

Lecture 9: Transformers
Intro to Machine Learning

[video edited from 3b1b]
Recap: Word embedding
this enables "soft" dictionary look-up:
dict_en2fr = {
"apple" : "pomme",
"banana": "banane",
"lemon" : "citron"}Good word-embeddings space is equipped with semantically meaningful vector arithmetic
Key
Value
apple
pomme
\(:\)
banane
banana
\(:\)
citron
lemon
\(:\)
dict_en2fr = {
"apple" : "pomme",
"banana": "banane",
"lemon" : "citron"}
query = "orange"
output = dict_en2fr[query]Python would complain. 🤯
orange
apple
pomme
banane
citron
banana
lemon
Key
Value
\(:\)
\(:\)
\(:\)
Query
Output
???
But we can probably see the rationale behind something like this:
Query
Key
Value
Output
orange
apple
\(:\)
pomme
banana
\(:\)
banane
lemon
\(:\)
citron
dict_en2fr = {
"apple" : "pomme",
"banana": "banane",
"lemon" : "citron"}
query = "orange"
output = dict_en2fr[query]0.1
pomme
0.1
banane
0.8
citron
+
+
0.1
pomme
0.1
banane
0.8
citron
+
+
via these mixing percentages \([0.1 0.1 0.8]\) made sense
We put (query, key, value) in "good" embeddings in our human brain
such that mixing the values
Query
Key
Value
Output
orange
apple
\(:\)
pomme
0.1
pomme
0.1
banane
0.8
citron
banana
\(:\)
banane
lemon
\(:\)
citron
+
+
orange
orange
0.1
pomme
0.1
banane
0.8
citron
+
+
apple
banana
lemon
orange
0.8
0.1
0.1
pomme
banane
citron
+
+
very roughly, the attention mechanism in transformers automates this process.
apple
banana
lemon
orange
,
,
orange
orange
Query
Key
Value
Output
orange
apple
\(:\)
pomme
banana
\(:\)
banane
lemon
\(:\)
citron
orange
orange
pomme
banane
citron
0.1
pomme
0.1
banane
0.8
citron
+
+
pomme
banane
citron
+
+
dot-product similarity
softmax
\Bigg(
\begin{array}{l}
\end{array}
\Bigg.
\Bigg)
\begin{array}{l}
\end{array}
\Bigg.
a. compare query and key for merging percentages:
0.1
0.1
0.8
=[\quad \quad \quad ]
0.1
0.1
0.8
Query
Key
Value
Output
orange
apple
\(:\)
pomme
0.1
pomme
0.1
banane
0.8
citron
banana
\(:\)
banane
lemon
\(:\)
citron
+
+
orange
orange
pomme
banane
citron
+
+
0.8
0.1
0.1
pomme
banane
citron
+
+
b. then output mixed values
a. compare query and key for merging percentages:
Let's see how this intuition becomes a trainable mechanism.
apple
banana
lemon
orange
,
,
orange
orange
softmax
\Bigg(
\begin{array}{l}
\end{array}
\Bigg.
\Bigg)
\begin{array}{l}
\end{array}
\Bigg.
=[\quad \quad \quad ]
0.1
0.1
0.8
Outline
- Transformers high-level intuition and architecture
- Attention mechanism
- Multi-head attention
- (Applications)
- Transformers high-level intuition and architecture
- Attention mechanism
- Multi-head attention
- (Applications)
Large Language Models (LLMs) are trained in this self-supervised way

- Scrape the internet for plain texts.
- Cook up “labels” (prediction targets) from these texts.
- Convert “unsupervised” problem into “supervised” setup.
"To date, the cleverest thinker of all time was Issac. "
feature
label
To date, the
cleverest
To date, the cleverest
thinker
To date, the cleverest thinker
was
\dots
\dots
To date, the cleverest thinker of all time was
Issac
auto-regressive prediction
[video edited from 3b1b]
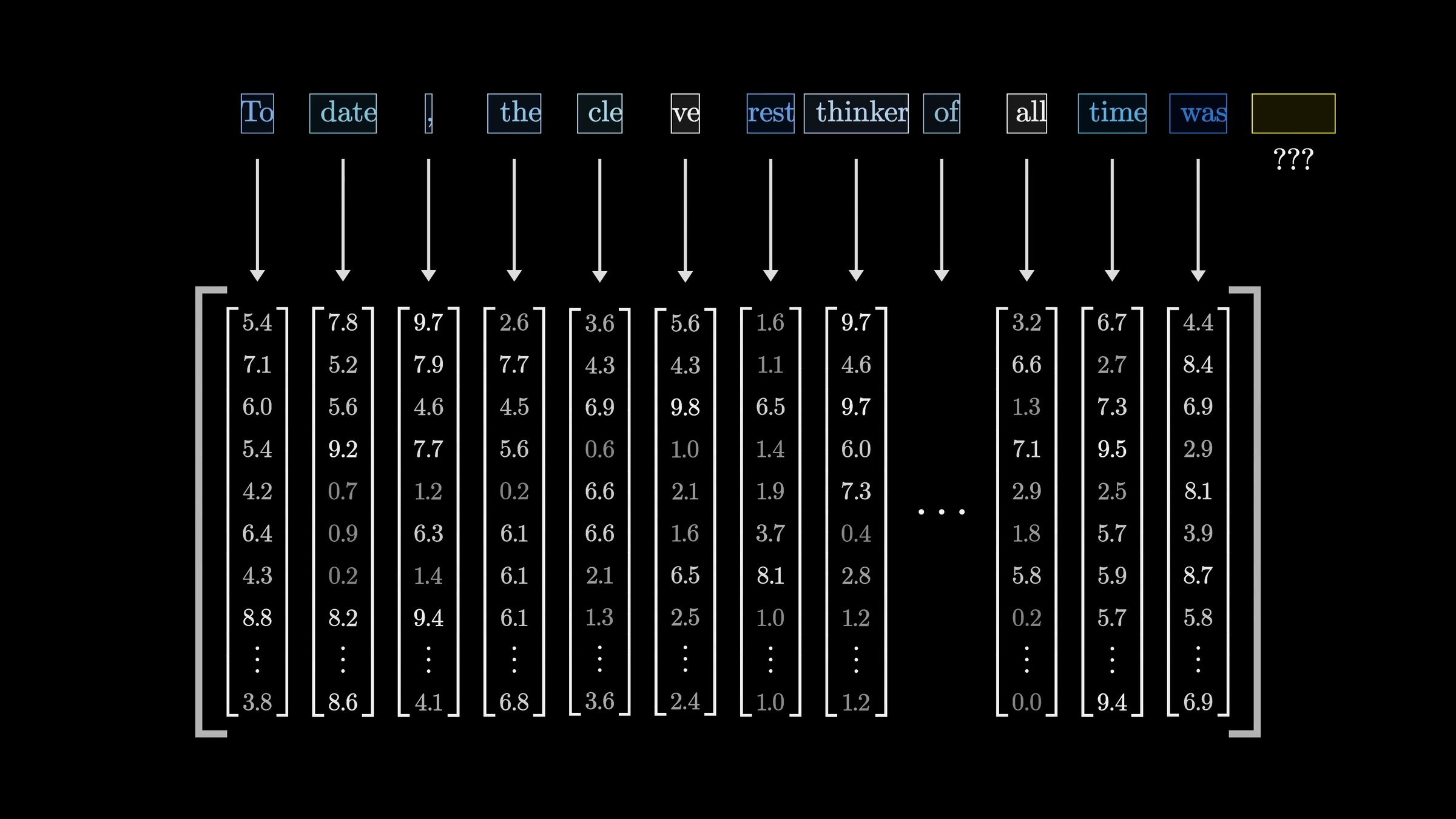
\(n\)
\underbrace{\hspace{5.98cm}}
\left\{
\begin{array}{l}
\\
\\
\\
\\
\\
\\
\\
\end{array}
\right.
\(d\)
input embedding
[video edited from 3b1b]
Minimizing cross-entropy loss drives the weights to assign higher probability to the correct next token
word embedding to a softmax distribution over the vocabulary
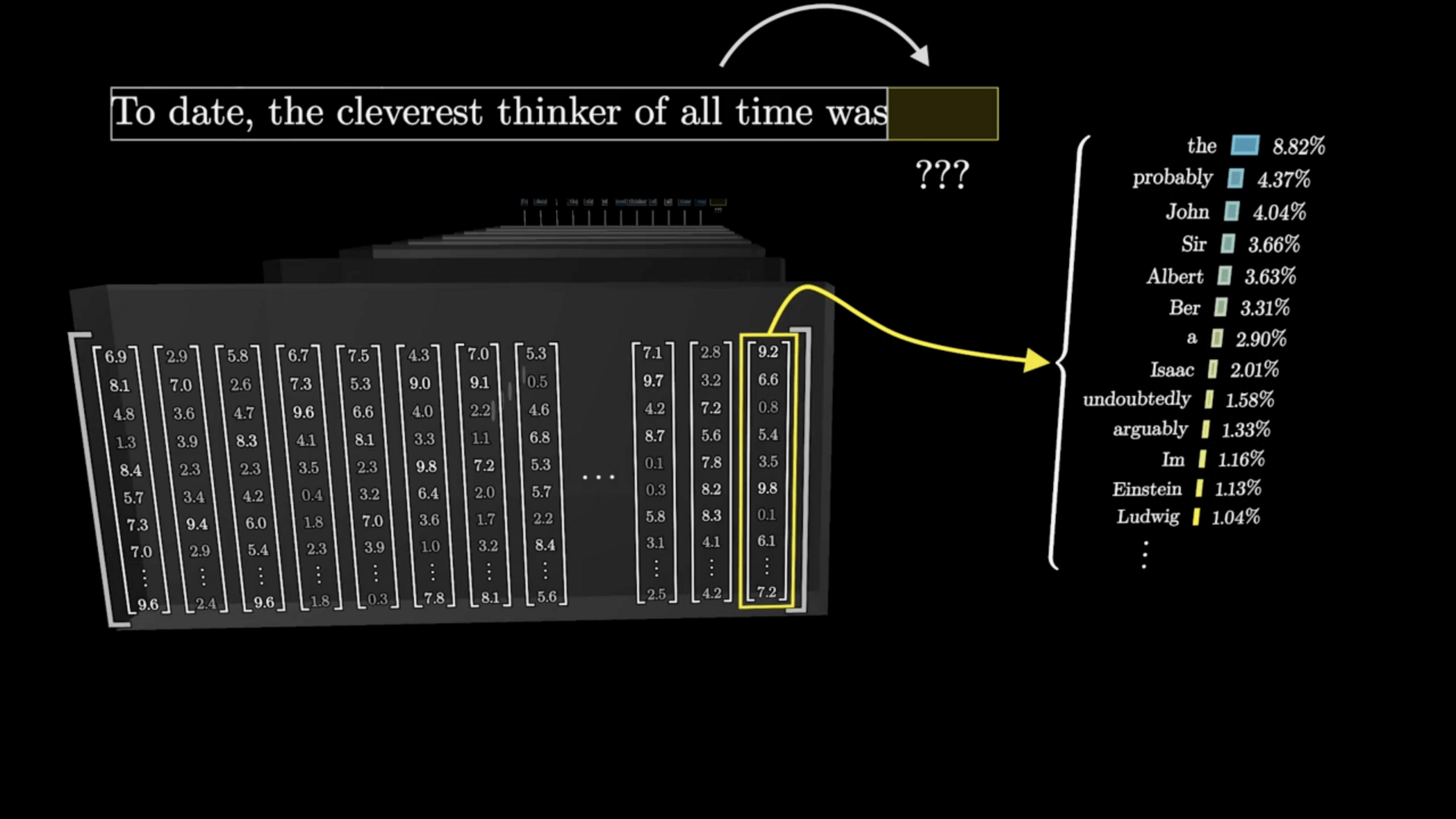
[video edited from 3b1b]
Transformer
"To date, the cleverest [thinker] of all time was Issac.
push for Prob("date") to be high
push for Prob("the") to be high
push for Prob("cleverest") to be high
push for Prob("thinker") to be high
\left\{
\begin{array}{l}
\\
\\
\end{array}
\right.
distribution over the vocabulary
\(\dots\)
\(\dots\)
\(\dots\)
\(\dots\)
To
date
the
cleverest
input embedding
\(\dots\)
\(\dots\)
\(\dots\)
transformer block
transformer block
transformer block
\left\{
\begin{array}{l}
\\
\\
\\
\\
\\
\end{array}
\right.
\(L\) blocks
\(\dots\)
\(\dots\)
output embedding
To
date
the
cleverest
\(\dots\)
transformer block
transformer block
transformer block
x_1
x_2
x_3
x_4
A sequence of \(n\) tokens, each token in \(\mathbb{R}^{d}\)
\(\dots\)
\(\dots\)
\(\dots\)
\(\dots\)
output embedding
input embedding
input embedding
To
date
the
cleverest
input embedding
\(\dots\)
transformer block
output embedding
x_1
x_2
x_3
x_4
\(\dots\)
\(\dots\)
\(\dots\)
\(\dots\)
transformer block
transformer block
each of the \(n\) tokens transformed, block by block
within a shared \(d\)-dimensional word-embedding space.
To
date
the
cleverest
attention layer
MLP
x_1
x_2
x_3
x_4
\(\dots\)
\(\dots\)
\(\dots\)
\(\dots\)
neuron weights
\nabla{\mathcal{L}}
\dots
W_k
W_v
W_q
W^o
input embedding
transformer block
output embedding
To
date
the
cleverest
attention layer
x_1
x_2
x_3
x_4
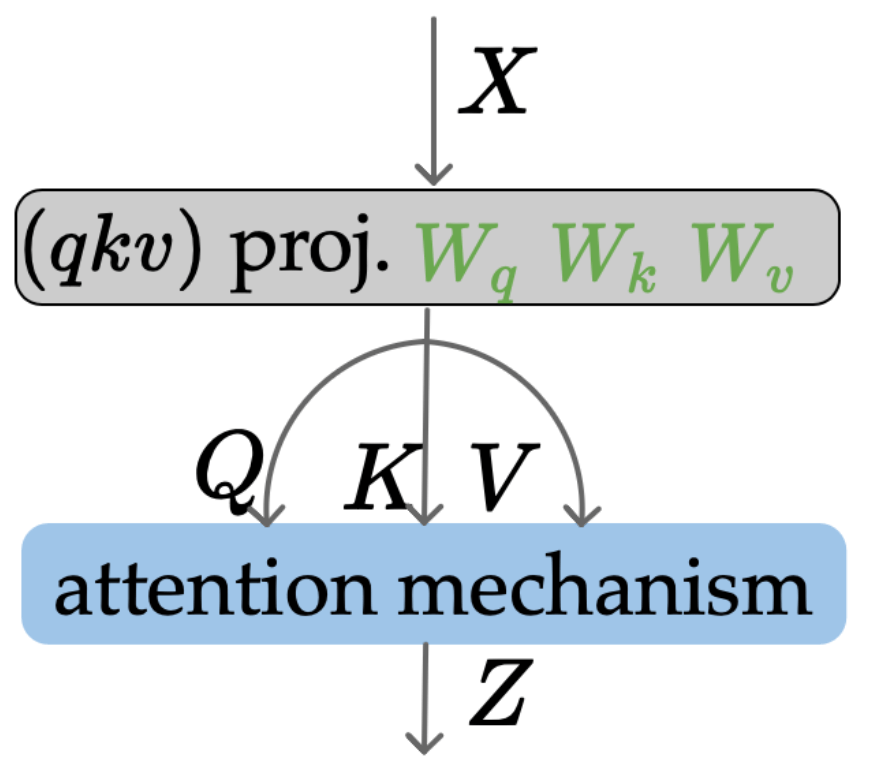
W^o
attention output projection
W_k
W_v
W_q
\((qkv)\) projection
attention mechanism
Most important bits in an attention layer:
- (query, key, value) projection
- attention mechanism
Why learning these projections:
- \(W_q\) learns how to ask
- \(W_k\) learns how to listen
- \(W_v\) learns how to speak
With learned projections, we frame \(x\) into:
- a query to be the questions
- a key to be compared
- a value to contribute
x
q
k
v
W_q
W_k
W_v
1. (query, key, value) projection
W_k
W_v
W_q
x_2
W_k
W_v
W_q
x_3
W_k
W_v
W_q
x_4
W_k
W_v
W_q
q_2
v_2
k_2
q_3
v_3
k_3
q_4
v_4
k_4
- \(W_q, W_k, W_v\), all in \(\mathbb{R}^{d \times d_k}\)
- project word embedding \(x\) from \(d\)-dimensional space to \(d_k\)-dimensional (\(q, k, v\)) spaces (typically \(d_k < d\))
- \(q_i = W_q^Tx_i,\; k_i = W_k^Tx_i,\; v_i = W_v^Tx_i,\; \forall i\) — weight sharing across positions
- parallel and structurally identical processing
\left\{
\begin{array}{l}
\\
\\
\end{array}
\right.
d_k
x_1
q_1
v_1
k_1
1. (query, key, value) projection
To
date
the
cleverest
x_1
q_1
v_1
k_1
W_k
W_v
W_q
x_2
x_3
x_4
q_2
v_2
k_2
q_3
v_3
k_3
q_4
v_4
k_4
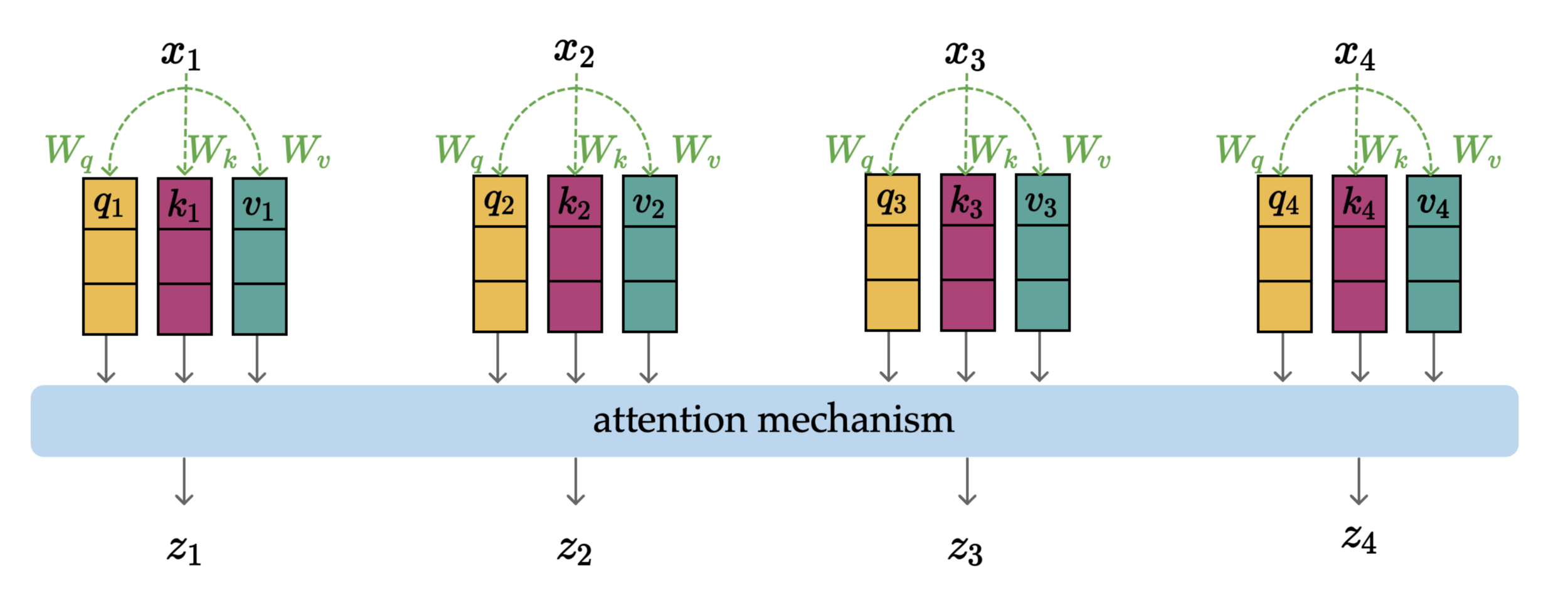
- Attention mechanism turns the projected \((q,k,v)\) into \(z\)
- Each \(z\) is context-aware: a mixture of everyone's values, weighted by relevance
W_k
W_v
W_q
W_k
W_v
W_q
W_k
W_v
W_q
2. Attention mechanism
attention mechanism
z_1
z_2
z_3
z_4
To
date
the
cleverest
Outline
- Transformers high-level intuition and architecture
- Attention mechanism
- Multi-head attention
- (Applications)
v_1
k_1
q_1
v_2
k_2
q_2
v_3
k_3
q_3
v_4
q_4
k_4
v_4
v_4
v_4
q_1
\left\{
\begin{array}{l}
\\
\\
\end{array}
\right.
d_k
q_1
q_1
q_1
q_1
k_1
k_2
k_3
k_4
attention mechanism
x_1
x_2
x_3
x_4
z_1
z_2
z_3
z_4
?
To
date
the
cleverest
v_1
k_1
q_1
v_2
k_2
q_2
v_3
k_3
q_3
v_4
q_4
k_4
v_4
v_4
v_4
q_1
q_1
q_1
q_1
q_1
k_1
k_2
k_3
k_4
softmax
\Bigg(
\begin{array}{l}
\end{array}
\Bigg.
\Bigg)
\begin{array}{l}
\end{array}
\Bigg.
,
,
,
\Bigg[
\begin{array}{l}
\end{array}
\Bigg.
\Bigg]
\begin{array}{l}
\end{array}
\Bigg.
/\sqrt{d_k}
a_{11}
a_{14}
a_{12}
a_{13}
v_4
v_2
v_3
v_1
a_{11}
a_{14}
a_{12}
a_{13}
=
x_1
x_2
x_3
x_4
z_1
\left\{
\begin{array}{l}
\\
\\
\end{array}
\right.
d_k
To
date
the
cleverest
for numerical stability
v_1
k_1
q_1
v_2
k_2
q_2
v_3
k_3
q_3
v_4
q_4
k_4
v_4
v_4
v_4
q_1
q_1
q_1
q_1
q_1
k_1
k_2
k_3
k_4
softmax
\Bigg(
\begin{array}{l}
\end{array}
\Bigg.
\Bigg)
\begin{array}{l}
\end{array}
\Bigg.
,
,
,
\Bigg[
\begin{array}{l}
\end{array}
\Bigg.
\Bigg]
\begin{array}{l}
\end{array}
\Bigg.
/\sqrt{d_k}
=
v_4
v_2
v_3
v_1
+
+
+
=
a_{11}
a_{14}
a_{12}
a_{13}
a_{11}
a_{14}
a_{12}
a_{13}
x_1
x_2
x_3
x_4
z_1
\left\{
\begin{array}{l}
\\
\\
\end{array}
\right.
d_k
To
date
the
cleverest
v_1
k_1
q_1
v_2
k_2
q_2
v_3
k_3
q_3
v_4
q_4
k_4
v_4
v_4
v_4
q_1
q_2
q_2
q_2
q_2
k_1
k_2
k_3
k_4
attention mechanism
x_1
x_2
x_3
x_4
z_1
z_2
z_3
z_4
?
\left\{
\begin{array}{l}
\\
\\
\end{array}
\right.
d_k
To
date
the
cleverest
v_1
k_1
q_1
v_2
k_2
q_2
v_3
k_3
q_3
v_4
q_4
k_4
v_4
v_4
v_4
q_1
=
a_{21}
a_{24}
a_{22}
a_{23}
q_2
q_2
q_2
q_2
k_1
k_2
k_3
k_4
softmax
\Bigg(
\begin{array}{l}
\end{array}
\Bigg.
\Bigg)
\begin{array}{l}
\end{array}
\Bigg.
,
,
,
\Bigg[
\begin{array}{l}
\end{array}
\Bigg.
\Bigg]
\begin{array}{l}
\end{array}
\Bigg.
/\sqrt{d_k}
v_4
v_2
v_3
v_1
a_{21}
a_{24}
a_{22}
a_{23}
x_1
x_2
x_3
x_4
z_2
\left\{
\begin{array}{l}
\\
\\
\end{array}
\right.
d_k
To
date
the
cleverest
v_1
k_1
q_1
v_2
k_2
q_2
v_3
k_3
q_3
v_4
q_4
k_4
v_4
v_4
v_4
q_1
=
=
a_{21}
a_{24}
a_{22}
a_{23}
q_2
q_2
q_2
q_2
k_1
k_2
k_3
k_4
softmax
\Bigg(
\begin{array}{l}
\end{array}
\Bigg.
\Bigg)
\begin{array}{l}
\end{array}
\Bigg.
,
,
,
\Bigg[
\begin{array}{l}
\end{array}
\Bigg.
\Bigg]
\begin{array}{l}
\end{array}
\Bigg.
/\sqrt{d_k}
v_4
v_2
v_3
v_1
+
+
+
a_{21}
a_{24}
a_{22}
a_{23}
x_1
x_2
x_3
x_4
z_2
\left\{
\begin{array}{l}
\\
\\
\end{array}
\right.
d_k
To
date
the
cleverest
v_1
k_1
q_1
v_2
k_2
q_2
v_3
k_3
q_3
v_4
q_4
k_4
v_4
v_4
v_4
q_1
q_4
q_4
q_4
q_4
k_1
k_2
k_3
k_4
attention mechanism
x_1
x_2
x_3
x_4
z_1
z_2
z_4
z_3
?
\left\{
\begin{array}{l}
\\
\\
\end{array}
\right.
d_k
To
date
the
cleverest
v_1
k_1
q_1
v_2
k_2
q_2
v_3
k_3
q_3
v_4
q_4
k_4
v_4
v_4
v_4
q_1
=
a_{41}
a_{44}
a_{42}
a_{43}
q_4
q_4
q_4
q_4
k_1
k_2
k_3
k_4
softmax
\Bigg(
\begin{array}{l}
\end{array}
\Bigg.
\Bigg)
\begin{array}{l}
\end{array}
\Bigg.
,
,
,
\Bigg[
\begin{array}{l}
\end{array}
\Bigg.
\Bigg]
\begin{array}{l}
\end{array}
\Bigg.
/\sqrt{d_k}
v_1
v_2
v_3
v_4
a_{41}
a_{42}
a_{43}
a_{44}
x_1
x_2
x_3
x_4
z_4
parallel and structurally identical processing
can calculate \(z_4\) without \(z_3\)
\left\{
\begin{array}{l}
\\
\\
\end{array}
\right.
d_k
To
date
the
cleverest
v_1
k_1
q_1
v_2
k_2
q_2
v_3
k_3
q_3
v_4
q_4
k_4
v_4
v_4
v_4
q_1
=
a_{41}
a_{44}
a_{42}
a_{43}
q_4
q_4
q_4
q_4
k_1
k_2
k_3
k_4
softmax
\Bigg(
\begin{array}{l}
\end{array}
\Bigg.
\Bigg)
\begin{array}{l}
\end{array}
\Bigg.
,
,
,
\Bigg[
\begin{array}{l}
\end{array}
\Bigg.
\Bigg]
\begin{array}{l}
\end{array}
\Bigg.
/\sqrt{d_k}
=
v_2
v_3
v_1
v_4
+
+
+
a_{41}
a_{44}
a_{42}
a_{43}
x_1
x_2
x_3
x_4
z_4
\left\{
\begin{array}{l}
\\
\\
\end{array}
\right.
d_k
To
date
the
cleverest
v_1
k_1
q_1
v_2
k_2
q_2
v_3
k_3
q_3
v_4
q_4
k_4
v_4
v_4
v_4
q_1
q_3
q_3
q_3
q_3
k_1
k_2
k_3
k_4
attention mechanism
x_1
x_2
x_3
x_4
z_1
z_2
z_3
?
z_4
\left\{
\begin{array}{l}
\\
\\
\end{array}
\right.
d_k
To
date
the
cleverest
v_1
k_1
q_1
v_2
k_2
q_2
v_3
k_3
q_3
v_4
q_4
k_4
v_4
v_4
v_4
q_1
=
a_{31}
a_{34}
a_{32}
a_{3 3}
q_3
q_3
q_3
q_3
k_1
k_2
k_3
k_4
softmax
\Bigg(
\begin{array}{l}
\end{array}
\Bigg.
\Bigg)
\begin{array}{l}
\end{array}
\Bigg.
,
,
,
\Bigg[
\begin{array}{l}
\end{array}
\Bigg.
\Bigg]
\begin{array}{l}
\end{array}
\Bigg.
/\sqrt{d_k}
v_4
v_2
v_3
v_1
a_{31}
a_{34}
a_{32}
a_{33}
x_1
x_2
x_3
x_4
z_3
\left\{
\begin{array}{l}
\\
\\
\end{array}
\right.
d_k
To
date
the
cleverest
v_1
k_1
q_1
v_2
k_2
q_2
v_3
k_3
q_3
v_4
q_4
k_4
v_4
v_4
v_4
q_1
=
=
a_{31}
a_{34}
a_{32}
a_{3 3}
q_3
q_3
q_3
q_3
k_1
k_2
k_3
k_4
softmax
\Bigg(
\begin{array}{l}
\end{array}
\Bigg.
\Bigg)
\begin{array}{l}
\end{array}
\Bigg.
,
,
,
\Bigg[
\begin{array}{l}
\end{array}
\Bigg.
\Bigg]
\begin{array}{l}
\end{array}
\Bigg.
/\sqrt{d_k}
v_4
v_2
v_3
v_1
+
+
+
a_{31}
a_{34}
a_{32}
a_{33}
x_1
x_2
x_3
x_4
z_3
\left\{
\begin{array}{l}
\\
\\
\end{array}
\right.
d_k
To
date
the
cleverest
v_1
k_1
q_1
v_2
k_2
q_2
v_3
k_3
q_3
v_4
q_4
k_4
v_4
v_4
attention mechanism
x_1
x_2
x_3
x_4
z_1
z_2
z_3
z_4
maps sequence of \(x\) to sequence of \(z\):
1. (query, key, value) projection
2. attention mechanism
parallel and structurally identical processing
W_k
W_v
W_q
W_k
W_v
W_q
W_k
W_v
W_q
W_k
W_v
W_q
Attention head
Attention head - compact matrix form
By stacking each individual vector in the sequence as a row
\Longleftrightarrow
To
date
the
cleverest
input embedding
output embedding
\(\dots\)
transformer block
transformer block
transformer block
x_1
x_2
x_3
x_4
A sequence of \(n\) tokens, each token in \(\mathbb{R}^{d}\)
\(\dots\)
\(\dots\)
\(\dots\)
\(\dots\)
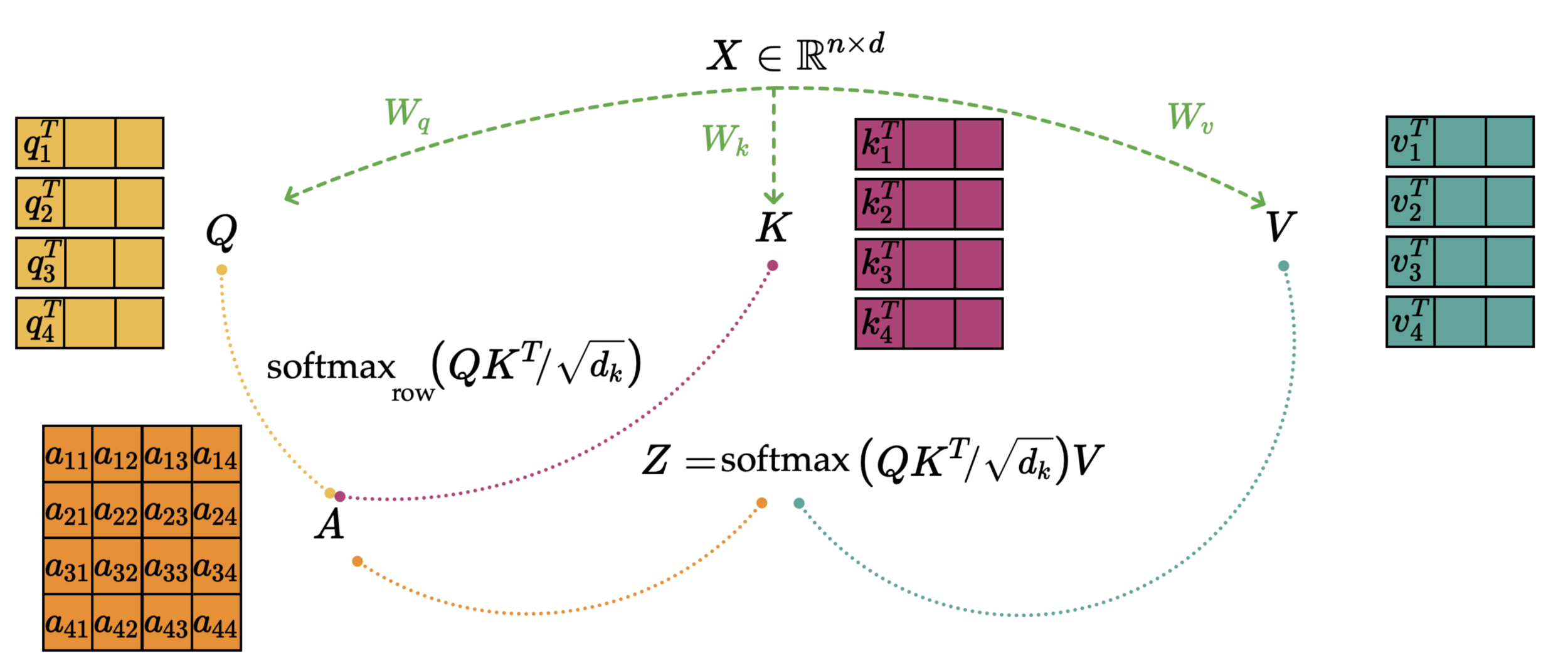
X \in \mathbb{R}^{n \times d}
Stack each token as a row in the input
v_1^T
v_2^T
v_3^T
v_4^T
\in \mathbb{R}^{d \times d_k}
W_q
W_k
W_v
X \in \mathbb{R}^{n \times d}
Q = XW_q \in \mathbb{R}^{n \times d_k}
K = XW_k \in \mathbb{R}^{n \times d_k}
V = XW_v \in \mathbb{R}^{n \times d_k}
1. (query, key, value) projection
q_4^T
q_1^T
q_2^T
q_3^T
k_2^T
k_1^T
k_3^T
k_4^T
\in \mathbb{R}^{d \times d_k}
\in \mathbb{R}^{d \times d_k}
v_1^T
v_2^T
v_3^T
v_4^T
W_q
W_k
W_v
X
Q
K
V
q_4^T
q_1^T
q_2^T
q_3^T
k_2^T
k_1^T
k_3^T
k_4^T
2a. dot-product similarity
compare \(q_i\) and \(k_j\)
assemble the \(n \times n\) similarities so rows correspond to query
q_4^T
q_1^T
q_2^T
q_3^T
Q
K
v_1^T
v_2^T
v_3^T
v_4^T
V
W_q
W_k
W_v
X \in \mathbb{R}^{n \times d}
2a. dot-product similarity
q_1^{T}k_3
k_2^T
k_4^T
q_4^T
q_2^T
q_3^T
k_4^T
k_2^T
k_1^T
k_1^T
k_3^T
q_4^T
q_1^T
q_2^T
q_3^T
v_1^T
v_2^T
v_3^T
v_4^T
W_q
W_k
W_v
X \in \mathbb{R}^{n \times d}
2a. dot-product similarity
q_3^{T}k_4
k_2^T
k_1^T
k_3^T
k_4^T
Q
K
V
W_q
W_k
W_v
X \in \mathbb{R}^{n \times d}
k_2^T
k_1^T
k_3^T
k_4^T
q_4^T
q_1^T
q_2^T
q_3^T
v_1^T
v_2^T
v_3^T
v_4^T
QK^T
\in \mathbb{R}^{n \times n}
2a. dot-product similarity
Q
K
V
A =
\left]
\begin{array}{l}
\\
\\
\\
\\
\\
\end{array}
\right.
a_{41}
a_{42}
a_{43}
a_{44}
=
a_{31}
a_{34}
a_{32}
a_{3 3}
a_{21}
a_{24}
a_{22}
a_{23}
a_{11}
a_{14}
a_{12}
a_{13}
\in \mathbb{R}^{n \times n}
each row sums up to 1
(
)
softmax
/\sqrt{d_k}
(
)
softmax
/\sqrt{d_k}
(
)
softmax
/\sqrt{d_k}
(
)
softmax
/\sqrt{d_k}
W_q
W_k
W_v
X \in \mathbb{R}^{n \times d}
k_2^T
k_1^T
k_3^T
k_4^T
q_4^T
q_1^T
q_2^T
q_3^T
v_1^T
v_2^T
v_3^T
v_4^T
\left[
\begin{array}{l}
\\
\\
\\
\\
\\
\end{array}
\right.
=
QK^T
/\sqrt{d_k}
softmax
(
)
row
\(A\)
2b. attention matrix
Q
K
V
a_{41}
a_{42}
a_{43}
a_{44}
a_{31}
a_{34}
a_{32}
a_{3 3}
a_{21}
a_{24}
a_{22}
a_{23}
a_{11}
a_{14}
a_{12}
a_{13}
W_q
W_k
W_v
X \in \mathbb{R}^{n \times d}
k_2^T
k_1^T
k_3^T
k_4^T
q_4^T
q_1^T
q_2^T
q_3^T
v_1^T
v_2^T
v_3^T
v_4^T
Z=AV=
2c. attention-weighted values \(Z\)
Q
K
V
A
QK^T
/\sqrt{d_k}
softmax
(
)
row
V
QK^T
/\sqrt{d_k}
softmax
(
)
row
or, often even more compactly
q_1
a_{41}
a_{42}
a_{43}
a_{44}
a_{31}
a_{34}
a_{32}
a_{3 3}
a_{21}
a_{24}
a_{22}
a_{23}
a_{11}
a_{14}
a_{12}
a_{13}
q_1
q_2
q_3
q_4
k_4
k_1
k_2
k_3
attention mechanism
x_1
x_2
x_3
x_4
attention scores depend on the (query, key) only
a_{41}
a_{42}
a_{43}
a_{44}
a_{31}
a_{34}
a_{32}
a_{3 3}
a_{21}
a_{24}
a_{22}
a_{23}
a_{11}
a_{14}
a_{12}
a_{13}
q_1
q_1
q_2
q_3
q_4
k_4
k_1
k_2
k_3
attention mechanism
\in \mathbb{R}^{d_k}
x_1
x_2
x_3
x_4
z_1
+
+
+
a_{11}
a_{14}
a_{12}
a_{13}
=
v_4
v_2
v_3
v_1
v_1
v_2
v_3
v_4
v_4
v_4
v_4
v_4
v_4
q_1
=
a_{41}
a_{42}
a_{43}
a_{44}
a_{31}
a_{34}
a_{32}
a_{3 3}
a_{21}
a_{24}
a_{22}
a_{23}
a_{11}
a_{14}
a_{12}
a_{13}
+
+
+
a_{21}
a_{24}
a_{22}
a_{23}
v_1
q_1
k_1
v_2
q_2
k_2
v_3
q_3
k_3
v_4
q_4
k_4
v_4
v_4
v_2
v_3
v_1
attention mechanism
\in \mathbb{R}^{d_k}
x_1
x_2
x_3
x_4
z_2
v_4
v_4
q_1
=
a_{41}
a_{42}
a_{43}
a_{44}
a_{31}
a_{34}
a_{32}
a_{3 3}
a_{21}
a_{24}
a_{22}
a_{23}
a_{11}
a_{14}
a_{12}
a_{13}
+
+
+
a_{31}
a_{34}
a_{32}
a_{33}
v_1
q_1
k_1
v_2
q_2
k_2
v_3
q_3
k_3
v_4
q_4
k_4
v_4
v_4
v_2
v_3
v_1
attention mechanism
x_1
x_2
x_3
x_4
z_3
\in \mathbb{R}^{d_k}
v_4
v_4
q_1
=
a_{41}
a_{42}
a_{43}
a_{44}
a_{31}
a_{34}
a_{32}
a_{3 3}
a_{21}
a_{24}
a_{22}
a_{23}
a_{11}
a_{14}
a_{12}
a_{13}
+
+
+
a_{41}
a_{44}
a_{42}
a_{43}
v_1
q_1
k_1
v_2
q_2
k_2
v_3
q_3
k_3
v_4
q_4
k_4
v_4
v_4
v_2
v_3
v_1
attention mechanism
\in \mathbb{R}^{d_k}
x_1
x_2
x_3
x_4
z_4
Outline
- Transformers high-level intuition and architecture
- Attention mechanism
- Multi-head attention
- (Applications)
z_1^1
z_2^1
z_3^1
z_4^1
W^1_k
W^1_v
W^1_q
v^1_1
k^1_1
q^1_1
W^1_k
W^1_v
W^1_q
v^1_2
k^1_2
q^1_2
W^1_k
W^1_v
W^1_q
W^1_k
W^1_v
W^1_q
v^1_3
k^1_3
q^1_3
q^1_4
k^1_4
v^1_4
attention mechanism
x_1
x_2
x_3
x_4
z_1^1
z_2^1
z_3^1
z_4^1
W^1_k
W^1_v
W^1_q
v^1_1
k^1_1
q^1_1
W^1_k
W^1_v
W^1_q
v^1_2
k^1_2
q^1_2
W^1_k
W^1_v
W^1_q
W^1_k
W^1_v
W^1_q
v^1_3
k^1_3
q^1_3
q^1_4
k^1_4
v^1_4
attention mechanism
z_1^2
z_2^2
z_3^2
z_4^2
W^2_k
W^2_v
W^2_q
v^2_1
k^2_1
q^2_1
W^2_k
W^2_v
W^2_q
v^2_2
k^2_2
q^2_2
W^2_k
W^2_v
W^2_q
W^2_k
W^2_v
W^2_q
v^2_3
k^2_3
q^2_3
q^2_4
k^2_4
v^2_4
attention mechanism
x_1
x_2
x_3
x_4
x_1
x_2
x_3
x_4
z_1^1
z_2^1
z_3^1
z_4^1
W^1_k
W^1_v
W^1_q
v^1_1
k^1_1
q^1_1
W^1_k
W^1_v
W^1_q
v^1_2
k^1_2
q^1_2
W^1_k
W^1_v
W^1_q
W^1_k
W^1_v
W^1_q
v^1_3
k^1_3
q^1_3
q^1_4
k^1_4
v^1_4
attention mechanism
z_1^2
z_2^2
z_3^2
z_4^2
W^2_k
W^2_v
W^2_q
v^2_1
k^2_1
q^2_1
W^2_k
W^2_v
W^2_q
v^2_2
k^2_2
q^2_2
W^2_k
W^2_v
W^2_q
W^2_k
W^2_v
W^2_q
v^2_3
k^2_3
q^2_3
q^2_4
k^2_4
v^2_4
attention mechanism
z_1^3
z_2^3
z_3^3
z_4^3
W^3_k
W^3_v
W^3_q
v^3_1
k^3_1
q^3_1
W^3_k
W^3_v
W^3_q
v^3_2
k^3_2
q^3_2
W^3_k
W^3_v
W^3_q
W^3_k
W^3_v
W^3_q
v^3_3
k^3_3
q^3_3
q^3_4
k^3_4
v^3_4
attention mechanism
z_1^1
z_2^1
z_3^1
z_4^1
W^1_k
W^1_v
W^1_q
v^1_1
k^1_1
q^1_1
W^1_k
W^1_v
W^1_q
v^1_2
k^1_2
q^1_2
W^1_k
W^1_v
W^1_q
W^1_k
W^1_v
W^1_q
v^1_3
k^1_3
q^1_3
q^1_4
k^1_4
v^1_4
attention mechanism
z_1^2
z_2^2
z_3^2
z_4^2
W^2_k
W^2_v
W^2_q
v^2_1
k^2_1
q^2_1
W^2_k
W^2_v
W^2_q
v^2_2
k^2_2
q^2_2
W^2_k
W^2_v
W^2_q
W^2_k
W^2_v
W^2_q
v^2_3
k^2_3
q^2_3
q^2_4
k^2_4
v^2_4
attention mechanism
z_1^3
z_2^3
z_3^3
z_4^3
W^3_k
W^3_v
W^3_q
v^3_1
k^3_1
q^3_1
W^3_k
W^3_v
W^3_q
v^3_2
k^3_2
q^3_2
W^3_k
W^3_v
W^3_q
W^3_k
W^3_v
W^3_q
v^3_3
k^3_3
q^3_3
q^3_4
k^3_4
v^3_4
attention mechanism
\dots
x_1
x_2
x_3
x_4
z_1^1
z_2^1
z_3^1
z_4^1
W^1_k
W^1_v
W^1_q
v^1_1
k^1_1
q^1_1
W^1_k
W^1_v
W^1_q
v^1_2
k^1_2
q^1_2
W^1_k
W^1_v
W^1_q
W^1_k
W^1_v
W^1_q
v^1_3
k^1_3
q^1_3
q^1_4
k^1_4
v^1_4
attention mechanism
z_1^2
z_2^2
z_3^2
z_4^2
W^2_k
W^2_v
W^2_q
v^2_1
k^2_1
q^2_1
W^2_k
W^2_v
W^2_q
v^2_2
k^2_2
q^2_2
W^2_k
W^2_v
W^2_q
W^2_k
W^2_v
W^2_q
v^2_3
k^2_3
q^2_3
q^2_4
k^2_4
v^2_4
attention mechanism
z_1^3
z_2^3
z_3^3
z_4^3
W^3_k
W^3_v
W^3_q
v^3_1
k^3_1
q^3_1
W^3_k
W^3_v
W^3_q
v^3_2
k^3_2
q^3_2
W^3_k
W^3_v
W^3_q
W^3_k
W^3_v
W^3_q
v^3_3
k^3_3
q^3_3
q^3_4
k^3_4
v^3_4
attention mechanism
z_1^H
z_2^H
z_3^H
z_4^H
W^H_k
W^H_v
W^H_q
v^H_1
k^H_1
q^H_1
W^H_k
W^H_v
W^H_q
v^H_2
k^H_2
q^H_2
W^H_k
W^H_v
W^H_q
W^H_k
W^H_v
W^H_q
v^H_3
k^H_3
q^H_3
q^H_4
k^H_4
v^H_4
attention mechanism
\dots
x_1
x_2
x_3
x_4
In particular, each head:
- learns its own set of \(W_q, W_k, W_v\)
- creates its own projected sequence of \((q,k,v)\)
- computes its own sequence of \(z\)
- structurally identical processing
- for each token in the sequence:
- structurally identical processing
Parallel, and structurally identical processing across all heads and tokens.
Multi-head Attention
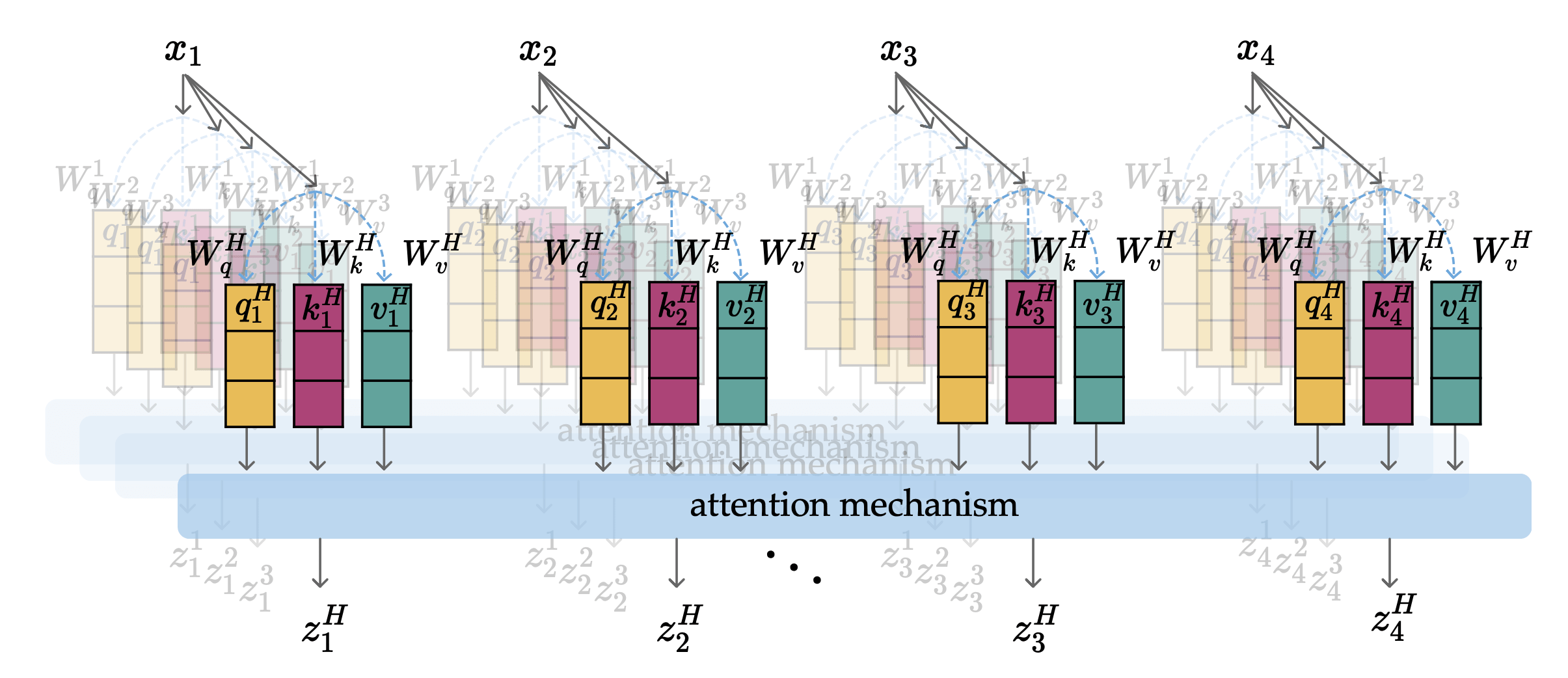
index along heads
index along sequence
\dots
x_1
x_2
x_3
x_4
concatenated as \(z_1\)
\left\{
\begin{array}{l}
\\
\\
\end{array}
\right.
concatenated as \(z_2\)
\left\{
\begin{array}{l}
\\
\\
\end{array}
\right.
concatenated as \(z_3\)
\left\{
\begin{array}{l}
\\
\\
\end{array}
\right.
concatenated as \(z_4\)
each concatenated \(z_i \in \mathbb{R}^{Hd_k}\)
W^1_k
W^1_v
W^1_q
v^1_1
k^1_1
q^1_1
W^1_k
W^1_v
W^1_q
v^1_2
k^1_2
q^1_2
W^1_k
W^1_v
W^1_q
W^1_k
W^1_v
W^1_q
v^1_3
k^1_3
q^1_3
q^1_4
k^1_4
v^1_4
attention mechanism
z_1^1
z_2^1
z_3^1
z_4^1
W^2_k
W^2_v
W^2_q
v^2_1
k^2_1
q^2_1
W^2_k
W^2_v
W^2_q
v^2_2
k^2_2
q^2_2
W^2_k
W^2_v
W^2_q
W^2_k
W^2_v
W^2_q
v^2_3
k^2_3
q^2_3
q^2_4
k^2_4
v^2_4
attention mechanism
z_1^2
z_2^2
z_3^2
z_4^2
W^3_k
W^3_v
W^3_q
v^3_1
k^3_1
q^3_1
W^3_k
W^3_v
W^3_q
v^3_2
k^3_2
q^3_2
W^3_k
W^3_v
W^3_q
W^3_k
W^3_v
W^3_q
v^3_3
k^3_3
q^3_3
q^3_4
k^3_4
v^3_4
attention mechanism
z_1^3
z_2^3
z_3^3
z_4^3
W^H_k
W^H_v
W^H_q
v^H_1
k^H_1
q^H_1
W^H_k
W^H_v
W^H_q
v^H_2
k^H_2
q^H_2
W^H_k
W^H_v
W^H_q
W^H_k
W^H_v
W^H_q
v^H_3
k^H_3
q^H_3
q^H_4
k^H_4
v^H_4
attention mechanism
z_1^H
z_2^H
z_3^H
z_4^H
\left\{
\begin{array}{l}
\\
\\
\end{array}
\right.
z_1^1
z_2^1
z_3^1
z_4^1
W^1_k
W^1_v
W^1_q
v^1_1
k^1_1
q^1_1
W^1_k
W^1_v
W^1_q
v^1_2
k^1_2
q^1_2
W^1_k
W^1_v
W^1_q
W^1_k
W^1_v
W^1_q
v^1_3
k^1_3
q^1_3
q^1_4
k^1_4
v^1_4
attention mechanism
z_1^2
z_2^2
z_3^2
z_4^2
W^2_k
W^2_v
W^2_q
v^2_1
k^2_1
q^2_1
W^2_k
W^2_v
W^2_q
v^2_2
k^2_2
q^2_2
W^2_k
W^2_v
W^2_q
W^2_k
W^2_v
W^2_q
v^2_3
k^2_3
q^2_3
q^2_4
k^2_4
v^2_4
attention mechanism
z_1^3
z_2^3
z_3^3
z_4^3
W^3_k
W^3_v
W^3_q
v^3_1
k^3_1
q^3_1
W^3_k
W^3_v
W^3_q
v^3_2
k^3_2
q^3_2
W^3_k
W^3_v
W^3_q
W^3_k
W^3_v
W^3_q
v^3_3
k^3_3
q^3_3
q^3_4
k^3_4
v^3_4
attention mechanism
z_1^H
z_2^H
z_3^H
z_4^H
W^H_k
W^H_v
W^H_q
v^H_1
k^H_1
q^H_1
W^H_k
W^H_v
W^H_q
v^H_2
k^H_2
q^H_2
W^H_k
W^H_v
W^H_q
W^H_k
W^H_v
W^H_q
v^H_3
k^H_3
q^H_3
q^H_4
k^H_4
v^H_4
attention mechanism
\dots
x_1
x_2
x_3
x_4
\left\{
\begin{array}{l}
\\
\\
\end{array}
\right.
\left\{
\begin{array}{l}
\\
\\
\end{array}
\right.
\left\{
\begin{array}{l}
\\
\\
\end{array}
\right.
\left\{
\begin{array}{l}
\\
\\
\end{array}
\right.
W^o
attention output projection
\in \mathbb{R}^{Hd_k\times d}
z_{\text{out}_1}
z_{\text{out}_2}
z_{\text{out}_3}
z_{\text{out}_4}
z_1^1
z_2^1
z_3^1
z_4^1
W^1_k
W^1_v
W^1_q
v^1_1
k^1_1
q^1_1
W^1_k
W^1_v
W^1_q
v^1_2
k^1_2
q^1_2
W^1_k
W^1_v
W^1_q
W^1_k
W^1_v
W^1_q
v^1_3
k^1_3
q^1_3
q^1_4
k^1_4
v^1_4
attention mechanism
z_1^2
z_2^2
z_3^2
z_4^2
W^2_k
W^2_v
W^2_q
v^2_1
k^2_1
q^2_1
W^2_k
W^2_v
W^2_q
v^2_2
k^2_2
q^2_2
W^2_k
W^2_v
W^2_q
W^2_k
W^2_v
W^2_q
v^2_3
k^2_3
q^2_3
q^2_4
k^2_4
v^2_4
attention mechanism
z_1^3
z_2^3
z_3^3
z_4^3
W^3_k
W^3_v
W^3_q
v^3_1
k^3_1
q^3_1
W^3_k
W^3_v
W^3_q
v^3_2
k^3_2
q^3_2
W^3_k
W^3_v
W^3_q
W^3_k
W^3_v
W^3_q
v^3_3
k^3_3
q^3_3
q^3_4
k^3_4
v^3_4
attention mechanism
z_1^H
z_2^H
z_3^H
z_4^H
W^H_k
W^H_v
W^H_q
v^H_1
k^H_1
q^H_1
W^H_k
W^H_v
W^H_q
v^H_2
k^H_2
q^H_2
W^H_k
W^H_v
W^H_q
W^H_k
W^H_v
W^H_q
v^H_3
k^H_3
q^H_3
q^H_4
k^H_4
v^H_4
attention mechanism
\dots
x_1
x_2
x_3
x_4
\left\{
\begin{array}{l}
\\
\\
\end{array}
\right.
\left\{
\begin{array}{l}
\\
\\
\end{array}
\right.
\left\{
\begin{array}{l}
\\
\\
\end{array}
\right.
\left\{
\begin{array}{l}
\\
\\
\end{array}
\right.
W^o
attention output projection
\in \mathbb{R}^{Hd_k\times d}
z_{\text{out}_1}
z_{\text{out}_2}
z_{\text{out}_3}
z_{\text{out}_4}
all in \(\mathbb{R}^{d}\)
multi-head attention
Shape Example:
\(W\)s are the learned weights
\(n\)
num tokens
5
\(d\)
word-embedding dim
6
\(X\)
input
\(n \times d\)
\(5 \times 6\)
\(W_q^h\)
query proj
\(d \times d_k\)
\(6 \times 3\)
\(W_k^h\)
key proj
\(d \times d_k\)
\(6 \times 3\)
\(W_v^h\)
value proj
\(d \times d_k\)
\(6 \times 3\)
\(Q^h\)
query
\(n \times d_k\)
\(5 \times 3\)
\(K^h\)
key
\(n \times d_k\)
\(5 \times 3\)
\(V^h\)
value
\(n \times d_k\)
\(5 \times 3\)
\(A^h\)
attn matrix
\(n \times n\)
\(5 \times 5\)
\(Z^h\)
attn head out
\(n \times d_k\)
\(5 \times 3\)
for a single
attention head
\left\{
\begin{array}{l}
\\
\\
\\
\\
\\
\\
\end{array}
\right.
\(H\)
num heads
2
\(\text{concat}(Z^1 \dots Z^H)\)
multi-head out
\(n \times Hd_k\)
\(5 \times 6\)
\(W^o\)
output proj
\(Hd_k \times d\)
\(6 \times 6\)
\(Z_{\text{out}}\)
attn layer out
\(n \times d\)
\(5 \times 6\)
\(d_k\)
\((qkv)\)-embedding dim
3
Some practical techniques commonly needed when training auto-regressive transformers:


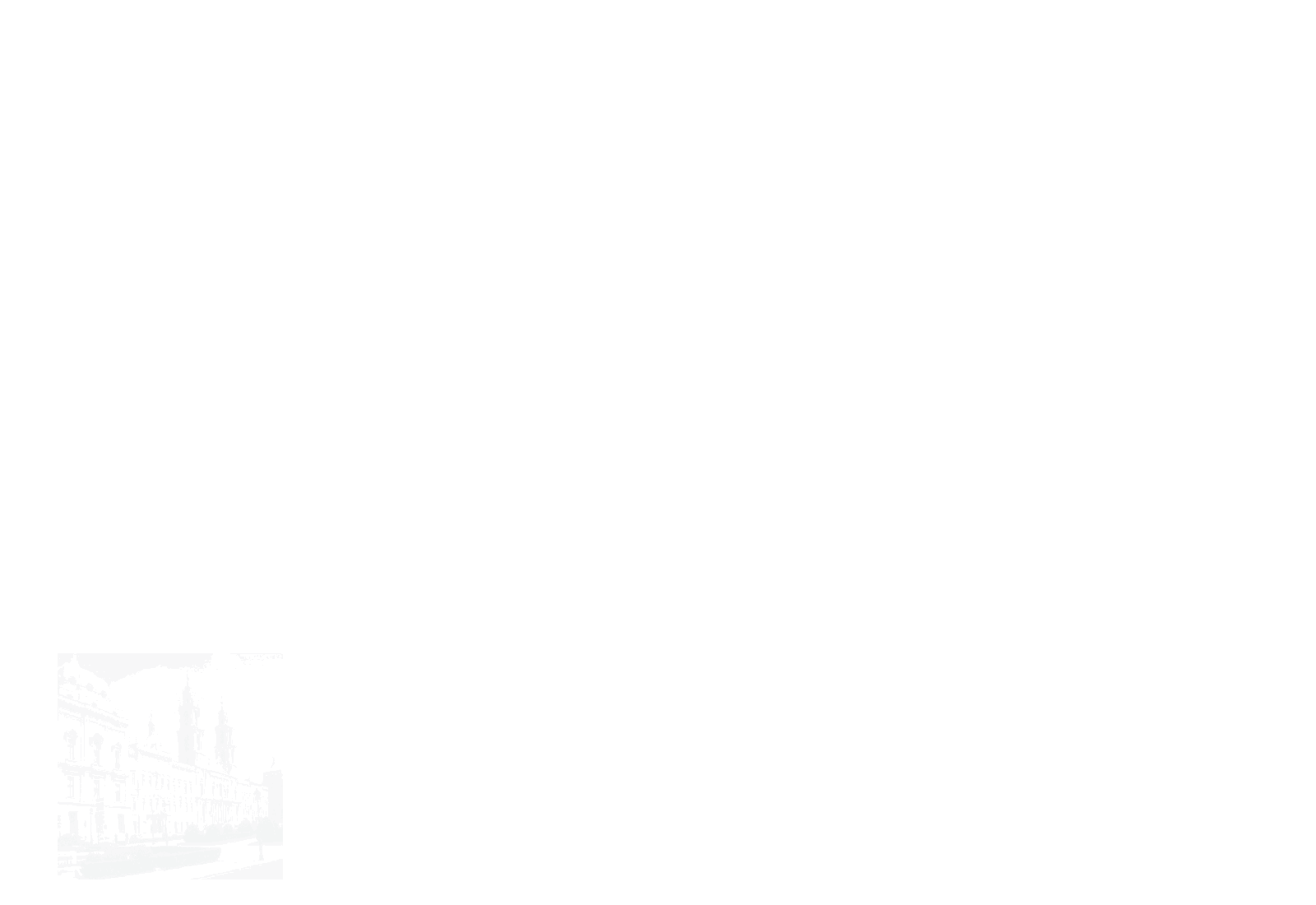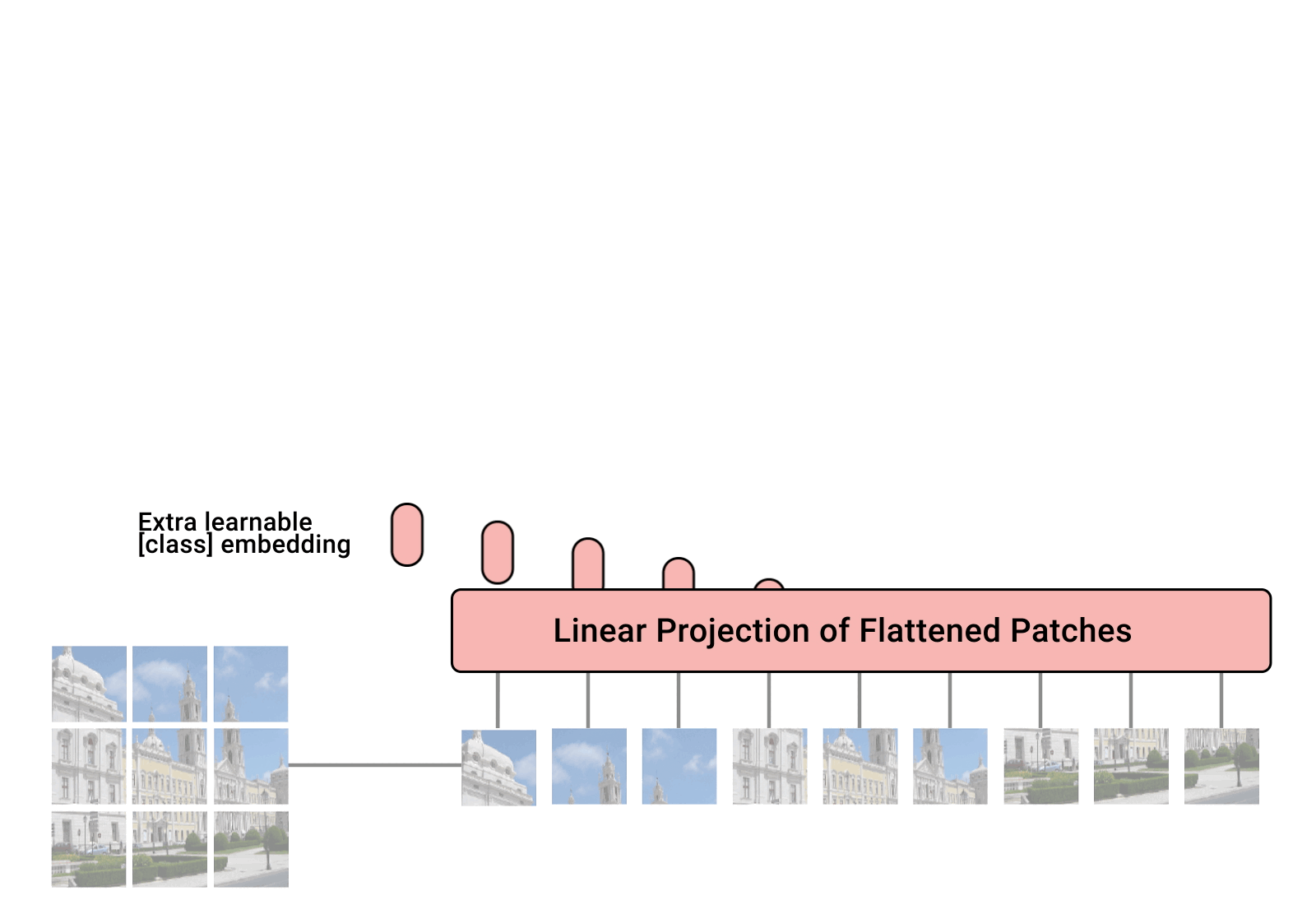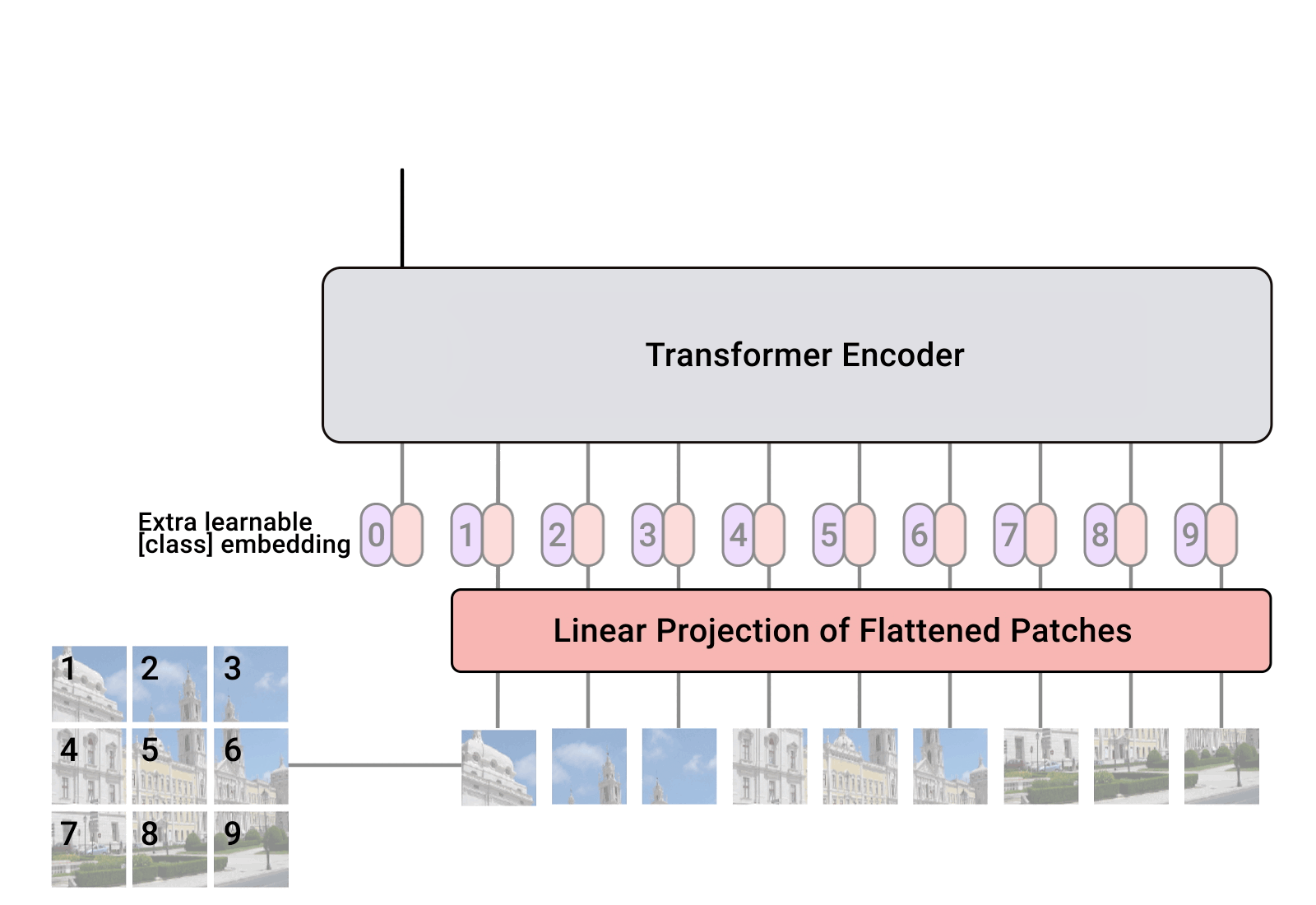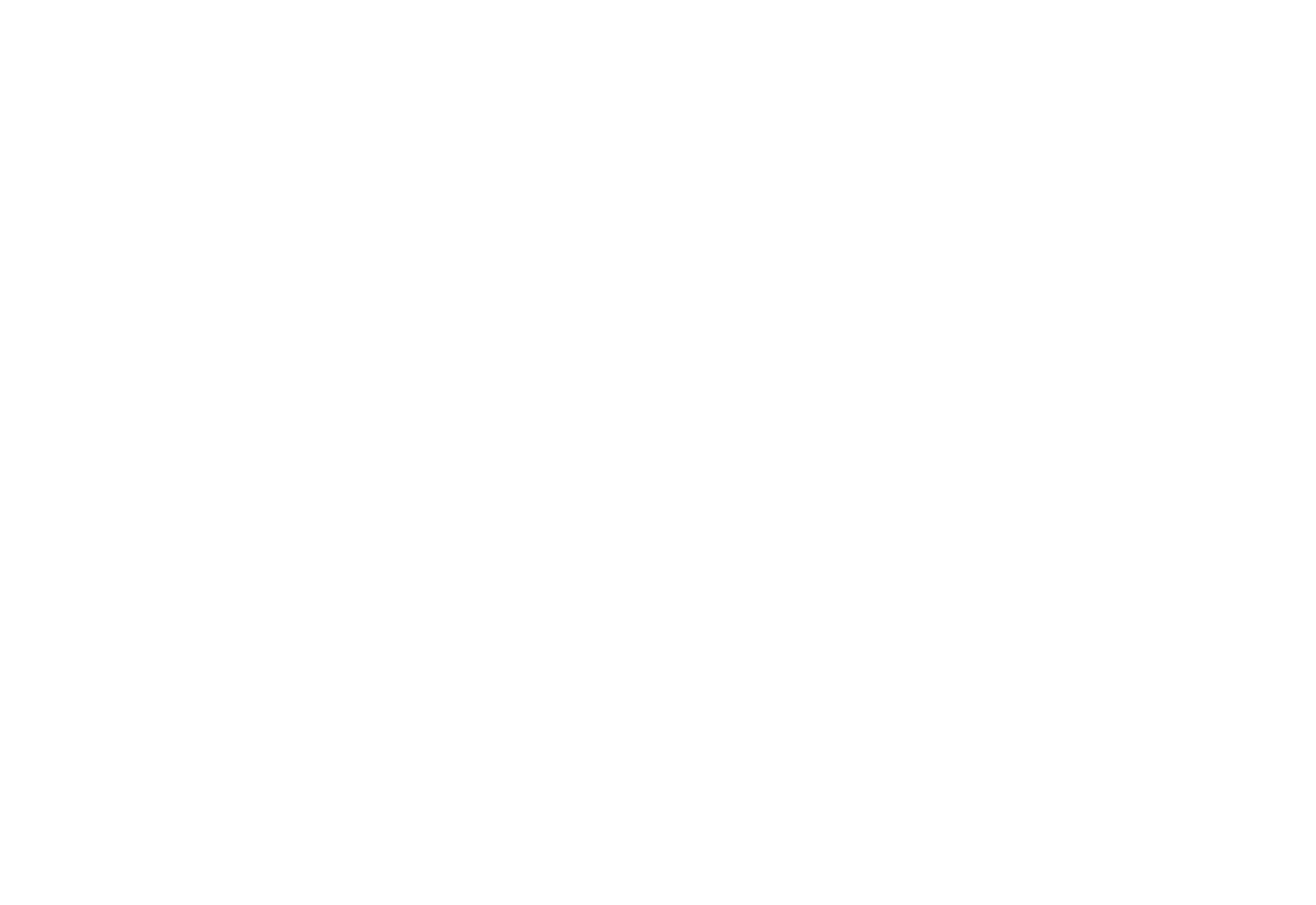
masking
Layer normalization
Residual connection
Positional encoding
Outline
- Transformers high-level intuition and architecture
- Attention mechanism
- Multi-head attention
- (Applications)
image credit: Nicholas Pfaff

Generative Boba by Boyuan Chen in Bldg 45
😉
😉
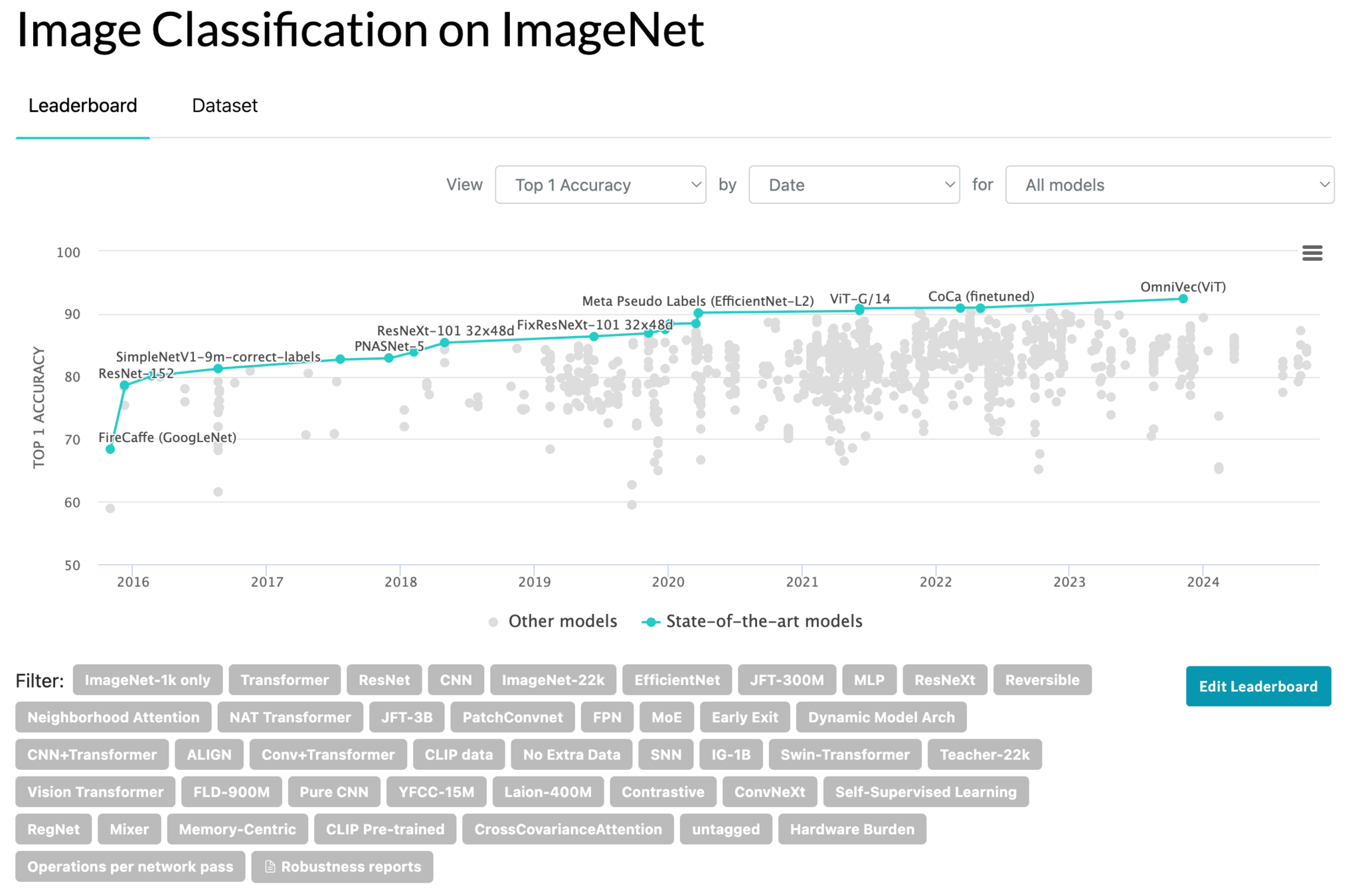
Transformers in Action: Performance across domains
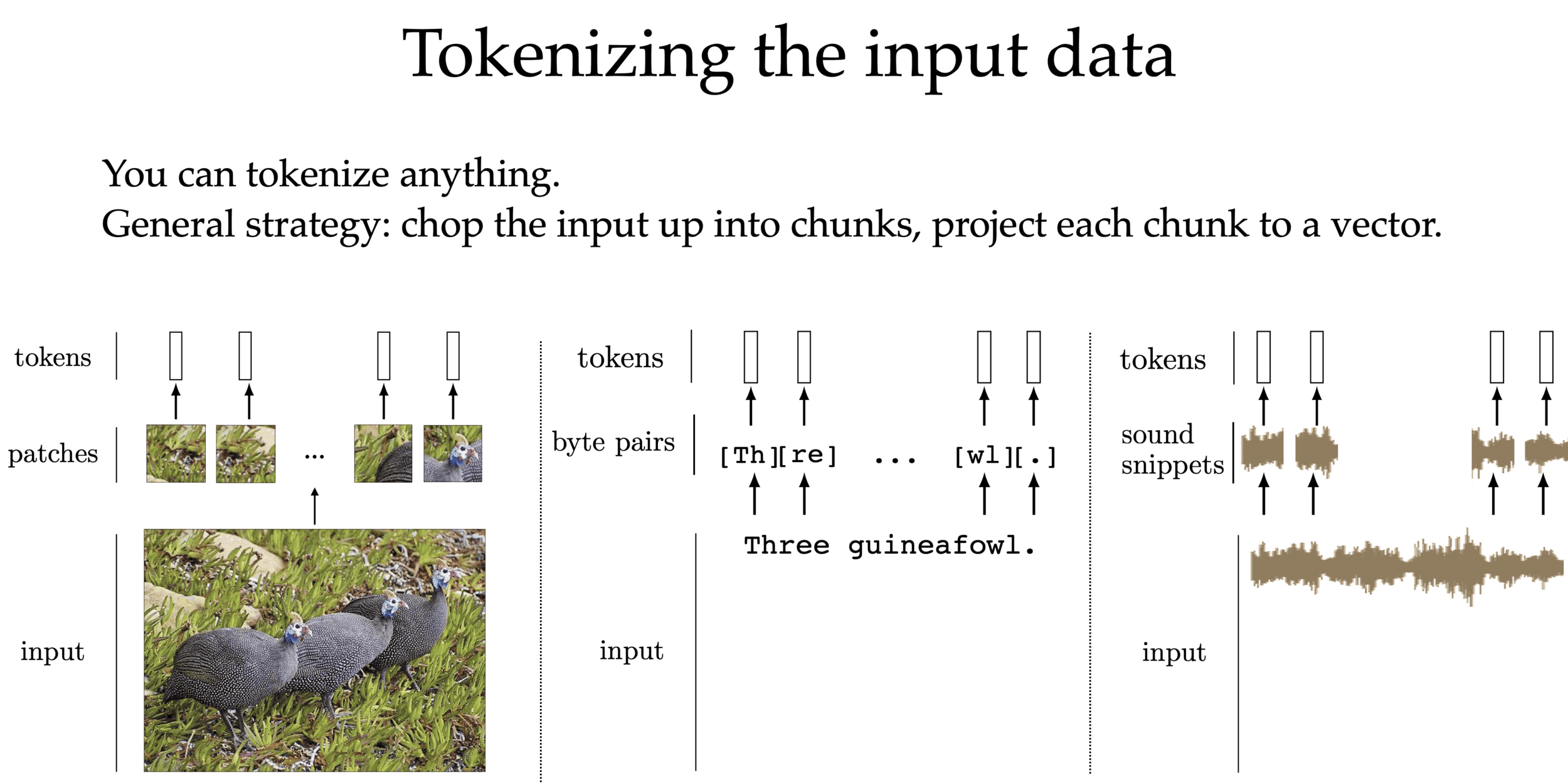
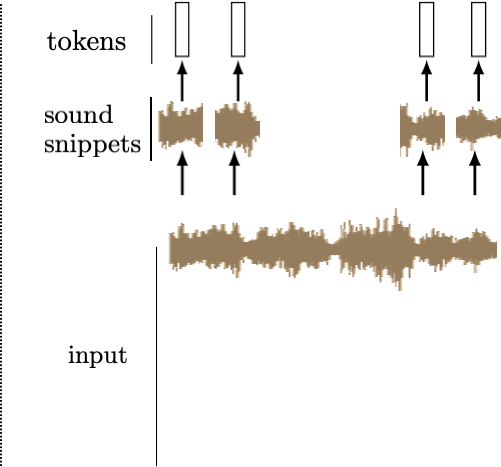
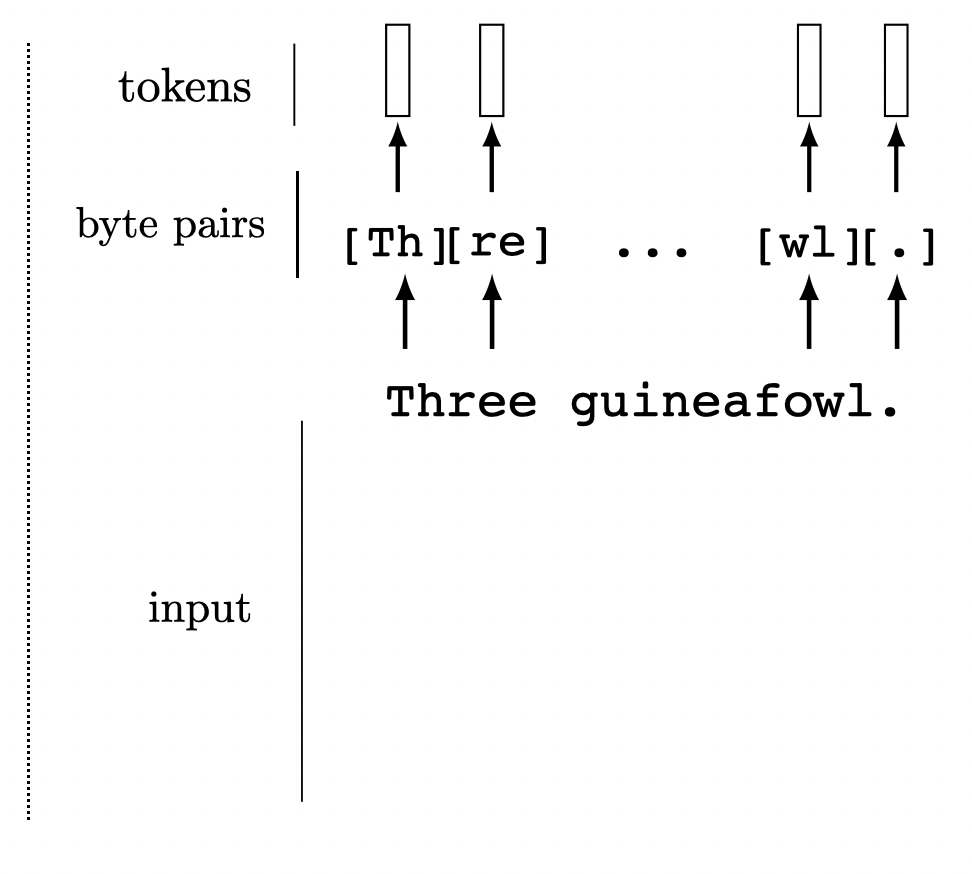
We can tokenize anything.
General strategy: chop the input up into chunks, project each chunk to an embedding
[images credit: visionbook.mit.edu]
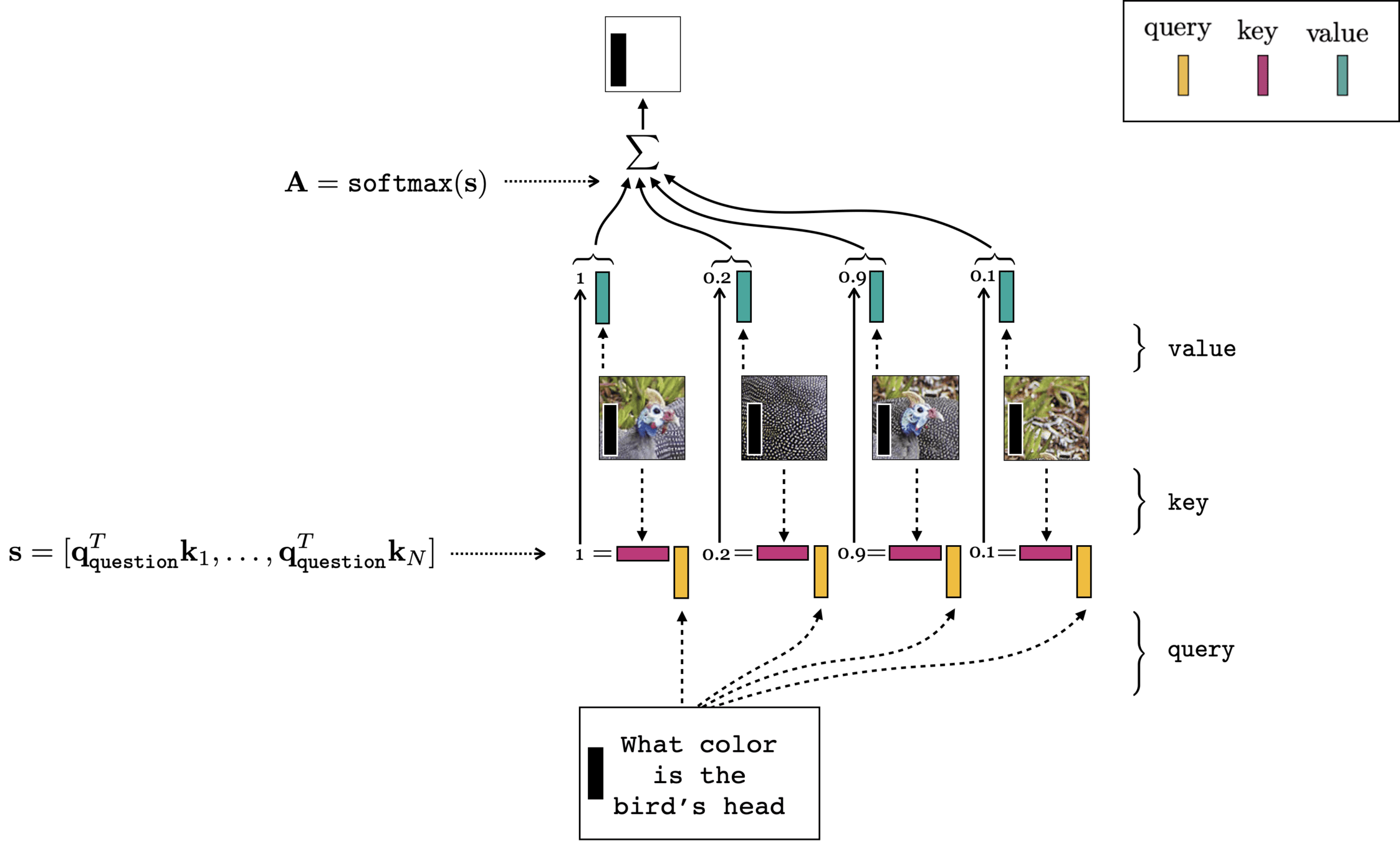
Multi-modality (image q&a)
- (query, key, value) come from different input modality
- cross-attention
[images credit: visionbook.mit.edu]

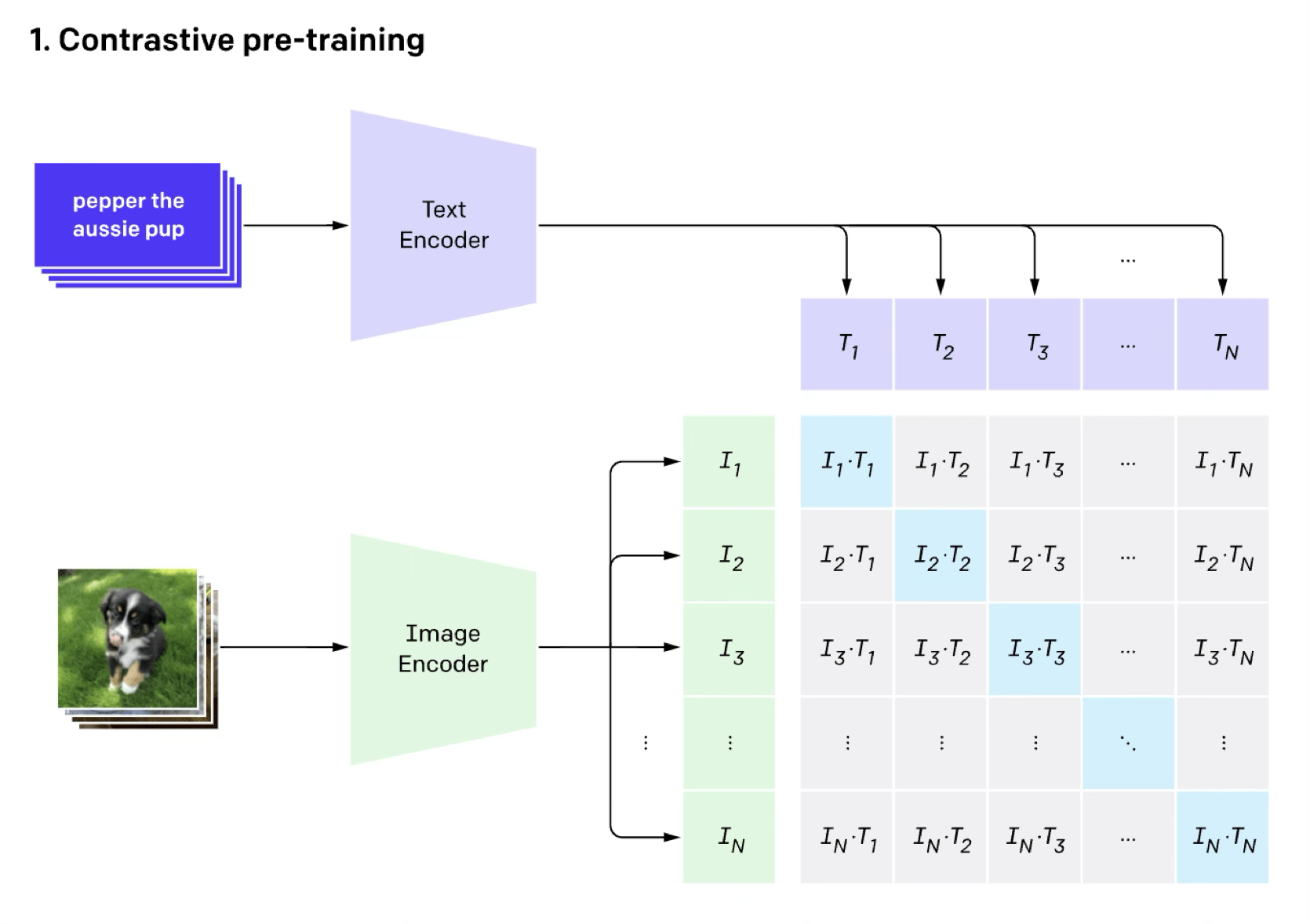
image classification (done in the contrastive way)
[Radford et al, Learning Transferable Visual Models From Natural Language Supervision, ICML, 2011]



[“DINO”, Caron et all. 2021]
Success mode:
Success mode:
[Show, Attend and Tell: Neural Image Caption Generation with Visual Attention. Xu et al. CVPR (2016)]

Failure mode:

[Show, Attend and Tell: Neural Image Caption Generation with Visual Attention. Xu et al. CVPR (2016)]


Success or Failure? mode:
Summary
Transformers combine ideas from earlier architectures (convolution, ReLU, residual connections) with new innovations: embedding and attention layers.
Transformers start with generic hard-coded embeddings and, block-by-block, create increasingly context-aware embeddings.
Attention enables massive parallelism: each head, each \(q,k,v\) sequence, each attention score, and each output are all computed in parallel.
(Because the architecture is input-agnostic — "attention is all you need" — transformers have become one model that rules across language, vision, and multi-modal tasks.)
6.390 IntroML (Spring26) - Lecture 9 Transformers
By Shen Shen




