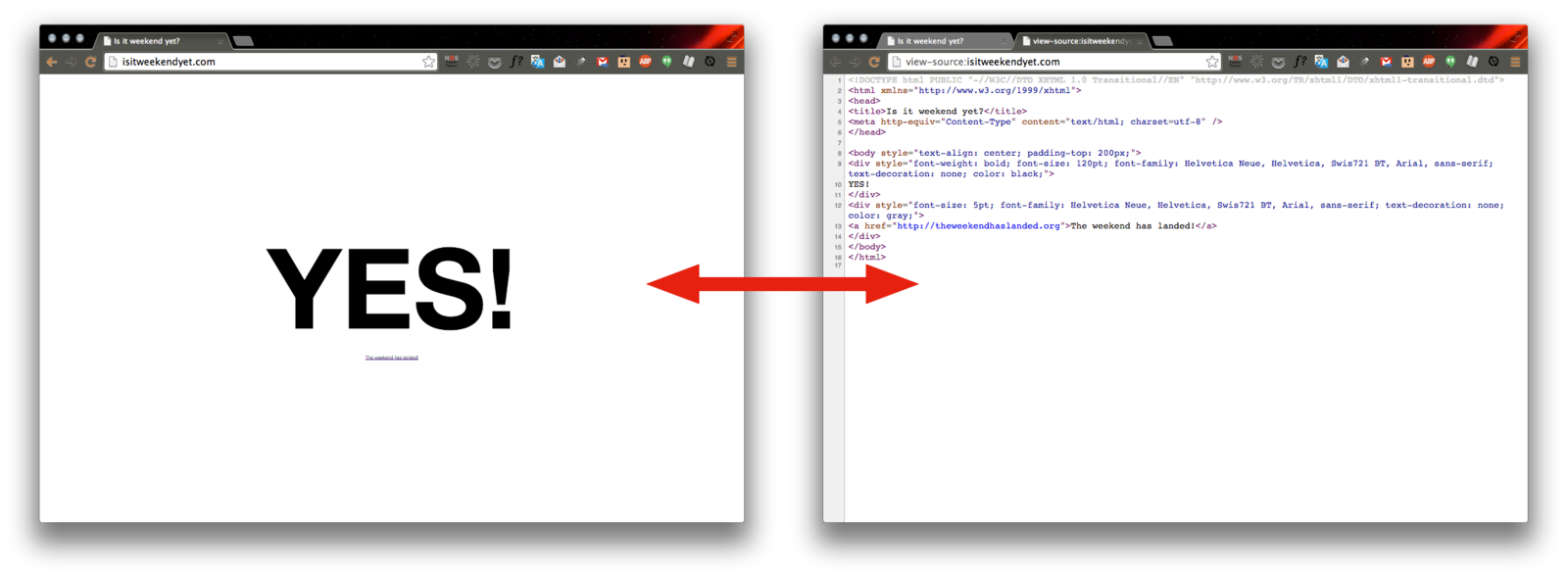

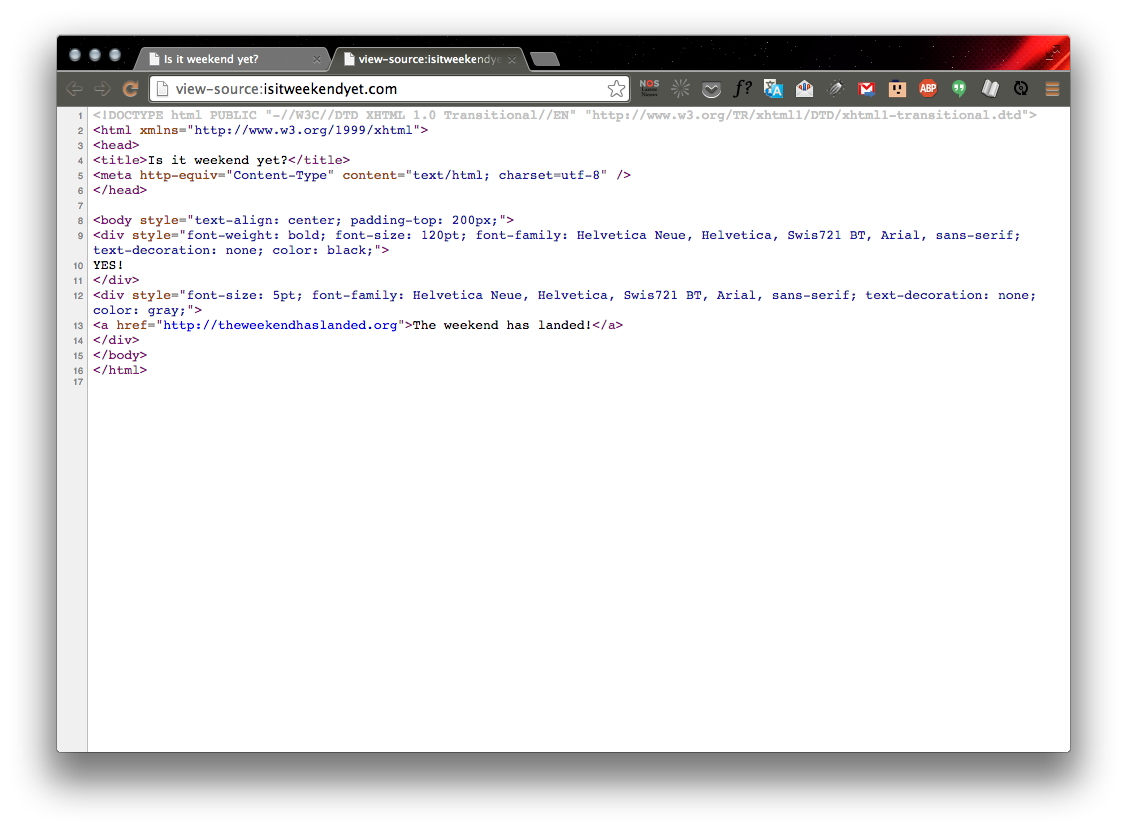
from urllib.request import urlopen
url = 'http://isitweekendyet.com/'
pageSource = urlopen(url).read()
You didn't write that awful page. You're just trying to get some data out of it. Beautiful Soup is here to help. Since 2004, it's been saving programmers hours or days of work on quick-turnaround screen scraping projects.http://www.crummy.com/software/BeautifulSoup/

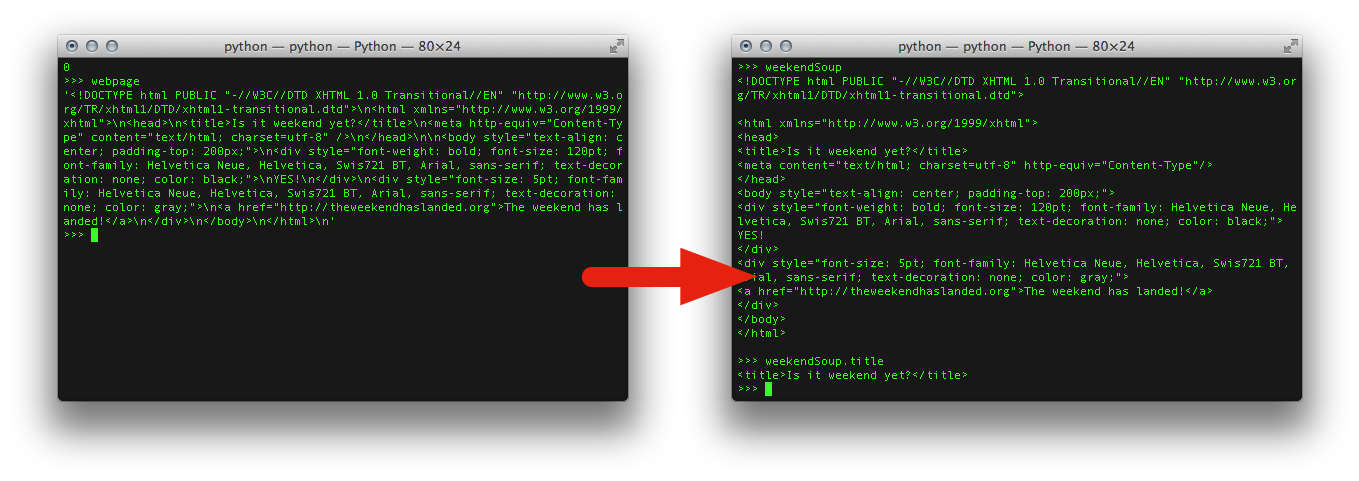
from bs4 import BeautifulSoup
weekendSoup = BeautifulSoup(pageSource, "html.parser")
>>> weekendSoup.title
<title>Is it weekend yet?</title>
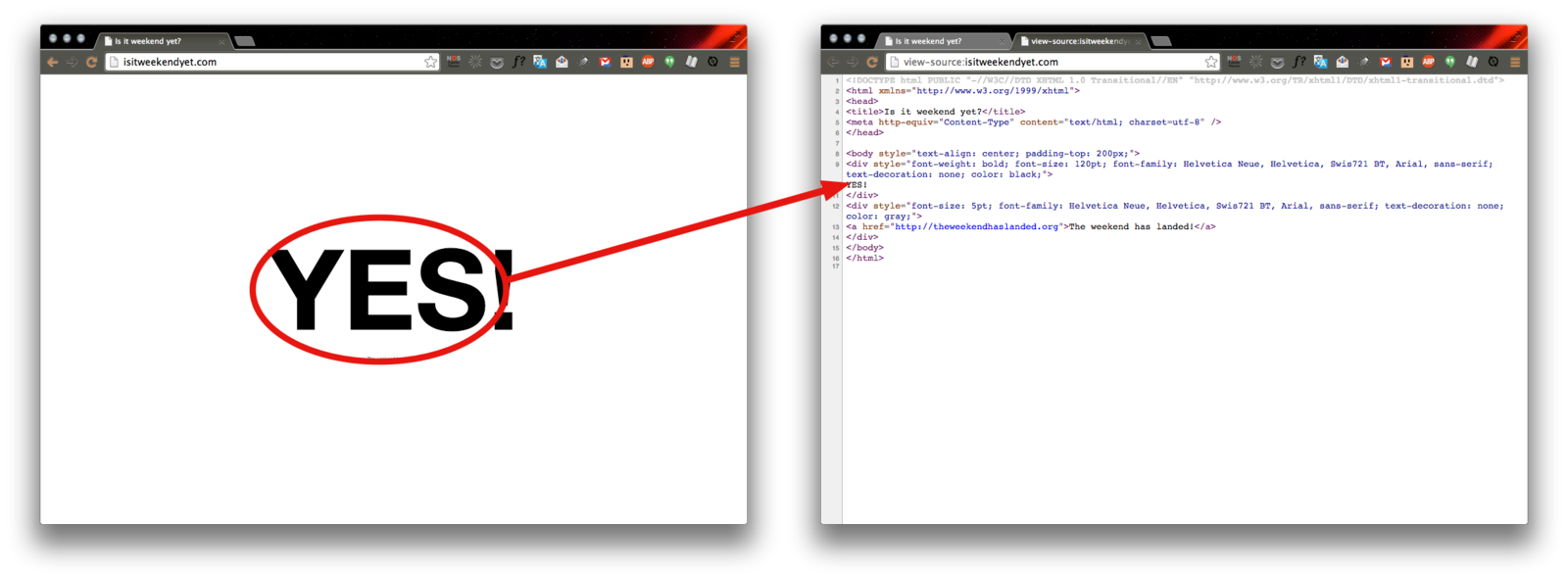
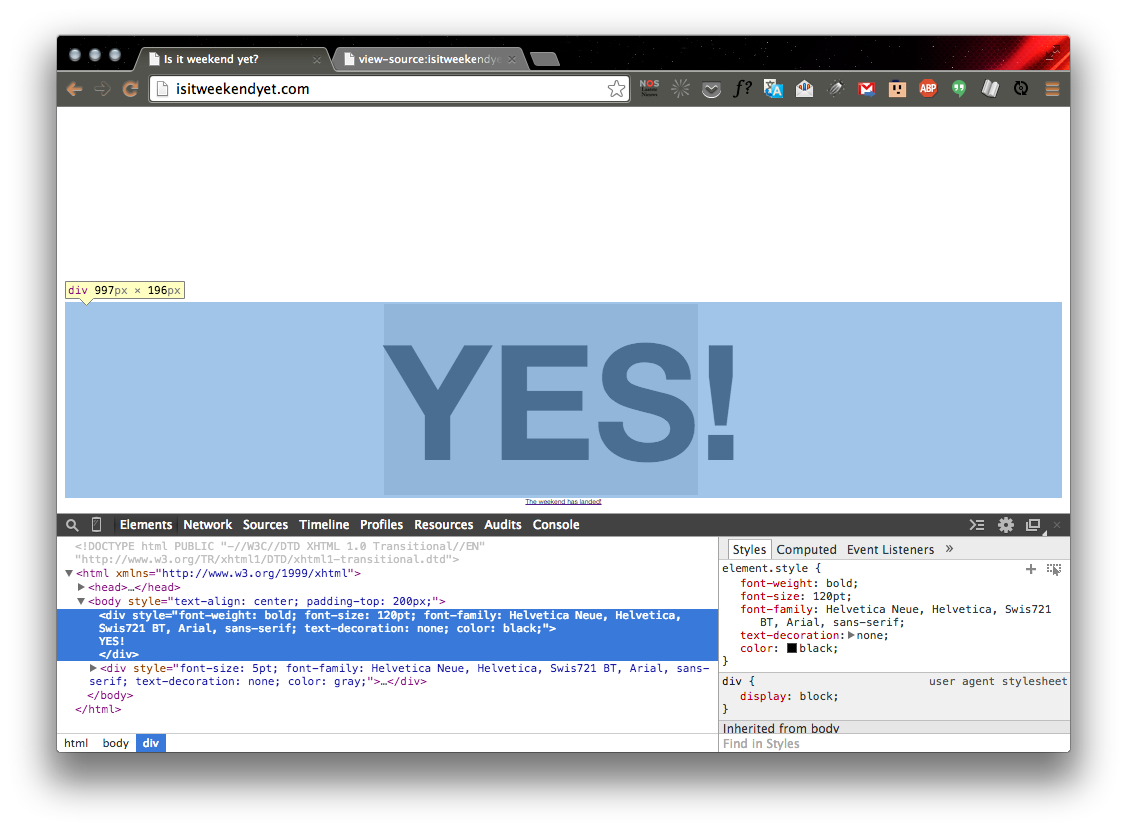
>>> tag = weekendSoup.div
>>> tag
<div style="font-weight: bold; font-size: 120pt; font-family: Helvetica Neue, Helvetica, Swis721 BT, Arial, sans-serif; text-decoration: none; color: black;">
YES!
</div>
>>> type(tag)
<class 'bs4.element.Tag'> >>> tag.string
u'\nYES!\n'
>>> type(tag.string) <class 'bs4.element.NavigableString'>
>>> weekendSoup.title
<title>Is it weekend yet?</title>
>>> weekendSoup.title.string
'Is it weekend yet?'
>>> for ss in body.div.stripped_strings:
print(ss)
...
YES!
>>> bodyTag = weekendSoup.body
>>> bodyTag.contents
[u'\n', <div class="answer text" id="answer" style="font-weight: bold; font-size: 120pt; font-family: Helvetica Neue, Helvetica, Swis721 BT, Arial, sans-serif; text-decoration: none; color: black;">
YES!
</div>, u'\n', <div style="font-size: 5pt; font-family: Helvetica Neue, Helvetica, Swis721 BT, Arial, sans-serif; text-decoration: none; color: gray;">
<a href="http://theweekendhaslanded.org">The weekend has landed!</a>
</div>, u'\n']
<div class="answer text" id="answer" style="font-weight: bold; font-size: 120pt; font-family: Helvetica Neue, Helvetica, Swis721 BT, Arial, sans-serif; text-decoration: none; color: black;">
YES!
</div>
<div style="font-size: 5pt; font-family: Helvetica Neue, Helvetica, Swis721 BT, Arial, sans-serif; text-decoration: none; color: gray;">
<a href="http://theweekendhaslanded.org">The weekend has landed!</a>
</div>
>>> for d in bodyTag.descendants: print d...
<div class="answer text" id="answer" style="font-weight: bold; font-size: 120pt; font-family: Helvetica Neue, Helvetica, Swis721 BT, Arial, sans-serif; text-decoration: none; color: black;">
YES!
</div>
YES!
<div style="font-size: 5pt; font-family: Helvetica Neue, Helvetica, Swis721 BT, Arial, sans-serif; text-decoration: none; color: gray;">
<a href="http://theweekendhaslanded.org">The weekend has landed!</a>
</div>
<a href="http://theweekendhaslanded.org">The weekend has landed!</a>
The weekend has landed!
>>> soup.a.parent.name
u'div'
>>> for p in soup.a.parents: print p.name
...
div
body
html
[document]
>>> weekendSoup.div.next_sibling
u'\n'
>>> weekendSoup.div.next_sibling.next_sibling
<div style="font-size: 5pt; font-family: Helvetica Neue, Helvetica, Swis721 BT, Arial, sans-serif; text-decoration: none; color: gray;">
<a href="http://theweekendhaslanded.org">The weekend has landed!</a>
</div>
write a script:
Use Beautiful Soup to navigate to the answer to our question:
Is it weekend yet?
'''A simple script that tells us if it's weekend yet'''
# import modules
from urllib.request import urlopen
from bs4 import BeautifulSoup
# open webpage
# parse HTML into Beautiful Soup
# extract data from parsed soup
# print answer
Using a filter in a search function
to zoom into a part of the soup
find by element name
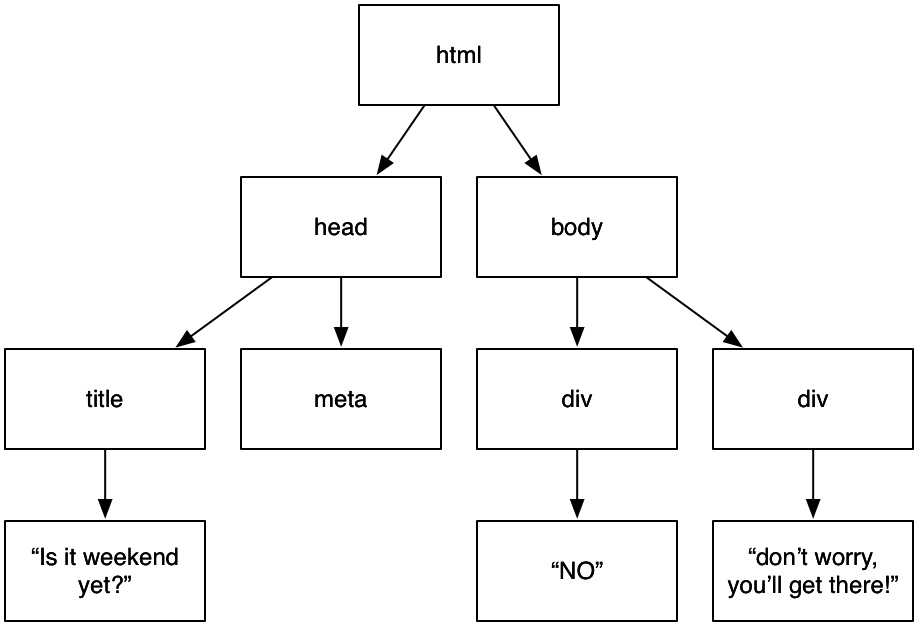
>>> weekendSoup.find_all('div')
[<div style="font-weight: bold; font-size: 120pt; font-family: Helvetica Neue, Helvetica, Swis721 BT, Arial, sans-serif; text-decoration: none; color: black;">
NO
</div>, <div style="font-size: 5pt; font-family: Helvetica Neue, Helvetica, Swis721 BT, Arial, sans-serif; text-decoration: none; color: gray;">
don't worry, you'll get there!
</div>]
>>> weekendSoup.find_all('div')
[<div style="font-weight: bold; font-size: 120pt; font-family: Helvetica Neue, Helvetica, Swis721 BT, Arial, sans-serif; text-decoration: none; color: black;">
NO
</div>, <div style="font-size: 5pt; font-family: Helvetica Neue, Helvetica, Swis721 BT, Arial, sans-serif; text-decoration: none; color: gray;">
don't worry, you'll get there!
</div>]
urlBooks = 'http://books.toscrape.com/'
pageSourceBooks = urlopen(urlBooks).read()
booksSoup = BeautifulSoup(pageSourceBooks, "html.parser")
soumissionLinks = booksSoup.find_all(
'a',
href='catalogue/soumission_998/index.html'
)
books = booksSoup.find_all('article', class_='product_pod')be careful to use "class_" when filtering based on class name
>>> booksSoup.find('title')
<title>
All products | Books to Scrape - Sandbox
</title>
How many projects on (the first page of) the Book Store
have a 1 star rating?
pro tip: use a search function
Bonus:
can you get the count for each of the different ratings?
'''A simple script that scrapes book ratings'''
# import modules
from urllib.request import urlopen
from bs4 import BeautifulSoup
# open webpage
# parse HTML into Beautiful Soup
# extract data from parsed soupsoup.select("#content")soup.select("div#content")
soup.select(".byline")soup.select("li.byline")
soup.select("#content a") soup.select("#content > a") soup.select('a[href]')
soup.select('a[href="http://www.theguardian.com/profile/brianlogan"]')soup.select('a[href^="http://www.theguardian.com/"]')
soup.select('a[href$="info"]')
[<a class="link-text" href="http://www.theguardian.com/info">About us,</a>, <a class="link-text" href="http://www.theguardian.com/info">About us</a>]
>>> guardianSoup.select('a[href*=".com/contact"]')
[<a class="rollover contact-link" href="http://www.theguardian.com/contactus/2120188" title="Displays contact data for guardian.co.uk"><img alt="" class="trail-icon" src="http://static.guim.co.uk/static/ac46d0fc9b2bab67a9a8a8dd51cd8efdbc836fbf/common/images/icon-email-us.png"/><span>Contact us</span></a>]we generally want to:
clean up
calculate
process
>>> answer = soup.div.string
>>> answer
'\nNO\n'
>>> cleaned = answer.strip()
>>> cleaned
'NO'
>>> isWeekendYet = cleaned == 'YES'
>>> isWeekendYet
False # print info to screen
print('Is it weekend yet? ', isWeekendYet)
import csv
with open('weekends.csv', 'w', newline='') as csvfile:
weekendWriter = csv.writer(csvfile)
weekendWriter.writerow(weekendYet)
Build a BitCoin to GBP converter
Get the current BitCoin/GBP exchange rate via
use the input() function to get a user's input
(let the slides help you)
⬇️ see template ⬇️
'''A simple script that ... '''
# import modules
from urllib.request import urlopen
from bs4 import BeautifulSoup
# open webpage
url =
pageSource =
# parse HTML into Beautiful Soup
mySoup =
# extract data from soup
# clean up data
# process data
# action based on data
google; “python” + your problem / question
python.org/doc/; official python documentation, useful to find which functions are available
stackoverflow.com; huge gamified help forum with discussions on all sorts of programming questions, answers are ranked by community
codecademy.com/tracks/python; interactive exercises that teach you coding by doing
wiki.python.org/moin/BeginnersGuide/Programmers; tools, lessons and tutorials
>>> from urllib.request import urlopen
>>> from bs4 import BeautifulSoup
>>> url = "http://isitweekendyet.com/"
>>> source = urlopen(url).read()
>>> soup = BeautifulSoup(source)
>>> soup.body.div.string
'\nNO\n'
# an alternative:
>>> list(soup.body.stripped_strings)[0]
'NO'
'''A simple script that scrapes info about Books'''
# import modules
from urllib.request import urlopen
from bs4 import BeautifulSoup
# open webpage
urlBooks = "http://books.toscrape.com/"
pageSourceBooks = urlopen(urlBooks).read()
# parse HTML into Beautiful Soup
booksSoup = BeautifulSoup(pageSourceBooks, "html.parser")
# extract data from parsed soup
booksOneStar = booksSoup.find_all('p', class_="star-rating One")
oneStarCount = len(booksOneStar)
print(oneStarCount)
#########
# Bonus #
#########
# simple approach
books1StarCount = len(booksSoup.find_all('p', class_="star-rating One"))
books2StarCount = len(booksSoup.find_all('p', class_="star-rating Two"))
books3StarCount = len(booksSoup.find_all('p', class_="star-rating Three"))
books4StarCount = len(booksSoup.find_all('p', class_="star-rating Four"))
books5StarCount = len(booksSoup.find_all('p', class_="star-rating Five"))
print("1 star: ", books1StarCount)
print("2 star: ", books2StarCount)
print("3 star: ", books3StarCount)
print("4 star: ", books4StarCount)
print("5 star: ", books5StarCount)
# more elegant approach
def getStarCount(booksSoup, starClass):
booksWithStarClass = booksSoup.find_all('p', class_="star-rating "+starClass)
starCount = len(booksWithStarClass)
return starCount
starClasses = ["One", "Two", "Three", "Four", "Five"]
starCounts = {}
for starClass in starClasses:
starCount = getStarCount(booksSoup, starClass)
starCounts[starClass] = starCount
print(starCounts)
'''A simple script that converts BTC to GBP based on live rate'''
# import modules
from urllib.request import urlopen
from bs4 import BeautifulSoup
# open webpage
url = "https://exchangerate.guru/btc/"
pageSource = urlopen(url).read()
# parse HTML into Beautiful Soup
btcSoup = BeautifulSoup(pageSource, "html.parser")
# extract data from parsed soup
gbpRateTag = btcSoup.find('a', href='/btc/gbp/1/')
gbpRate = float(gbpRateTag.string)
# get input from user
noBitcoinString = input('How many Bitcoin have you got? ')
noBitcoin = float(noBitcoinString)
# calculate and print answer
noGBP = noBitcoin * gbpRate
print("WOW! you have " + str(noGBP) + "£!!!")'''
LiteCoin converter that tells us how much your LiteCoins are worth in EURO
NB: expects python3
'''
# import modules
from urllib.request import urlopen
from bs4 import BeautifulSoup
def clean_up_rate(rateString):
''''Clean up raw rateString to form rate'''
rateStringStripped = rateString.strip()
rateNumber = rateStringStripped[1:10]
return float(rateNumber)
# open webpage
url = "http://litecoinexchangerate.org/c/EUR"
pageSource = urlopen(url).read()
# turn html into beautiful soup
liteCoinSoup = BeautifulSoup(pageSource, "html.parser")
# extract info from soup
rateString = liteCoinSoup.find('b').string
# clean up data
rate = clean_up_rate(rateString)
# get user input
litecoinsString = input("How many litecoins have you got?\n>>> ")
litecoins = float(litecoinsString)
# print output
EURO = rate * litecoins
print("You have", round(EURO,2), "EURO!")'''
Bitcoin converter that tells us how much your bitcoins are worth in GBP
NB: expects python3
'''
# import modules
from urllib.request import urlopen
from bs4 import BeautifulSoup
def clean_up_rate(rateString):
''''Clean up raw rateString to form rate'''
rateNumber = rateString[1:10]
return float(rateNumber)
def main():
'''Our main function that gets called when we run the program'''
# open webpage
url = "http://bitcoinexchangerate.org/c/GBP/1"
webpage = urlopen(url).read()
# turn html into beautiful soup
bitcoinSoup = BeautifulSoup(webpage, "html.parser")
# extract info from soup
rateString = bitcoinSoup.find('b').string.strip()
# clean up data
rate = clean_up_rate(rateString)
# get user input
bitcoinsString = input("How many bitcoins have you got?\n>>> ")
bitcoins = float(bitcoinsString)
# print output
GBP = rate * bitcoins
print("You have", round(GBP,2), "GBP!")
# this kicks off our program & lets us both run and import the program
if __name__ == '__main__':
main() By Philo van Kemenade
A practical introduction to webscraping with Python




