




























russtedrake PRO
Roboticist at MIT and TRI
Towards Foundations Models for Control(?)
Russ Tedrake
November 3, 2023
"What's still hard for AI" by Kai-Fu Lee:
Manual dexterity
Social intelligence (empathy/compassion)
"Dexterous Manipulation" Team
(founded in 2016)
For the next challenge:
For the next challenge:
"And then … BC methods started to get good. Really good. So good that our best manipulation system today mostly uses BC ..."
Senior Director of Robotics at Google DeepMind
Levine*, Finn*, Darrel, Abbeel, JMLR 2016
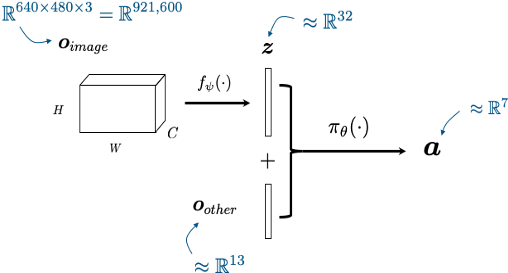
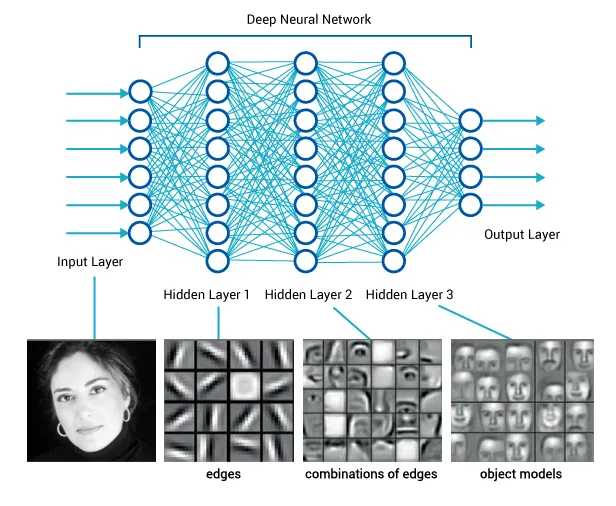
perception network
(often pre-trained)
policy network
other robot sensors
learned state representation
actions
x history
We've been exploring, and seem to have found something...
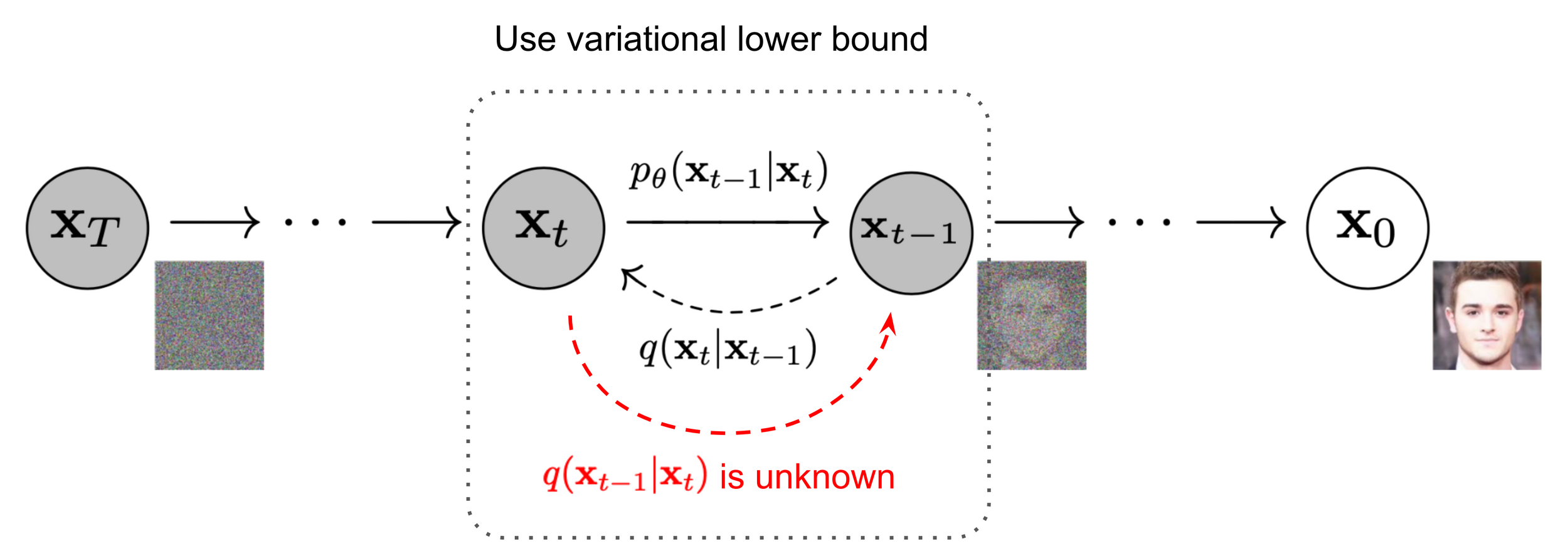
Image source: Ho et al. 2020
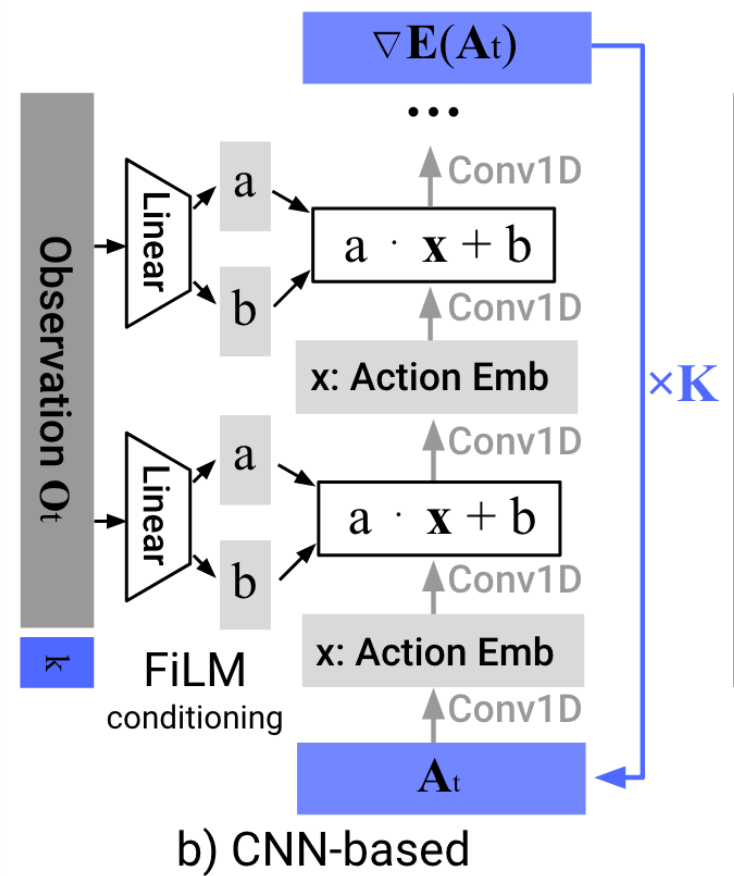
Denoiser can be conditioned on additional inputs, \(u\): \(p_\theta(x_{t-1} | x_t, u) \)
Denoising approximates the projection onto the data manifold;
approximating the gradient of the distance to the manifold
input
output
Control Policy
(as a dynamical system)
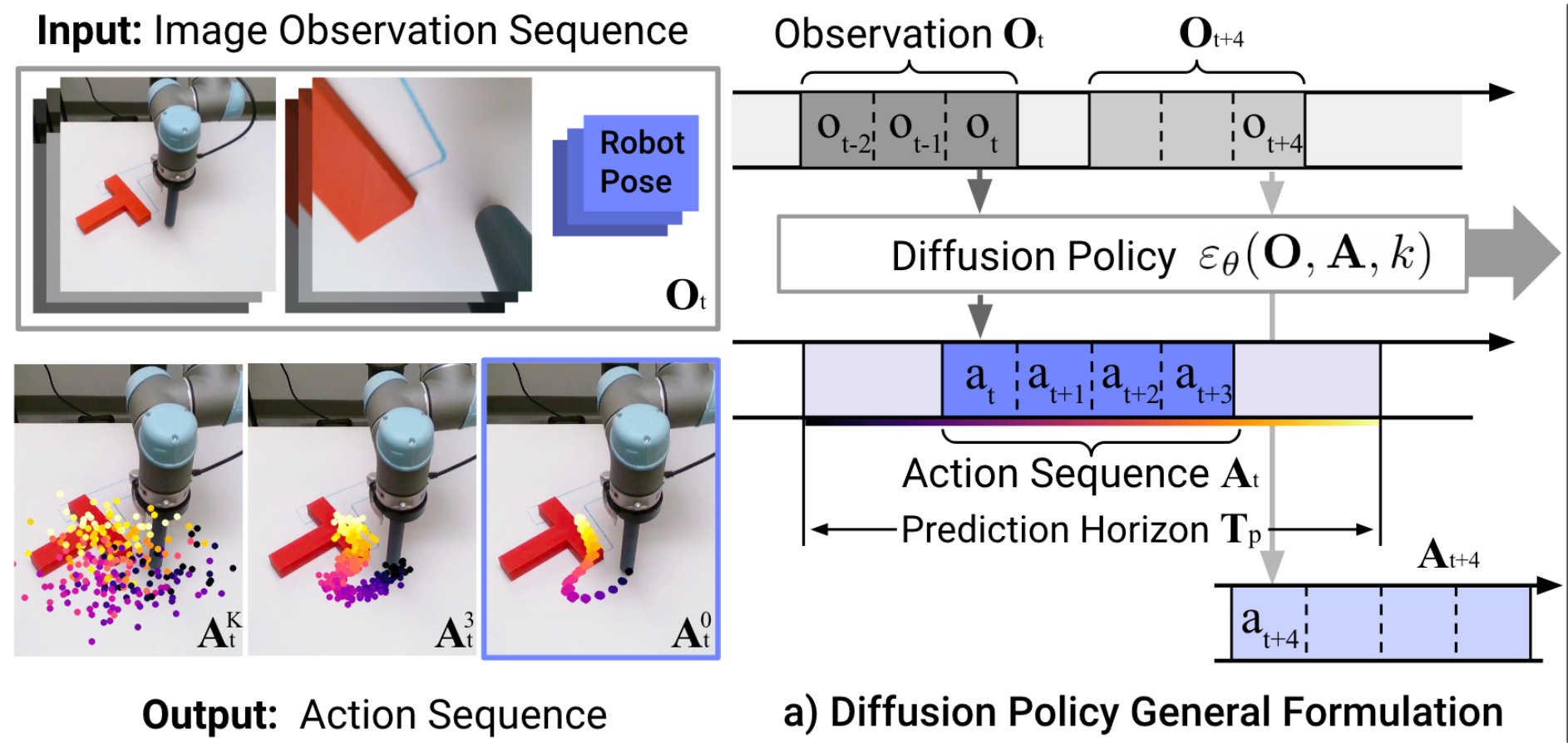
"Diffusion Policy" is an auto-regressive (ARX) model with forecasting
\(H\) is the length of the history,
\(P\) is the length of the prediction
Conditional denoiser produces the forecast, conditional on the history
Image backbone: ResNet-18 (pretrained on ImageNet)
Total: 110M-150M Parameters
Training Time: 3-6 GPU Days ($150-$300)
e.g. to deal with "multi-modal demonstrations"
Andy Zeng's MIT CSL Seminar, April 4, 2022
Andy's slides.com presentation
with TRI's Soft Bubble Gripper
Open source:
I do think there is something deep happening here...
If we really understand this, can we do the same via principles from a model? Or will control go the way of computer vision and language?
What if I did have a good model? (and well-specified objective)
Lee et al., Learning quadrupedal locomotion over challenging terrain, Science Robotics, 2020
Do Differentiable Simulators Give Better Policy Gradients?
H. J. Terry Suh and Max Simchowitz and Kaiqing Zhang and Russ Tedrake
ICML 2022
Available at: https://arxiv.org/abs/2202.00817
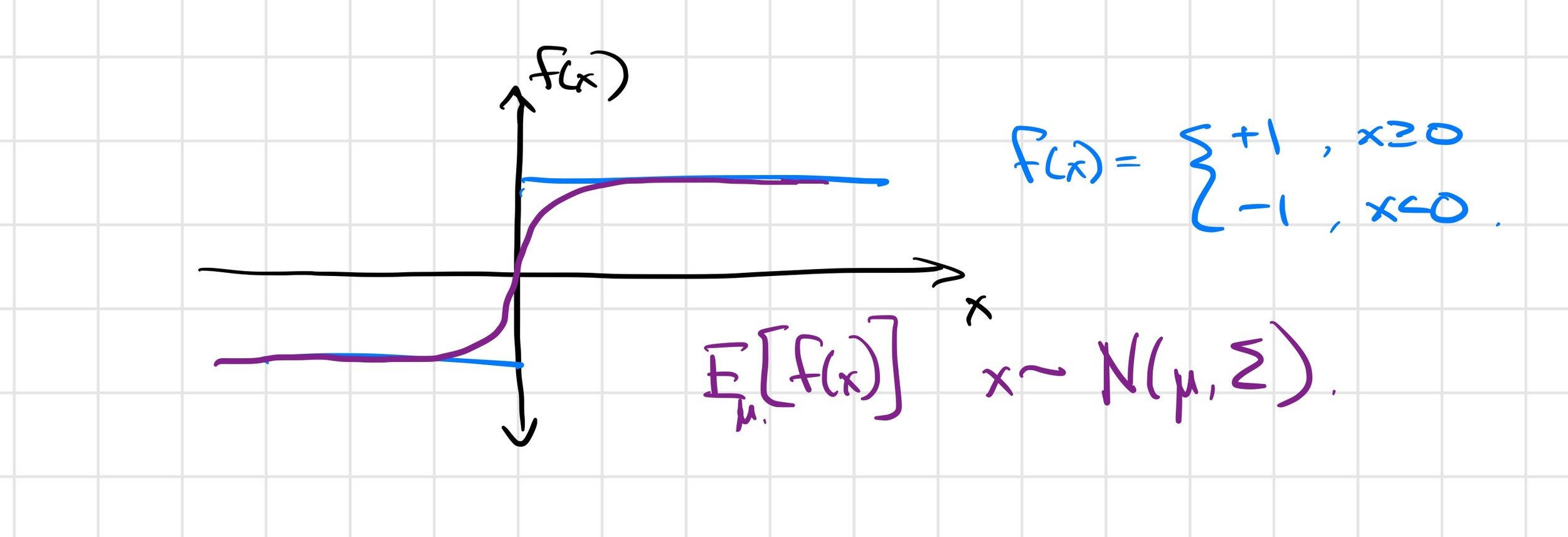
A key question for the success of gradient-based optimization
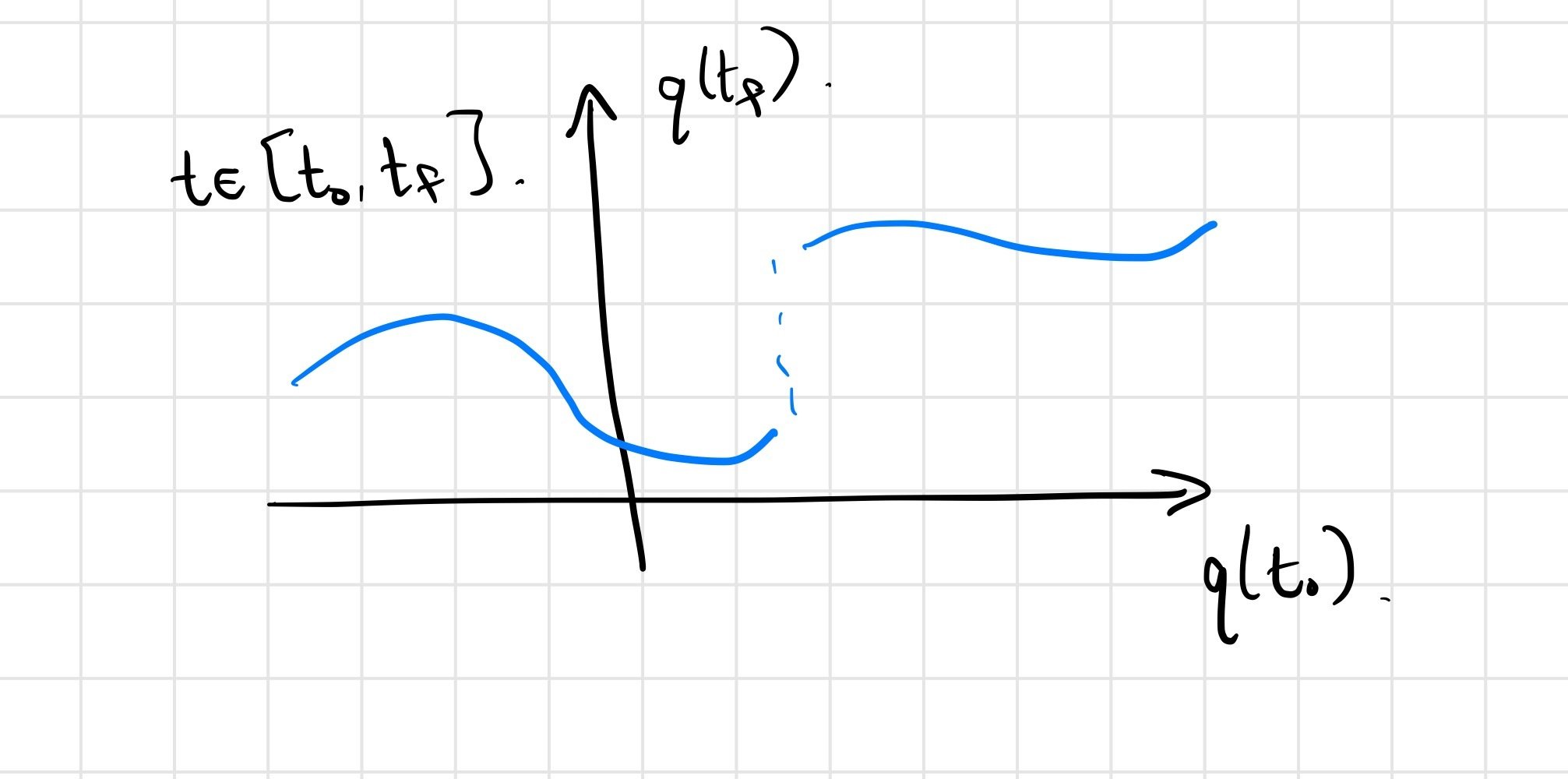
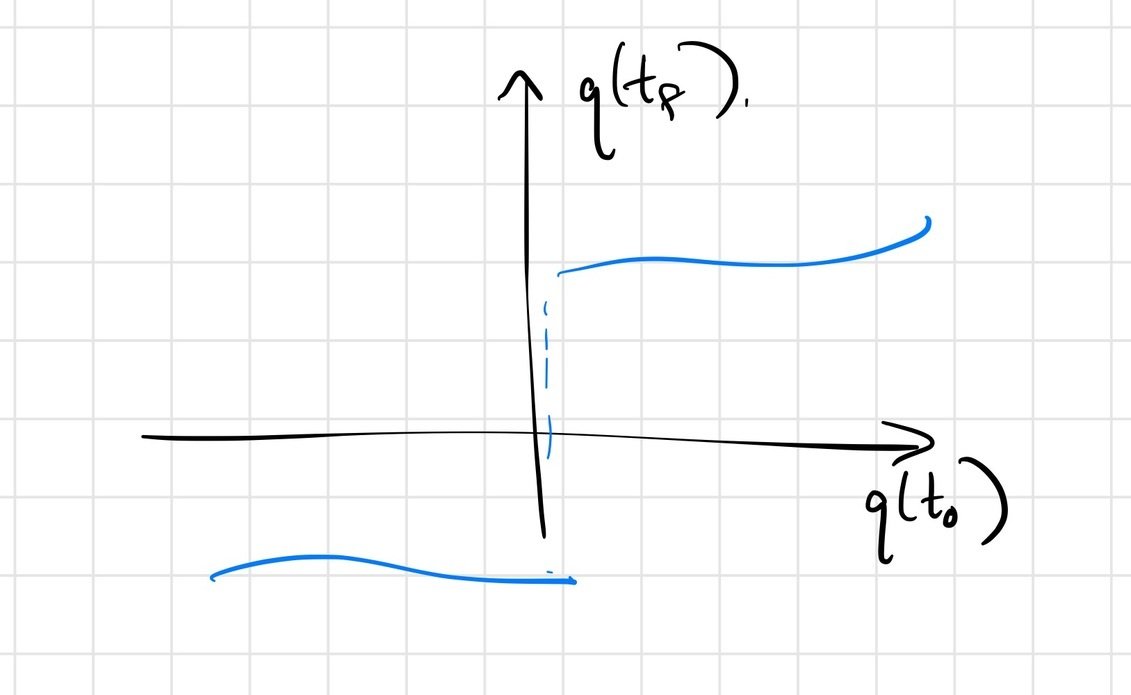
Use initial conditions here as a surrogate for dependence on policy parameters, etc.; final conditions as surrogate for reward.
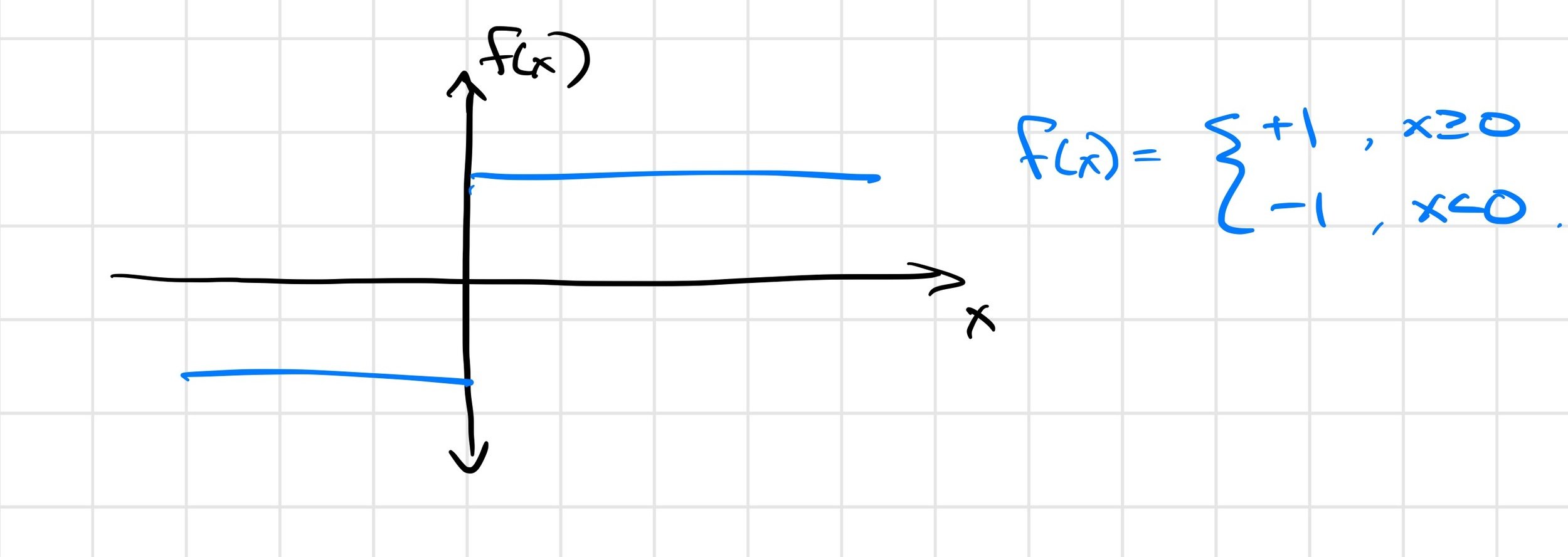
For the mathematical model... (ignoring numerical issues)
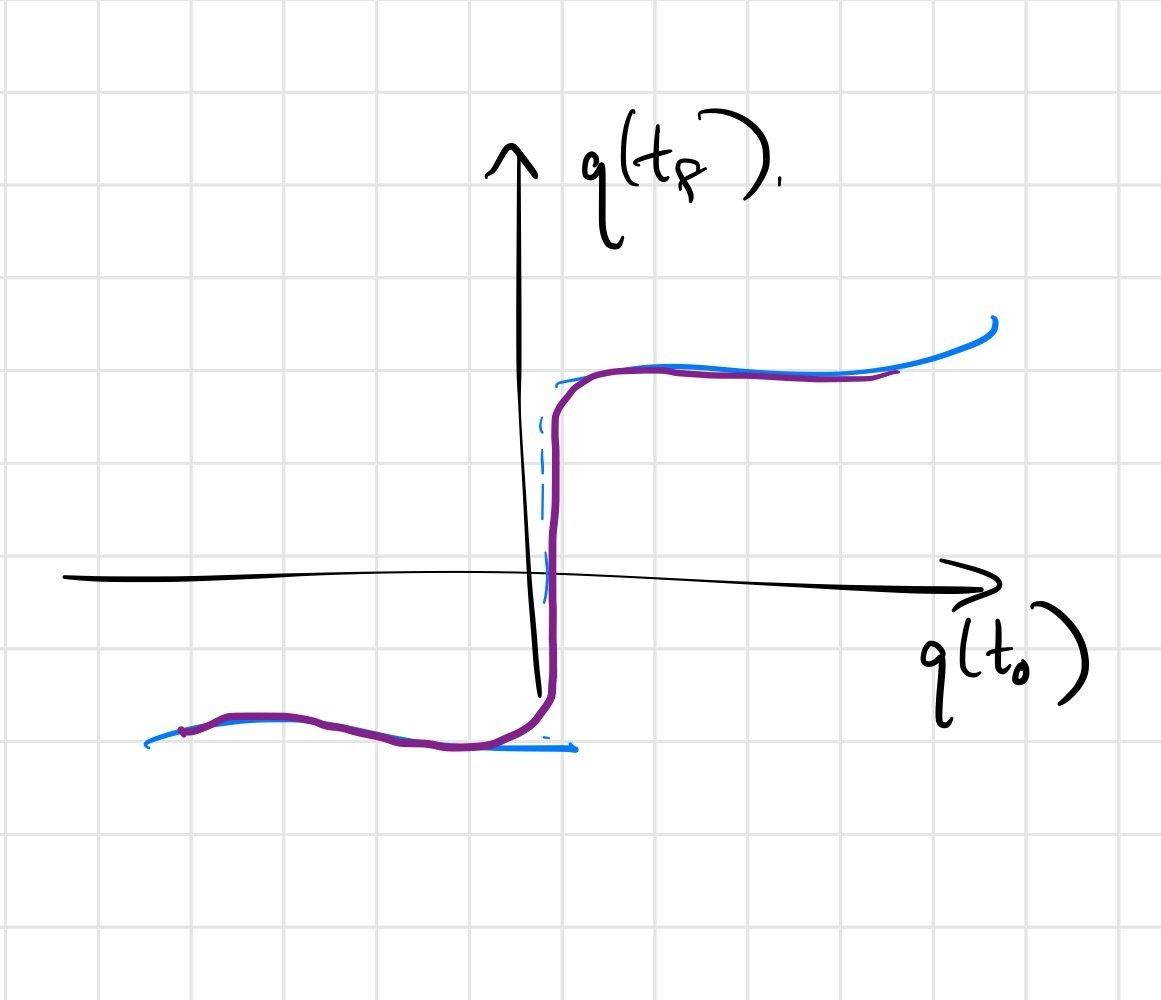
we do expect \(q(t_f) = F\left(q(t_0)\right)\) to be continuous.
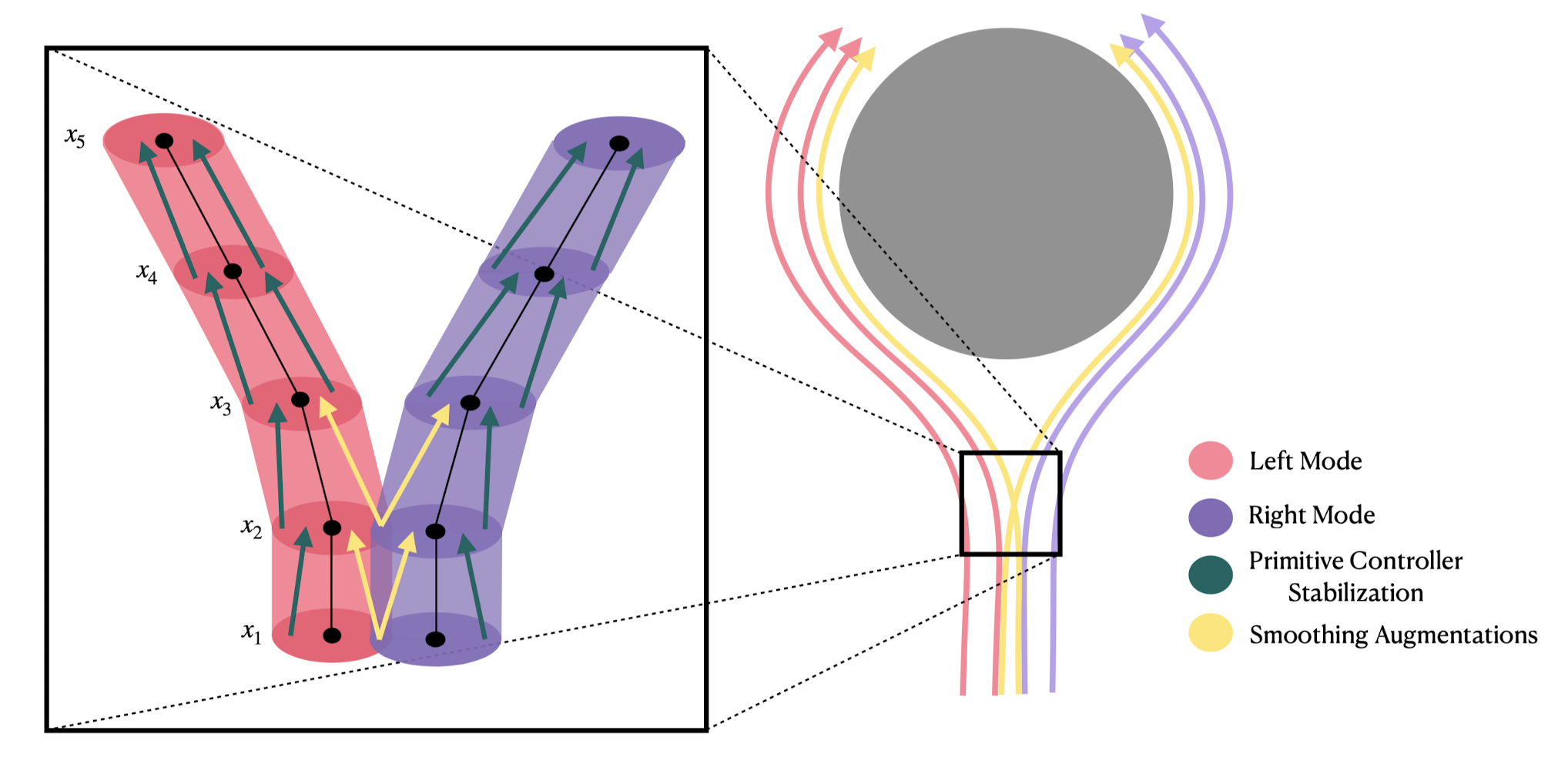
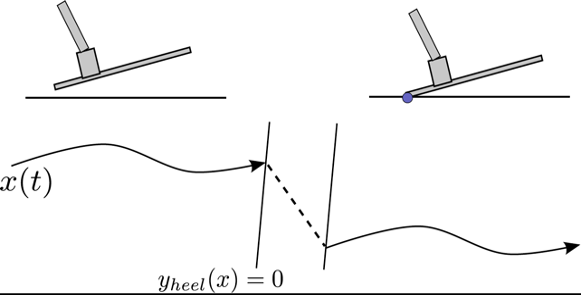
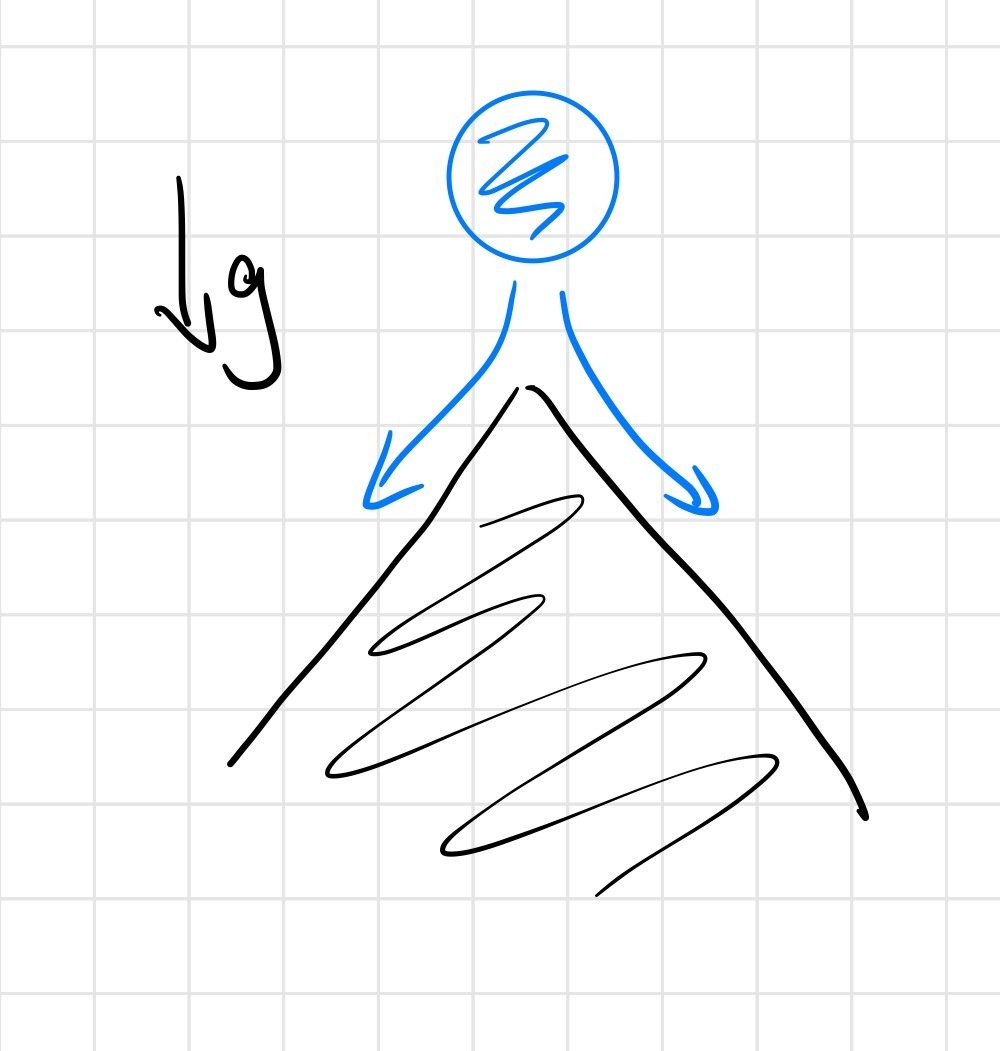
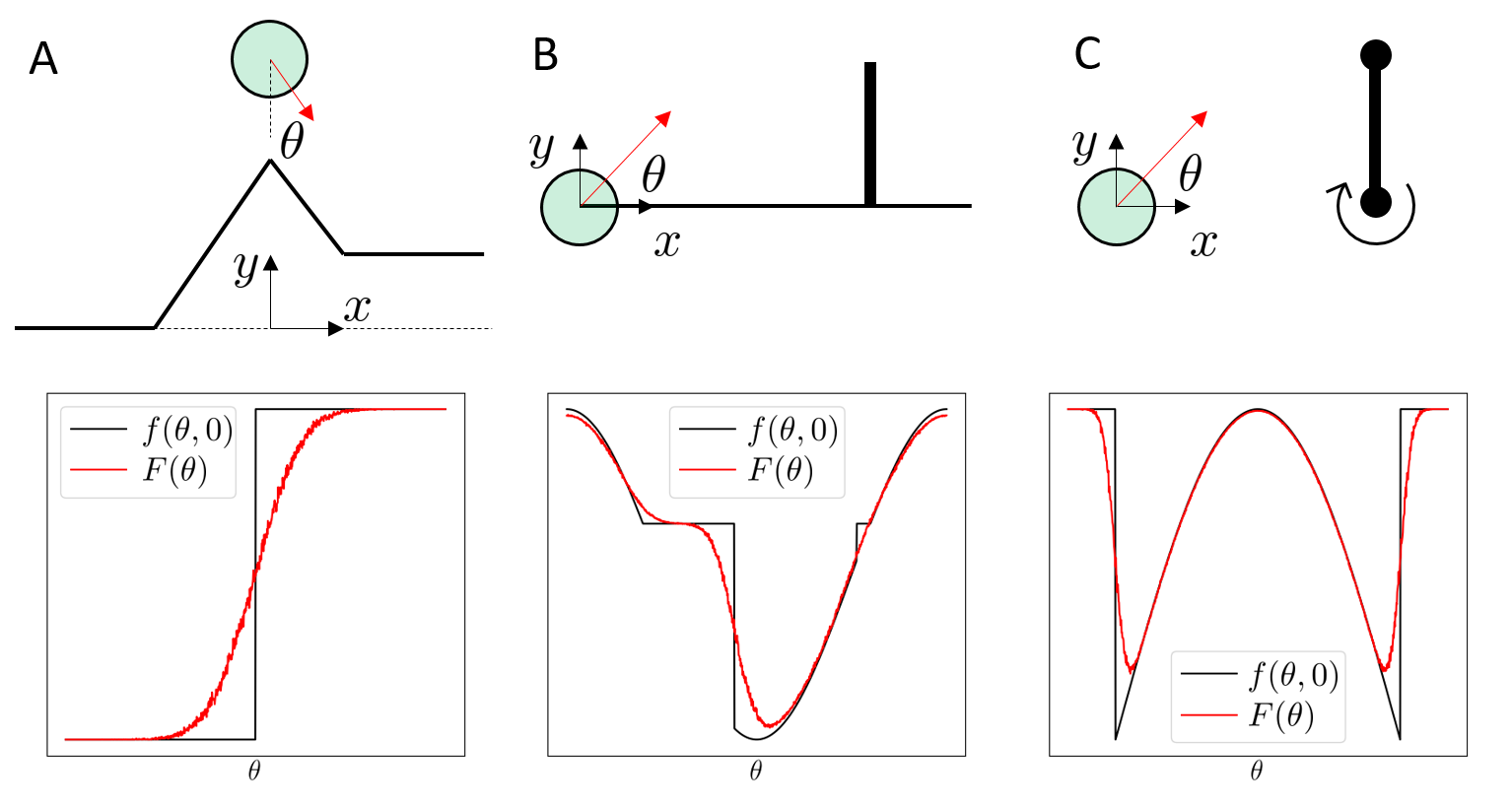
point contact on half-plane
We have "real" discontinuities at the corner cases
Soft/compliant contact can replace discontinuities with stiff approximations
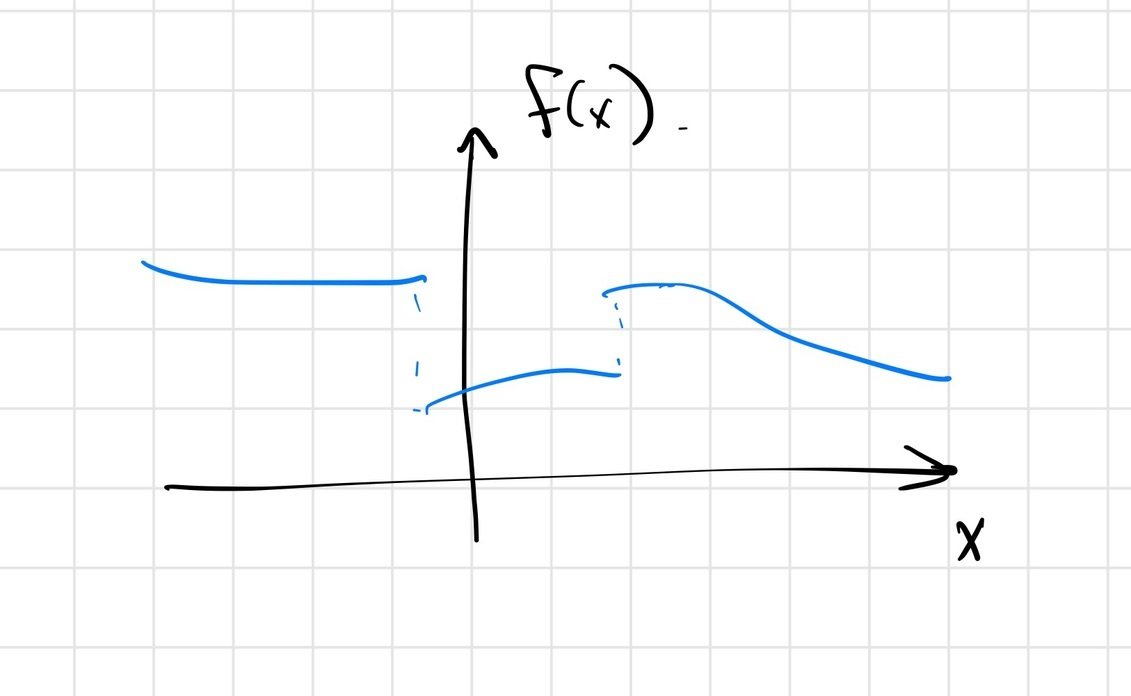
\[ \min_x f(x) \]
For gradient descent, discontinuities / non-smoothness can
vs
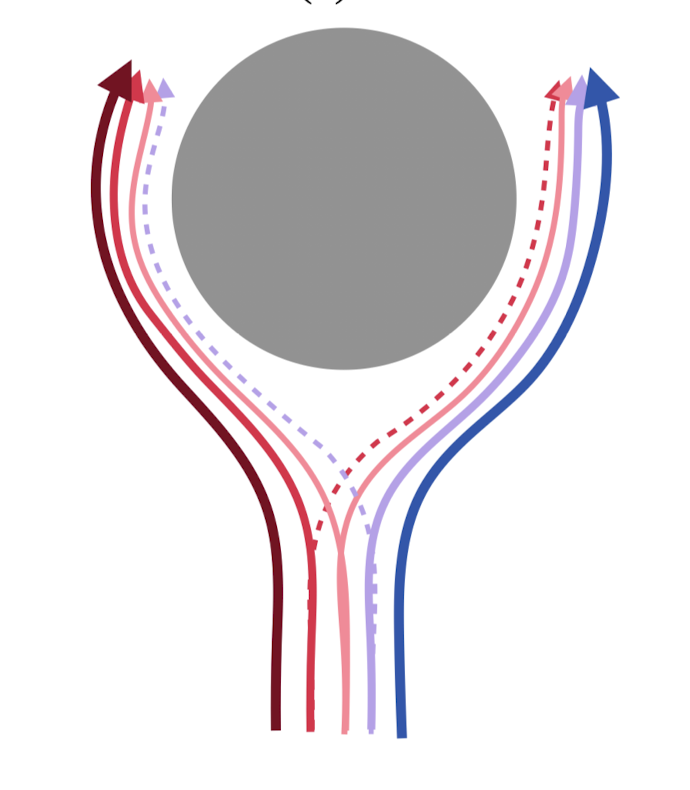
In reinforcement learning (RL) and "deep" model-predictive control, we add stochasticity via
then optimize a stochastic optimal control objective (e.g. maximize expected reward)
These can all smooth the optimization landscape.
(discrete + continuous planning and control)
Note: The blue regions are not obstacles.
Mixed-integer formulation with a very tight convex relaxation
Main idea: Multiply constraints + Perspective function machinery
Motion Planning around Obstacles with Convex Optimization.
Tobia Marcucci, Mark Petersen, David von Wrangel, Russ Tedrake.
Available at: https://arxiv.org/abs/2205.04422
Accepted for publication in Science Robotics
Claims:
Default playback at .25x
Dave Johnson (CEO): "wow -- GCS (left) is a LOT better! ... This is a pretty special upgrade which is going to become the gold standard for motion planning."
pip install drake
sudo apt install drakehttp://manipulation.mit.edu
http://underactuated.mit.edu
By russtedrake
Princeton Robotics Seminar



