Motion Sets for Contact-Rich Manipulation
What is sensitivity analysis really?
\begin{aligned}
\min_x \quad & \frac{1}{2}x^\top \mathbf{Q} x + q^\top x \\
\text{s.t.}\quad & \mathbf{A}x \leq b
\end{aligned}
\begin{aligned}
\mathbf{Q}x^\star + q + {\lambda^\star}^\top \mathbf{A} & = 0 \\
\mathbf{A}x^\star & \leq b \\
\lambda^\star & \geq 0 \\
{\lambda^\star}^\top(\mathbf{A}x^\star - b) & = 0
\end{aligned}
Consider a simple QP, we want the gradient of optimal solution w.r.t. parameters,
and it's KKT conditions
\begin{aligned}
\frac{\partial x^\star}{\partial q}
\end{aligned}
As we perturb q, the optimal solution changes to preserve the equality constraints in KKT.
\begin{aligned}
{\color{red} \frac{d }{dq}}
\end{aligned}
\begin{aligned}
{\color{red} \frac{d }{dq}}
\end{aligned}
What is sensitivity analysis really?
\begin{aligned}
\min_x \quad & \frac{1}{2}x^\top \mathbf{Q} x + q^\top x \\
\text{s.t.}\quad & \mathbf{A}x \leq b
\end{aligned}
\begin{aligned}
\mathbf{Q}x^\star + q + {\lambda^\star}^\top \mathbf{A} & = 0 \\
\mathbf{A}x^\star & \leq b \\
\lambda^\star & \geq 0 \\
{\lambda^\star}^\top(\mathbf{A}x^\star - b) & = 0
\end{aligned}
Consider a simple QP, we want the gradient of optimal solution w.r.t. parameters,
and it's KKT conditions
\begin{aligned}
\frac{\partial x^\star}{\partial q}
\end{aligned}
Differentiate the Equalities w.r.t. q
\begin{aligned}
\begin{bmatrix}
\mathbf{Q} & \mathbf{A}^\top \\
\text{D}(\lambda^\star) \mathbf{A} & \text{D}(\mathbf{A}x^\star - b)
\end{bmatrix}
\begin{bmatrix}
\frac{\partial x^\star}{\partial q} \\
\frac{\partial \lambda^\star}{\partial q} \\
\end{bmatrix} =
\begin{bmatrix} -1 \\ 0 \end{bmatrix}
\end{aligned}

\begin{aligned}
{\color{red} \frac{d }{dq}}
\end{aligned}
\begin{aligned}
{\color{red} \frac{d }{dq}}
\end{aligned}
What is sensitivity analysis really?
\begin{aligned}
\min_x \quad & \frac{1}{2}x^\top \mathbf{Q} x + q^\top x \\
\text{s.t.}\quad & \mathbf{A}x \leq b
\end{aligned}
\begin{aligned}
\mathbf{Q}x^\star + q + {\lambda^\star}^\top \mathbf{A} & = 0 \\
\mathbf{A}x^\star & \leq b \\
\lambda^\star & \geq 0 \\
{\lambda^\star}^\top(\mathbf{A}x^\star - b) & = 0
\end{aligned}
Consider a simple QP, we want the gradient of optimal solution w.r.t. parameters,
and it's KKT conditions
\begin{aligned}
\frac{\partial x^\star}{\partial q}
\end{aligned}
Throw away inactive constraints and linsolve.
Limitations of Sensitivity Analysis
\begin{aligned}
{\color{red} \frac{d }{dq}}
\end{aligned}
\begin{aligned}
{\color{red} \frac{d }{dq}}
\end{aligned}
\begin{aligned}
\mathbf{Q}x^\star + q + {\lambda^\star}^\top \mathbf{A} & = 0 \\
\mathbf{A}x^\star & \leq b \\
\lambda^\star & \geq 0 \\
{\lambda^\star}^\top(\mathbf{A}x^\star - b) & = 0
\end{aligned}
1. Throws away inactive constraints
2. Throws away feasibility constraints
Gradients are "correct" but too local!
Remedy 1. Constraint Smoothing
\begin{aligned}
{\color{red} \frac{d }{dq}}
\end{aligned}
\begin{aligned}
{\color{red} \frac{d }{dq}}
\end{aligned}
\begin{aligned}
\mathbf{Q}x^\star + q + {\lambda^\star}^\top \mathbf{A} & = 0 \\
\mathbf{A}x^\star & \leq b \\
\lambda^\star & \geq 0 \\
{\lambda^\star}^\top(\mathbf{A}x^\star - b) & = {\color{red}\kappa}
\end{aligned}
1. Throws away inactive constraints
2. Throws away feasibility constraints
Gradients are "correct" but too local!
Numerous benefits to smoothing that we already know so far
But doesn't address the second issue with feasibility!
For most solvers, feasibility has to be handled with line search.
Remedy 2. Handling Inequalities
Connection between gradients and "best linear model" still generalizes.
\begin{aligned}
\min_x \quad & \frac{1}{2}x^\top \mathbf{Q} x + q^\top x \\
\text{s.t.}\quad & \mathbf{A}x \leq b
\end{aligned}
What's the best linear model that locally approximates xstar as a function of q?
Remedy 2. Handling Inequalities
Connection between gradients and "best linear model" still generalizes.
\begin{aligned}
\bar{x}^\star(q) \coloneqq x^\star(\bar{q}) + \frac{\partial x^\star}{\partial q}\bigg|_{q=\bar{q}} \delta q
\end{aligned}
\begin{aligned}
\min_x \quad & \frac{1}{2}x^\top \mathbf{Q} x + q^\top x \\
\text{s.t.}\quad & \mathbf{A}x \leq b
\end{aligned}
What's the best linear model that locally approximates xstar as a function of q?
IF we didn't have feasibility constraints, the answer is Taylor expansion
Connection between gradients and "best linear model" still generalizes.
\begin{aligned}
\bar{x}^\star(q) \coloneqq x^\star(\bar{q}) + \frac{\partial x^\star}{\partial q}\bigg|_{q=\bar{q}} \delta q
\end{aligned}
\begin{aligned}
\min_x \quad & \frac{1}{2}x^\top \mathbf{Q} x + q^\top x \\
\text{s.t.}\quad & \mathbf{A}x \leq b
\end{aligned}
What's the best linear model that locally approximates xstar as a function of q?
\begin{aligned}
\mathbf{Q}x^\star + q + {\lambda^\star}^\top \mathbf{A} & = 0 \\
\mathbf{A}x^\star & \leq b \\
\lambda^\star & \geq 0 \\
{\lambda^\star}^\top(\mathbf{A}x^\star - b) & = {\color{red}\kappa}
\end{aligned}
But not every direction of dq results in feasibility!
KKT Conditions
Remedy 2. Handling Inequalities
\begin{aligned}
\bar{x}^\star(q) \coloneqq x^\star(\bar{q}) + \frac{\partial x^\star}{\partial q}\bigg|_{q=\bar{q}} \delta q
\end{aligned}
\begin{aligned}
\mathbf{Q}x^\star + q + {\lambda^\star}^\top \mathbf{A} & = 0 \\
\mathbf{A}x^\star & \leq b \\
\lambda^\star & \geq 0 \\
{\lambda^\star}^\top(\mathbf{A}x^\star - b) & = {\color{red}\kappa}
\end{aligned}
Linearize the Inequalities to limit directions dq.
KKT Conditions
\begin{aligned}
\bar{\lambda}^\star(q) \coloneqq \lambda^\star(\bar{q}) + \frac{\partial \lambda^\star}{\partial q}\bigg|_{q=\bar{q}} \delta q
\end{aligned}
Set of locally "admissible" dq.
\begin{aligned}
\{\delta q \;\;|\;\; \mathbf{A}\bar{x}^\star(\delta q) \leq b, \;\;\bar{\lambda}^\star(\delta q) \geq 0\}
\end{aligned}
Remedy 2. Handling Inequalities
Wrench Set
\begin{aligned}
\mathcal{W}_\varepsilon = \{w | w = \sum_i \mathbf{J}^\top_{\mathsf{u}_i}\lambda_i, \lambda_i\in\mathcal{K}_i, \|\lambda\|_2\leq \varepsilon\}
\end{aligned}
Recall the "Wrench Set" from old grasping literature.
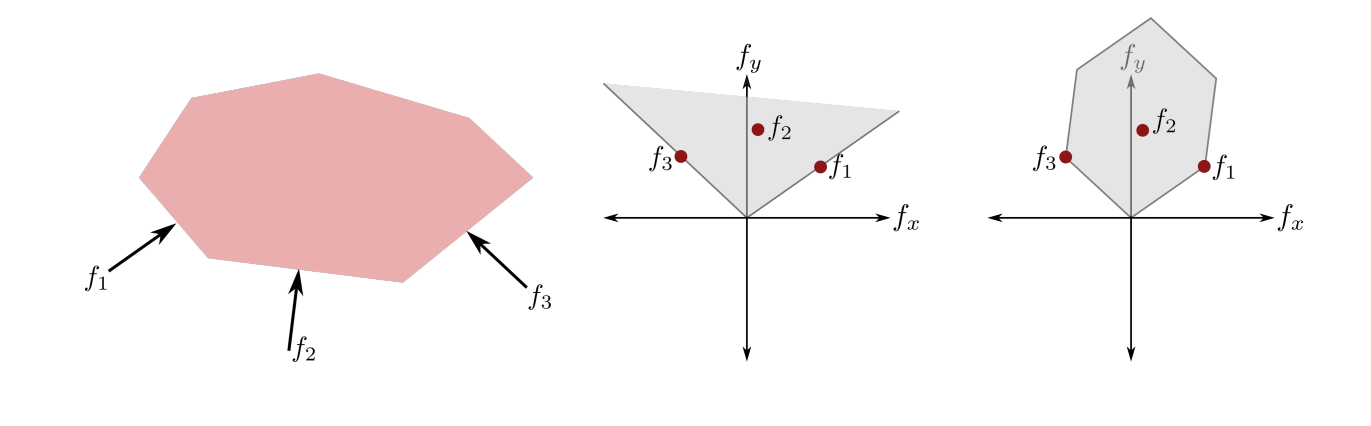
from Stanford CS237b
\begin{aligned}
\mathcal{W}_\varepsilon = \{w | w = \sum_i \mathbf{J}^\top_{\mathsf{u}_i}\lambda_i, \lambda_i\in\mathcal{K}_i, \|\lambda\|_2\leq \varepsilon\}
\end{aligned}
Recall the "Wrench Set" from old grasping literature.
Under quasistatic dynamics, the movement of the object is a linear transform of this wrench set.
\begin{aligned}
\mathcal{R}_\varepsilon = \{q^\mathrm{u}_+ | q^\mathrm{u}_+ = q^\mathrm{u} + h\mathbf{M}_\mathrm{u}^{-1}(h\tau^\mathrm{u} + w), w\in\mathcal{W}\}
\end{aligned}
Wrench Set
Wrench Set: Limitations
\begin{aligned}
\mathcal{W}_\varepsilon = \{w | w = \sum_i \mathbf{J}^\top_{\mathsf{u}_i}\lambda_i, \lambda_i\in\mathcal{K}_i, \|\lambda\|_2\leq \varepsilon\}
\end{aligned}
Recall the "Wrench Set" from old grasping literature.
Under quasistatic dynamics, the movement of the object is a linear transform of this wrench set.
\begin{aligned}
\mathcal{R}_\varepsilon = \{q^\mathrm{u}_+ | q^\mathrm{u}_+ = q^\mathrm{u} + h\mathbf{M}_\mathrm{u}^{-1}(h\tau^\mathrm{u} + w), w\in\mathcal{W}\}
\end{aligned}
But the wrench set has limitations if we go beyond point fingers
1. Singular configurations of the manipulator
2. Self collisions within the manipulator
3. Joint Limits of the manipulator
4. Torque limits of the manipulator
The Achievable Wrench Set
\begin{aligned}
\mathcal{W}_\varepsilon = \{w | w = \sum_i \mathbf{J}^\top_{\mathsf{u}_i}\lambda_i({\color{red} u}),\lambda_i({\color{red} u})\in\mathcal{K}_i, \|{\color{red} u}\|_2\leq \varepsilon\}
\end{aligned}
Write down forces as function of input instead
\begin{aligned}
\mathcal{W}_\varepsilon = \{w | w = \sum_i \mathbf{J}^\top_{\mathsf{u}_i}\lambda_i, \lambda_i\in\mathcal{K}_i, \|\lambda\|_2\leq \varepsilon\}
\end{aligned}
Recall the "Wrench Set" from old grasping literature.
The Achievable Wrench Set
\begin{aligned}
\mathcal{W}_\varepsilon = \{w | w = \sum_i \mathbf{J}^\top_{\mathsf{u}_i}\lambda_i({\color{red} u}),\lambda_i({\color{red} u})\in\mathcal{K}_i, \|{\color{red} u}\|_2\leq \varepsilon\}
\end{aligned}
Write down forces as function of input instead
\begin{aligned}
\mathcal{W}_\varepsilon = \{w | w = \sum_i \mathbf{J}^\top_{\mathsf{u}_i}\lambda_i, \lambda_i\in\mathcal{K}_i, \|\lambda\|_2\leq \varepsilon\}
\end{aligned}
Recall the "Wrench Set" from old grasping literature.
Recall we also have linear models for these forces!
\begin{aligned}
\mathcal{W}_\varepsilon = \{w | w & = \sum_i \mathbf{J}^\top_{\mathsf{u}_i}\bar{\lambda}_i({\color{red} u}),\bar{\lambda}_i({\color{red} u})\in\mathcal{K}_i, \|{\color{red} u}\|_2\leq \varepsilon,\\
& \bar{\lambda}_i(u) = \lambda_i(\bar{u}) + \frac{\partial \lambda}{\partial u} \delta u \}
\end{aligned}
The Achievable Wrench Set
\begin{aligned}
w(u) & = \sum_i \mathbf{J}^\top_{\mathsf{u}_i} \bar{\lambda}_i(u) \\
& =\sum_i \mathbf{J}^\top_{\mathsf{u}_i}\lambda_i(\bar{u}) + \sum_i \mathbf{J}^\top_{\mathrm{u}_i}\frac{\partial \lambda_i}{\partial u}\delta u
\end{aligned}
Let's compute the Jacobian sum
\begin{aligned}
\bar{\lambda}_i(u) & = \lambda_i(\bar{u}) + \frac{\partial \lambda_i}{\partial u} \delta u
\end{aligned}
The Achievable Wrench Set
\begin{aligned}
w(u) & = \sum_i \mathbf{J}^\top_{\mathsf{u}_i} \bar{\lambda}_i(u) \\
& =\sum_i \mathbf{J}^\top_{\mathsf{u}_i}\lambda_i(\bar{u}) + \sum_i \mathbf{J}^\top_{\mathrm{u}_i}\frac{\partial \lambda_i}{\partial u}\delta u
\end{aligned}
Let's compute the Jacobian sum
\begin{aligned}
\bar{\lambda}_i(u) & = \lambda_i(\bar{u}) + \frac{\partial \lambda_i}{\partial u} \delta u
\end{aligned}
\begin{aligned}
q^\mathrm{u}_+(u) & = q^\mathrm{u}(\bar{u}) +h\mathbf{M}_\mathrm{u}^{-1}w \\
& = q^\mathrm{u}(\bar{u}) + h\mathbf{M}_{\mathrm{u}}^{-1}\left[\sum_i \mathbf{J}^\top_{\mathsf{u}_i}\lambda_i(\bar{u}) + \sum_i \mathbf{J}^\top_{\mathrm{u}_i}\frac{\partial \lambda_i}{\partial u}\delta u\right]
\end{aligned}
Transform it to generalized coordinates
The Achievable Wrench Set
\begin{aligned}
w(u) & = \sum_i \mathbf{J}^\top_{\mathsf{u}_i} \bar{\lambda}_i(u) \\
& =\sum_i \mathbf{J}^\top_{\mathsf{u}_i}\lambda_i(\bar{u}) + \sum_i \mathbf{J}^\top_{\mathrm{u}_i}\frac{\partial \lambda_i}{\partial u}\delta u
\end{aligned}
Let's compute the Jacobian sum
\begin{aligned}
\bar{\lambda}_i(u) & = \lambda_i(\bar{u}) + \frac{\partial \lambda_i}{\partial u} \delta u
\end{aligned}
\begin{aligned}
q^\mathrm{u}_+(u) & = q^\mathrm{u}(\bar{u}) +h\mathbf{M}_\mathrm{u}^{-1}w \\
& = q^\mathrm{u}(\bar{u}) + h\mathbf{M}_{\mathrm{u}}^{-1}\left[\sum_i \mathbf{J}^\top_{\mathsf{u}_i}\lambda_i(\bar{u}) + \sum_i \mathbf{J}^\top_{\mathrm{u}_i}\frac{\partial \lambda_i}{\partial u}\delta u\right]
\end{aligned}
Transform it to generalized coordinates
\begin{aligned}
\color{red} q^\mathrm{u}_+(\bar{u})
\end{aligned}
The Achievable Wrench Set
\begin{aligned}
q^\mathrm{u}_+(u) & = q^\mathrm{u}(\bar{u}) +h\mathbf{M}_\mathrm{u}^{-1}w(u) \\
& = q^\mathrm{u}(\bar{u}) + h\mathbf{M}_{\mathrm{u}}^{-1}\sum_i \mathbf{J}^\top_{\mathsf{u}_i}\lambda_i(\bar{u}) + h\mathbf{M}_{\mathrm{u}}^{-1}\sum_i \mathbf{J}^\top_{\mathrm{u}_i}\frac{\partial \lambda_i}{\partial u}\delta u
\end{aligned}
Transform it to generalized coordinates
\begin{aligned}
\color{red} q^\mathrm{u}_+(\bar{u})
\end{aligned}
To see the latter term, note that from sensitivity analysis,
\begin{aligned}
q^\mathrm{u}_+(u) & = q^\mathrm{u}(\bar{u}) + h\mathbf{M}_{\mathrm{u}}^{-1}\sum_i \mathbf{J}^\top_{\mathsf{u}_i}\lambda_i(\bar{u}) \\
& = h\mathbf{M}_\mathrm{u}^{-1}\sum_i \mathbf{J}^\top_{\mathsf{u}_i}\frac{\partial\lambda_i}{\partial u}
\end{aligned}
\begin{aligned}
{\color{red} \frac{\partial }{\partial u}}
\end{aligned}
The Achievable Wrench Set
\begin{aligned}
q^\mathrm{u}_+(u) & = q^\mathrm{u}(\bar{u}) +h\mathbf{M}_\mathrm{u}^{-1}w(u) \\
& = q^\mathrm{u}(\bar{u}) + h\mathbf{M}_{\mathrm{u}}^{-1}\sum_i \mathbf{J}^\top_{\mathsf{u}_i}\lambda_i(\bar{u}) + h\mathbf{M}_{\mathrm{u}}^{-1}\sum_i \mathbf{J}^\top_{\mathrm{u}_i}\frac{\partial \lambda_i}{\partial u}\delta u \\
& = q^\mathrm{u}_+(\bar{u}) + {\color{red}\frac{\partial q^\mathrm{u}_+}{\partial u}}\delta u
\end{aligned}
Transform it to generalized coordinates
\begin{aligned}
\color{red} q^\mathrm{u}_+(\bar{u})
\end{aligned}
This is the B matrix for iLQR, inverse dynamics, etc.
that differentiable simulators give
The Achievable Wrench Set
\begin{aligned}
q^\mathrm{u}_+(u) & = q^\mathrm{u}(\bar{u}) +h\mathbf{M}_\mathrm{u}^{-1}w(u) \\
& = q^\mathrm{u}(\bar{u}) + h\mathbf{M}_{\mathrm{u}}^{-1}\sum_i \mathbf{J}^\top_{\mathsf{u}_i}\lambda_i(\bar{u}) + h\mathbf{M}_{\mathrm{u}}^{-1}\sum_i \mathbf{J}^\top_{\mathrm{u}_i}\frac{\partial \lambda_i}{\partial u}\delta u \\
& = q^\mathrm{u}_+(\bar{u}) + {\color{red}\frac{\partial q^\mathrm{u}_+}{\partial u}}\delta u
\end{aligned}
Transform it to generalized coordinates
\begin{aligned}
\color{red} q^\mathrm{u}_+(\bar{u})
\end{aligned}
This is the B matrix for iLQR, inverse dynamics, etc.
that differentiable simulators give
But what happened to the constraints?
The Achievable Wrench Set
\begin{aligned}
q^\mathrm{u}_+(u) & = q^\mathrm{u}(\bar{u}) +h\mathbf{M}_\mathrm{u}^{-1}w(u) \\
& = q^\mathrm{u}(\bar{u}) + h\mathbf{M}_{\mathrm{u}}^{-1}\sum_i \mathbf{J}^\top_{\mathsf{u}_i}\lambda_i(\bar{u}) + h\mathbf{M}_{\mathrm{u}}^{-1}\sum_i \mathbf{J}^\top_{\mathrm{u}_i}\frac{\partial \lambda_i}{\partial u}\delta u \\
& = q^\mathrm{u}_+(\bar{u}) + {\color{red}\frac{\partial q^\mathrm{u}_+}{\partial u}}\delta u
\end{aligned}
Transform it to generalized coordinates
\begin{aligned}
\color{red} q^\mathrm{u}_+(\bar{u})
\end{aligned}
\begin{aligned}
{\color{blue} \lambda_i(\bar{u}) + \frac{\partial\lambda_i}{\partial u}\delta u\in\mathcal{K}_i, \|u\|_2\leq \varepsilon}
\end{aligned}
Need to add these back in through model of dual variables
Trust Region Interpretation
\begin{aligned}
q^\mathrm{u}_+(u) & = q^\mathrm{u}(\bar{u}) +h\mathbf{M}_\mathrm{u}^{-1}w(u) \\
& = q^\mathrm{u}(\bar{u}) + h\mathbf{M}_{\mathrm{u}}^{-1}\sum_i \mathbf{J}^\top_{\mathsf{u}_i}\lambda_i(\bar{u}) + h\mathbf{M}_{\mathrm{u}}^{-1}\sum_i \mathbf{J}^\top_{\mathrm{u}_i}\frac{\partial \lambda_i}{\partial u}\delta u \\
& = q^\mathrm{u}_+(\bar{u}) + {\color{red}\frac{\partial q^\mathrm{u}_+}{\partial u}}\delta u
\end{aligned}
Transform it to generalized coordinates
\begin{aligned}
\color{red} q^\mathrm{u}_+(\bar{u})
\end{aligned}
\begin{aligned}
{\color{blue} \lambda_i(\bar{u}) + \frac{\partial\lambda_i}{\partial u}\delta u\in\mathcal{K}_i, \|u\|_2\leq \varepsilon}
\end{aligned}
Need to add these back in through model of dual variables
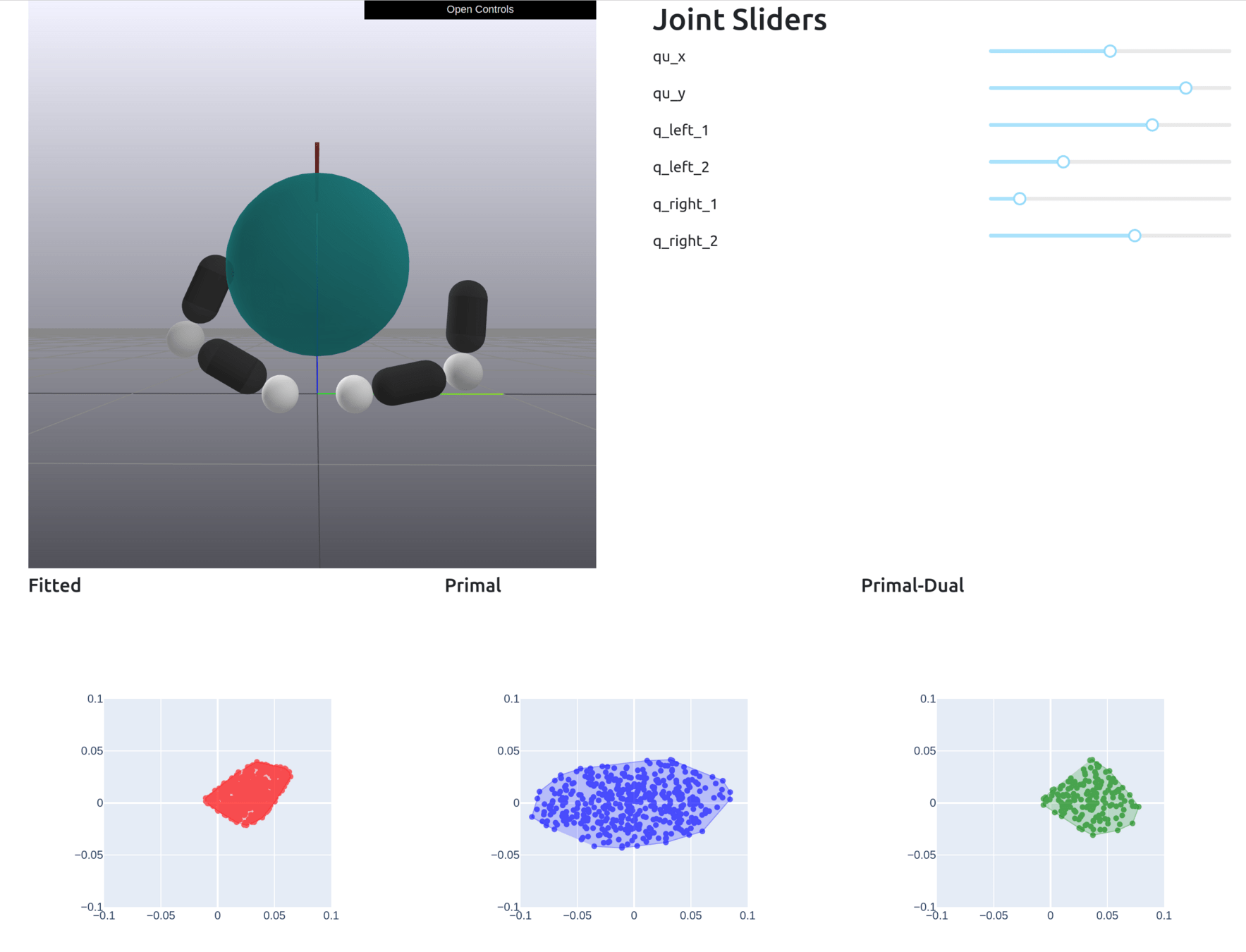
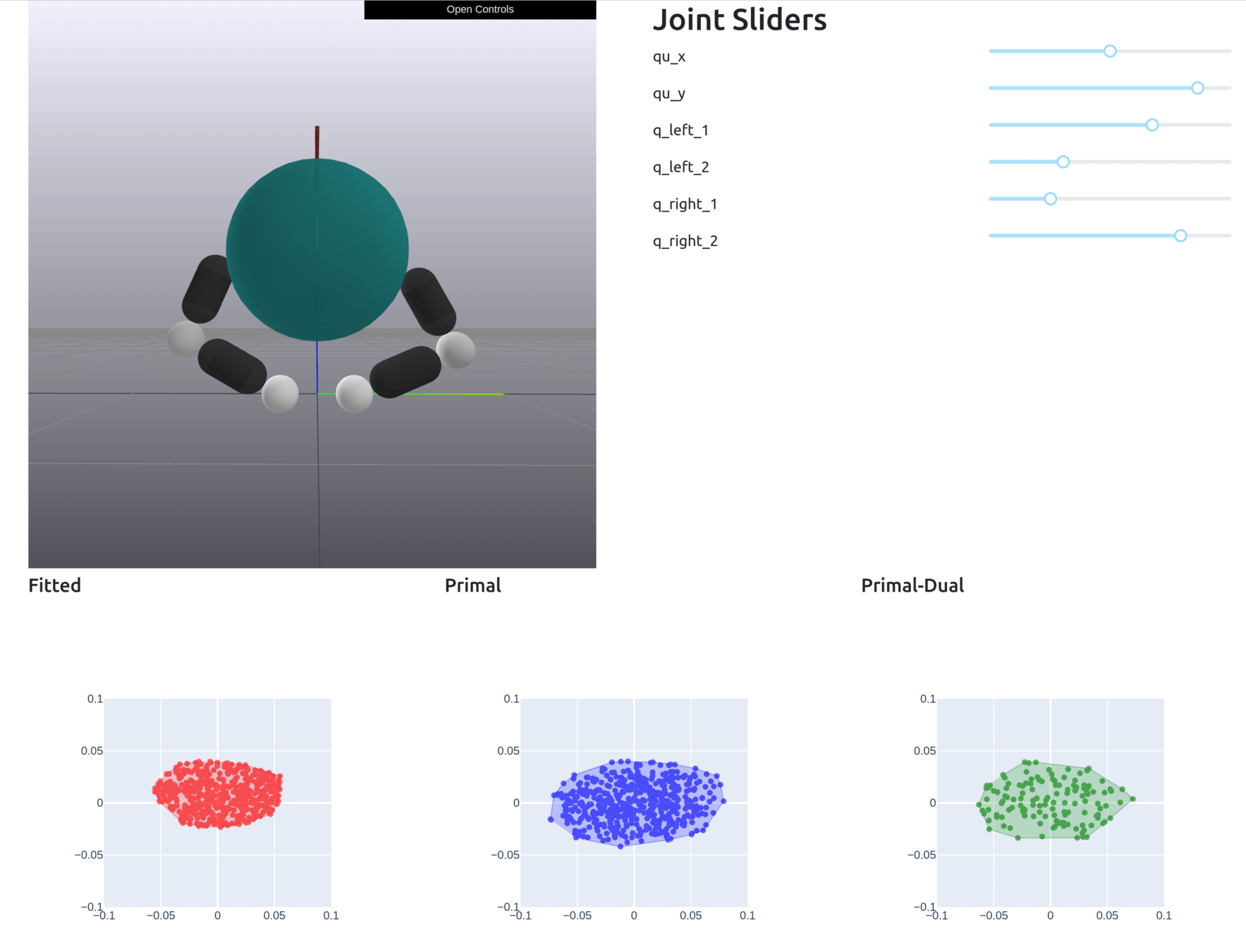
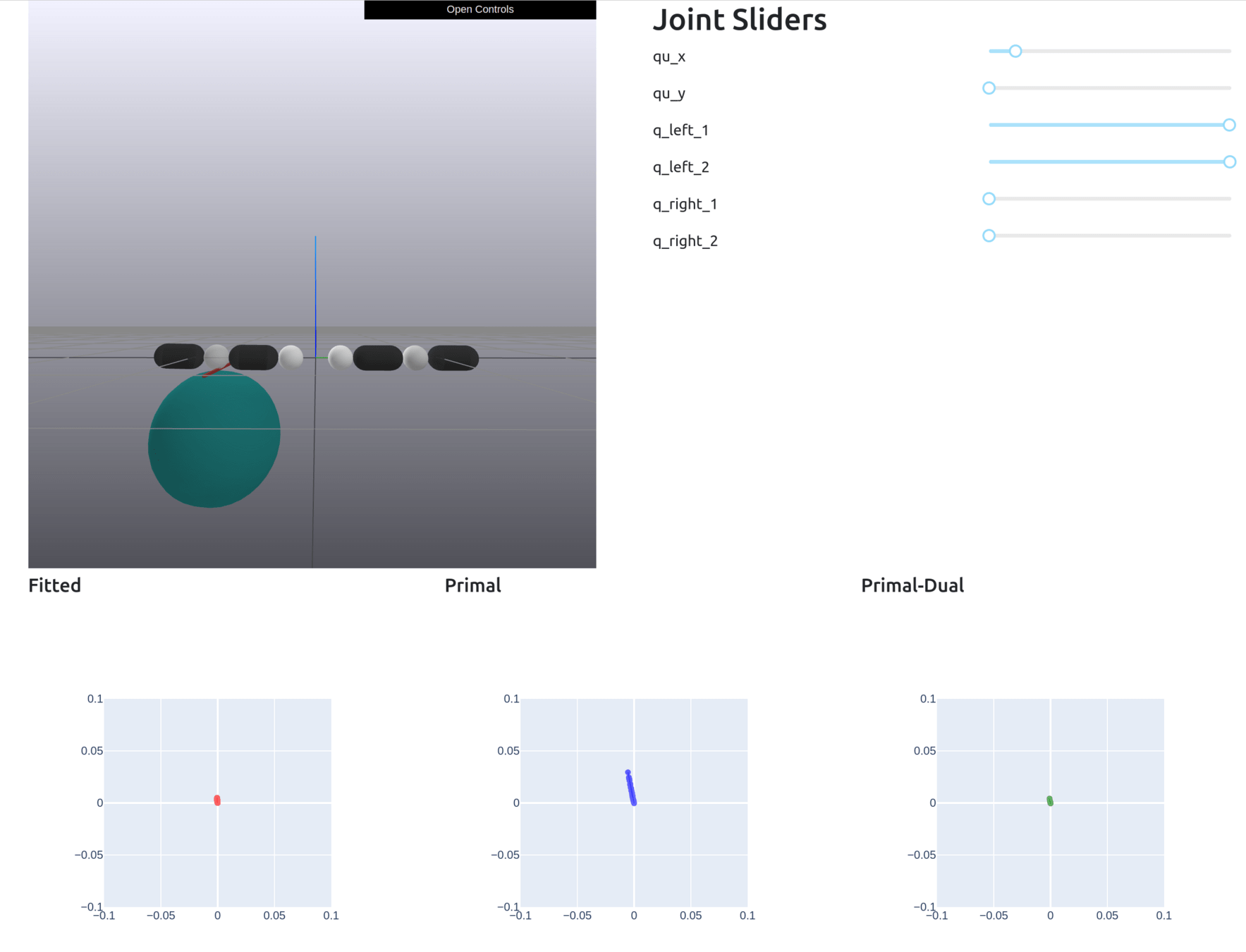
Formally Defining Motion Set
Given , solve the dynamics to obtain the Motion Set parameters.
\begin{aligned}
q_+^{\mathrm{u}}(\bar{q},\bar{u}), \; \lambda_i^\mathrm{u}(\bar{q},\bar{u}),\\
\;\mathbf{B}(\bar{q},\bar{u}) \coloneqq \frac{\partial q_+^\mathrm{u}}{\partial u}(\bar{q},\bar{u}) \; \\
\mathbf{\Lambda}^\mathrm{u}_i(\bar{q},\bar{u})\coloneqq \frac{\partial\lambda_i^\mathrm{u}}{\partial u}(\bar{q},\bar{u})
\end{aligned}
\begin{aligned}
\bar{q},\bar{u}
\end{aligned}
Define the Motion Set as
\begin{aligned}
\mathcal{M}(\bar{q},\bar{u})\coloneqq \{\bar{q}^\mathrm{u}_+ | & \bar{q}^\mathrm{u}_+ = q^\mathrm{u}_+(\bar{q},\bar{u}) + \mathbf{B}^\mathrm{u}(\bar{q},\bar{u}) \delta u, \\
& \bar{\lambda}^\mathrm{u}_i = \lambda^\mathrm{u}(\bar{q},\bar{u})_i + \mathbf{\Lambda}^\mathrm{u}_i(\bar{q},\bar{u})\delta u \in \mathcal{K}_i, \\
& \|\delta u \|_2 \leq \varepsilon\}
\end{aligned}
+ additional constraints (joint limit, torque limit)
Formally Defining Motion Set
Given , solve the dynamics to obtain the Motion Set parameters.
\begin{aligned}
q_+^{\mathrm{u}}(\bar{q},\bar{u}), \; \lambda_i^\mathrm{u}(\bar{q},\bar{u}),\\
\;\mathbf{B}(\bar{q},\bar{u}) \coloneqq \frac{\partial q_+^\mathrm{u}}{\partial u}(\bar{q},\bar{u}) \; \\
\mathbf{\Lambda}^\mathrm{u}_i(\bar{q},\bar{u})\coloneqq \frac{\partial\lambda_i^\mathrm{u}}{\partial u}(\bar{q},\bar{u})
\end{aligned}
\begin{aligned}
\bar{q},\bar{u}
\end{aligned}
Define the Motion Set as
\begin{aligned}
\mathcal{M}(\bar{q},\bar{u})\coloneqq \{\bar{q}^\mathrm{u}_+ | & \bar{q}^\mathrm{u}_+ = q^\mathrm{u}_+(\bar{q},\bar{u}) + \mathbf{B}^\mathrm{u}(\bar{q},\bar{u}) \delta u, \\
& \bar{\lambda}^\mathrm{u}_i = \lambda^\mathrm{u}(\bar{q},\bar{u})_i + \mathbf{\Lambda}^\mathrm{u}_i(\bar{q},\bar{u})\delta u \in \mathcal{K}_i, \\
& \|\delta u \|_2 \leq \varepsilon\}
\end{aligned}
+ additional constraints (joint limit, torque limit)
This set is always convex

Folk Physics for Apes
Inverse Dynamics using Motion Set
\begin{aligned}
\min_{\delta u} \quad & \|\bar{q}^\mathrm{u}_+ - \bar{q}^\mathrm{u}_{goal}\|^2_\mathbf{Q} + \|\delta u\|^2_\mathbf{R} \\
\text{s.t.} \quad & \bar{q}^\mathrm{u}_+ = q^\mathrm{u}_+(\bar{q},\bar{u}) + \mathbf{B}^\mathrm{u}(\bar{q},\bar{u}) \delta u, \\
& {\color{red}\bar{\lambda}^\mathrm{u}_i = \lambda^\mathrm{u}(\bar{q},\bar{u})_i + \mathbf{\Lambda}^\mathrm{u}_i(\bar{q},\bar{u})\delta u \in \mathcal{K}_i}, \\
& {\color{red}\|\delta u \|_2 \leq \varepsilon}
\end{aligned}
Primal Only
Primal-Dual
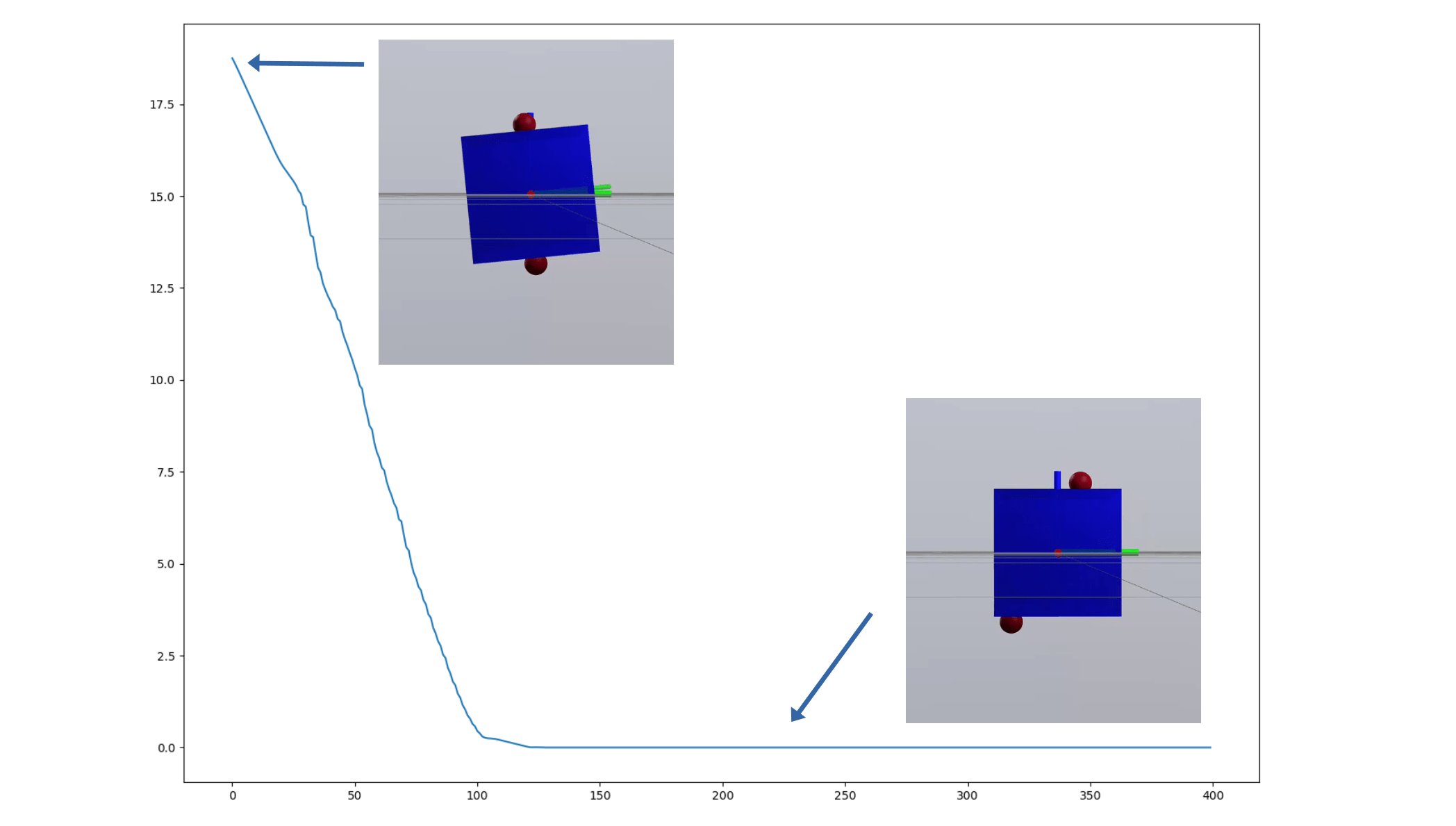
Inverse Dynamics Performance
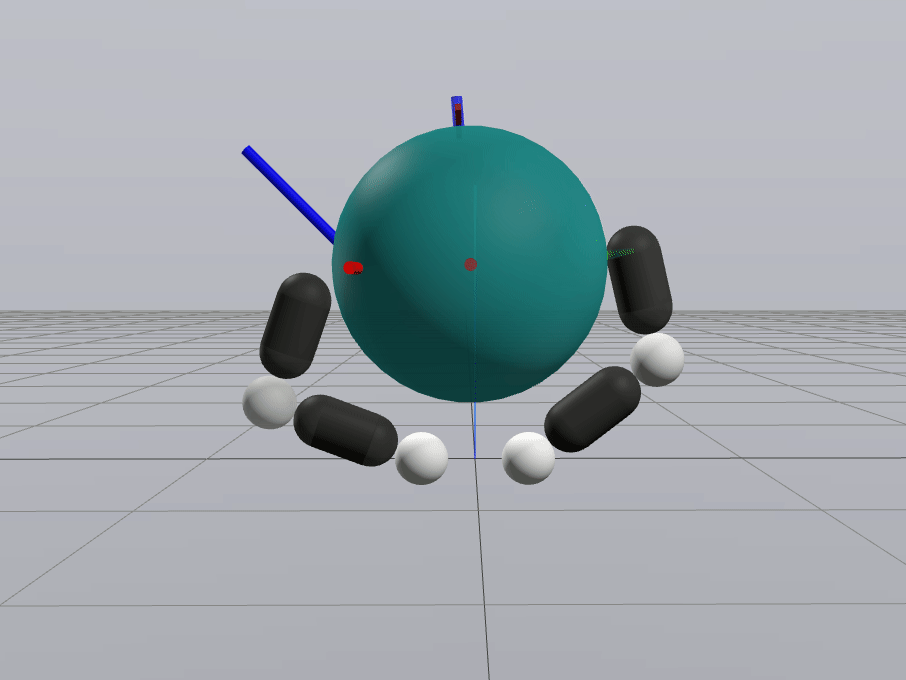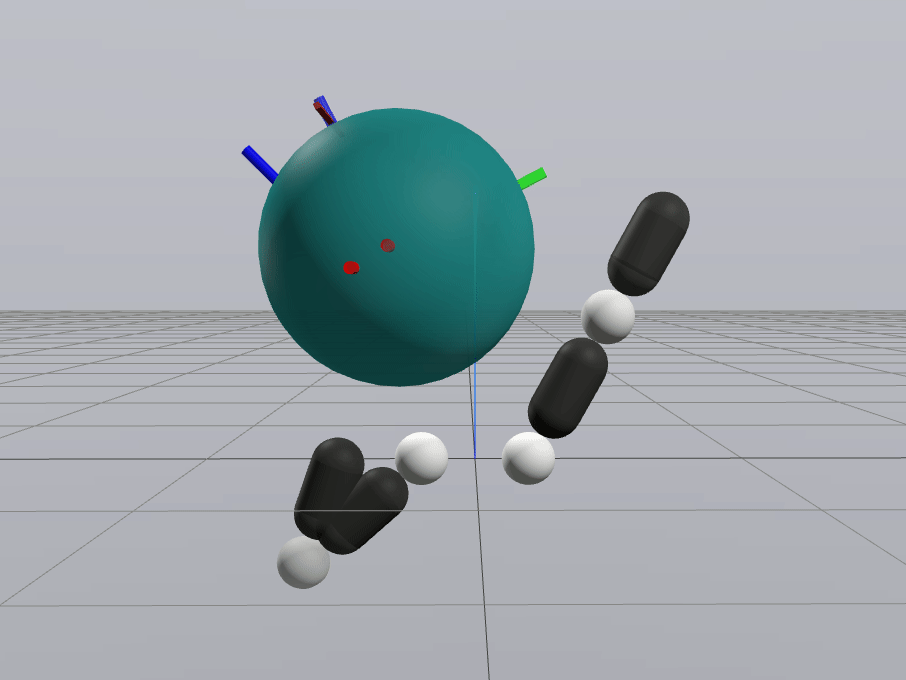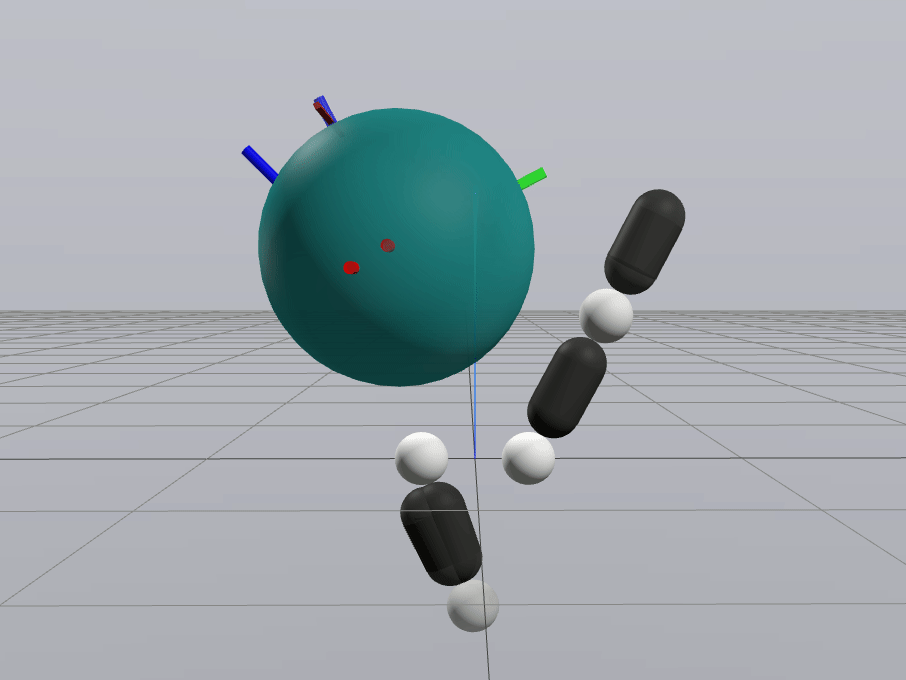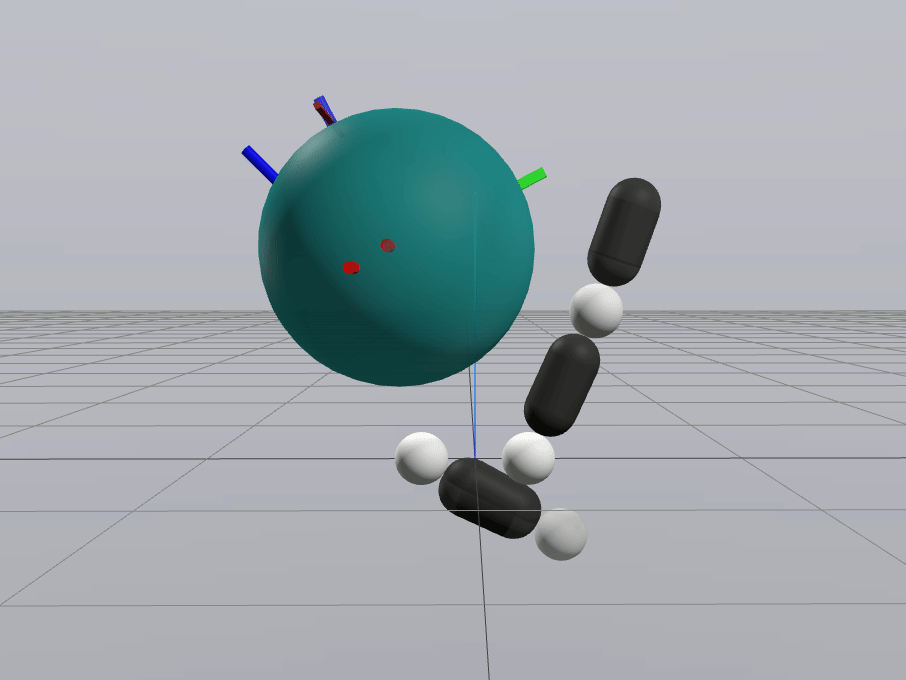
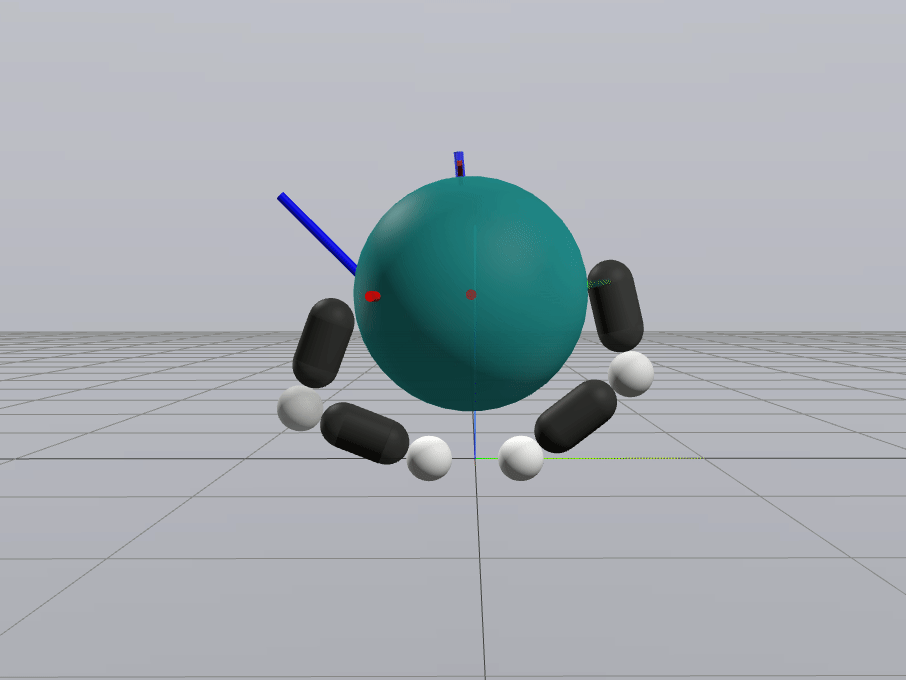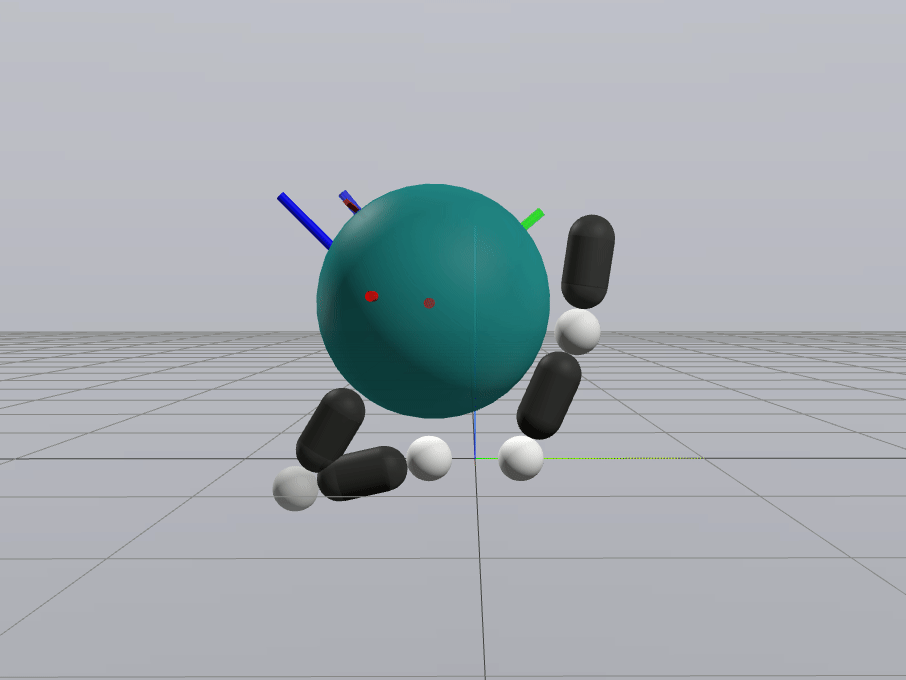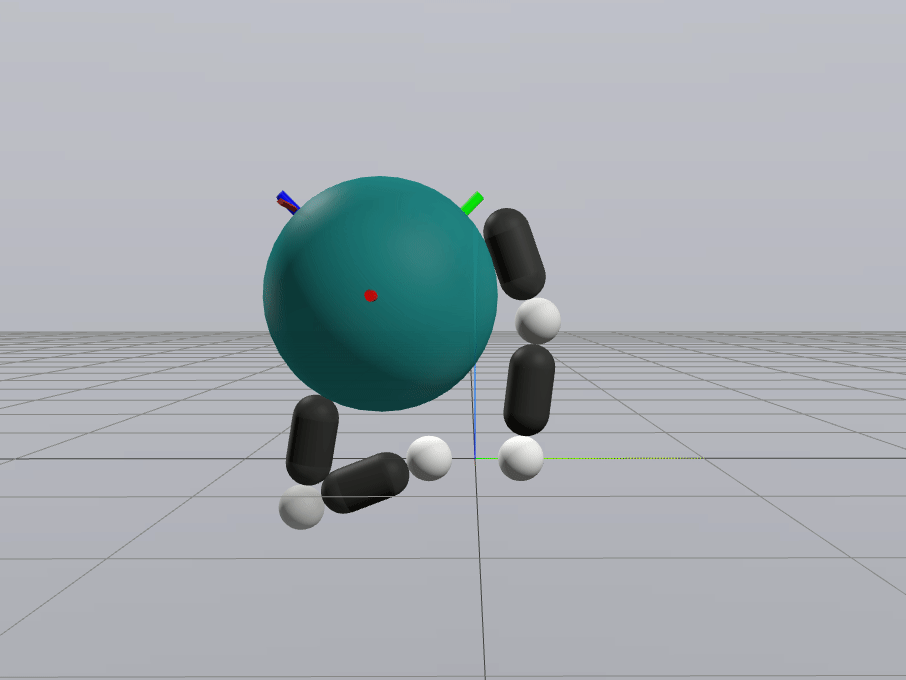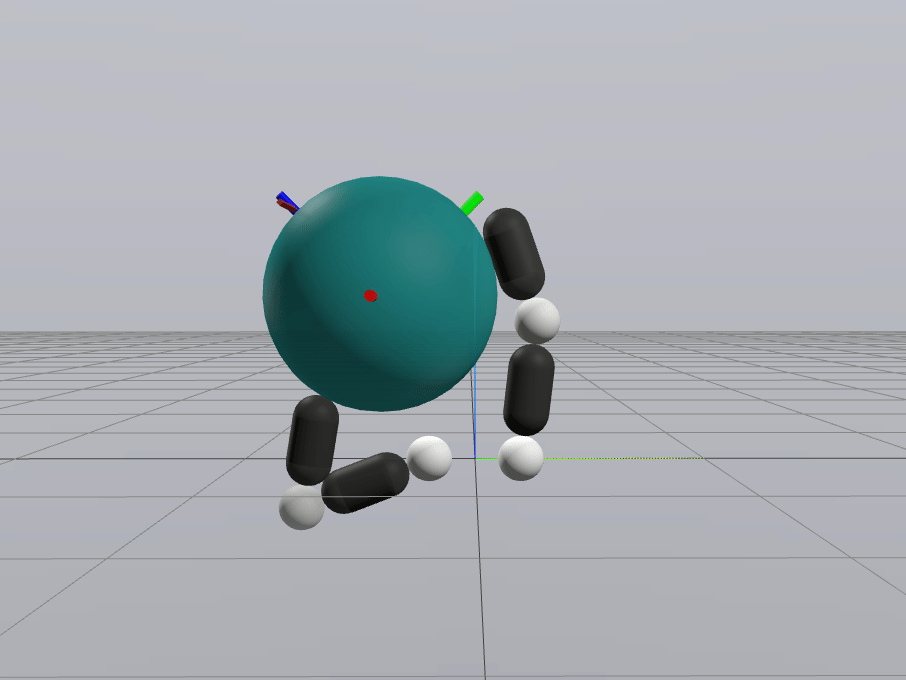
Primal Only
Primal Dual
First feedback controller (besides MPC) that shows good performance for me
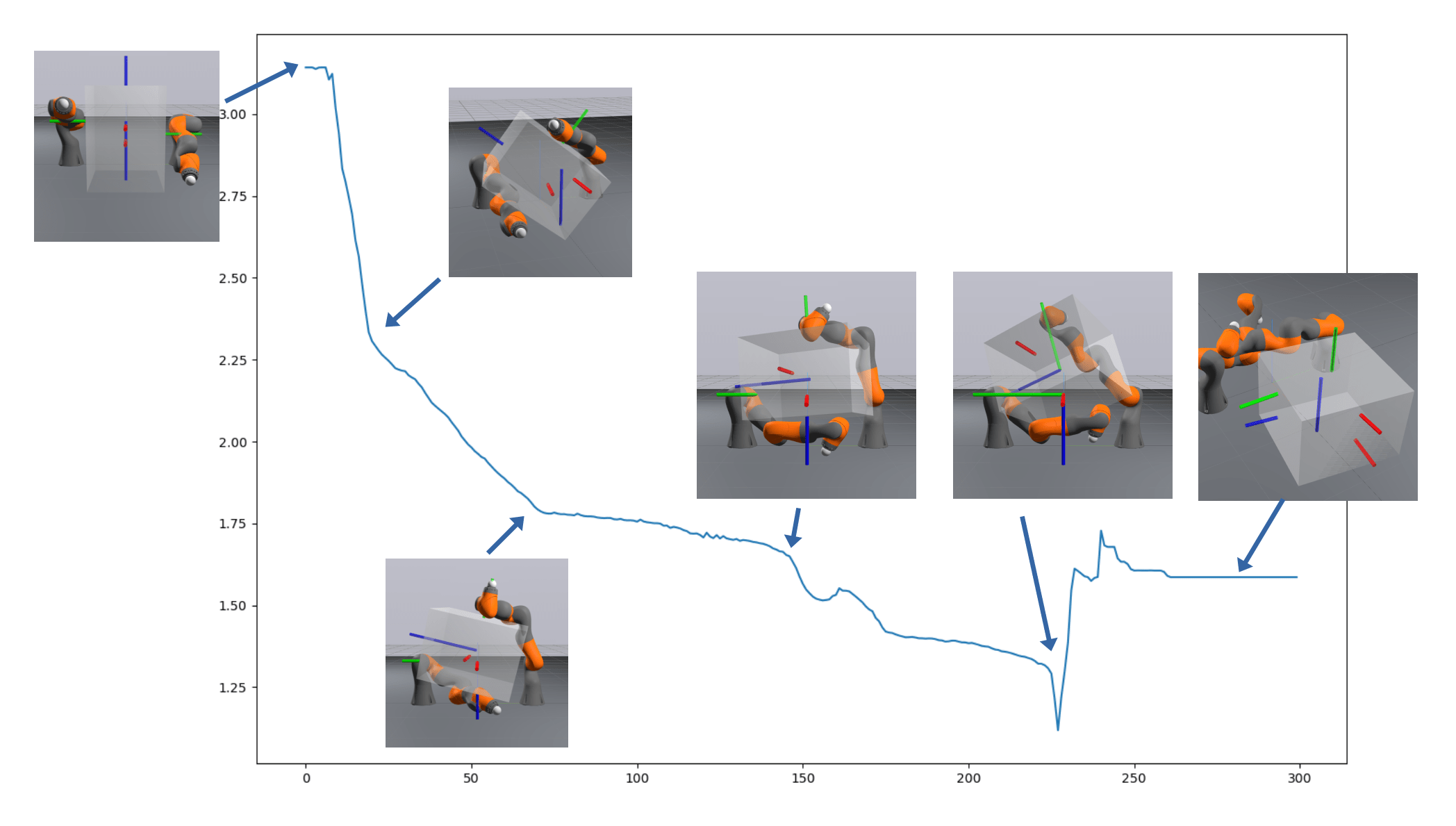
Sim2Drake Performance
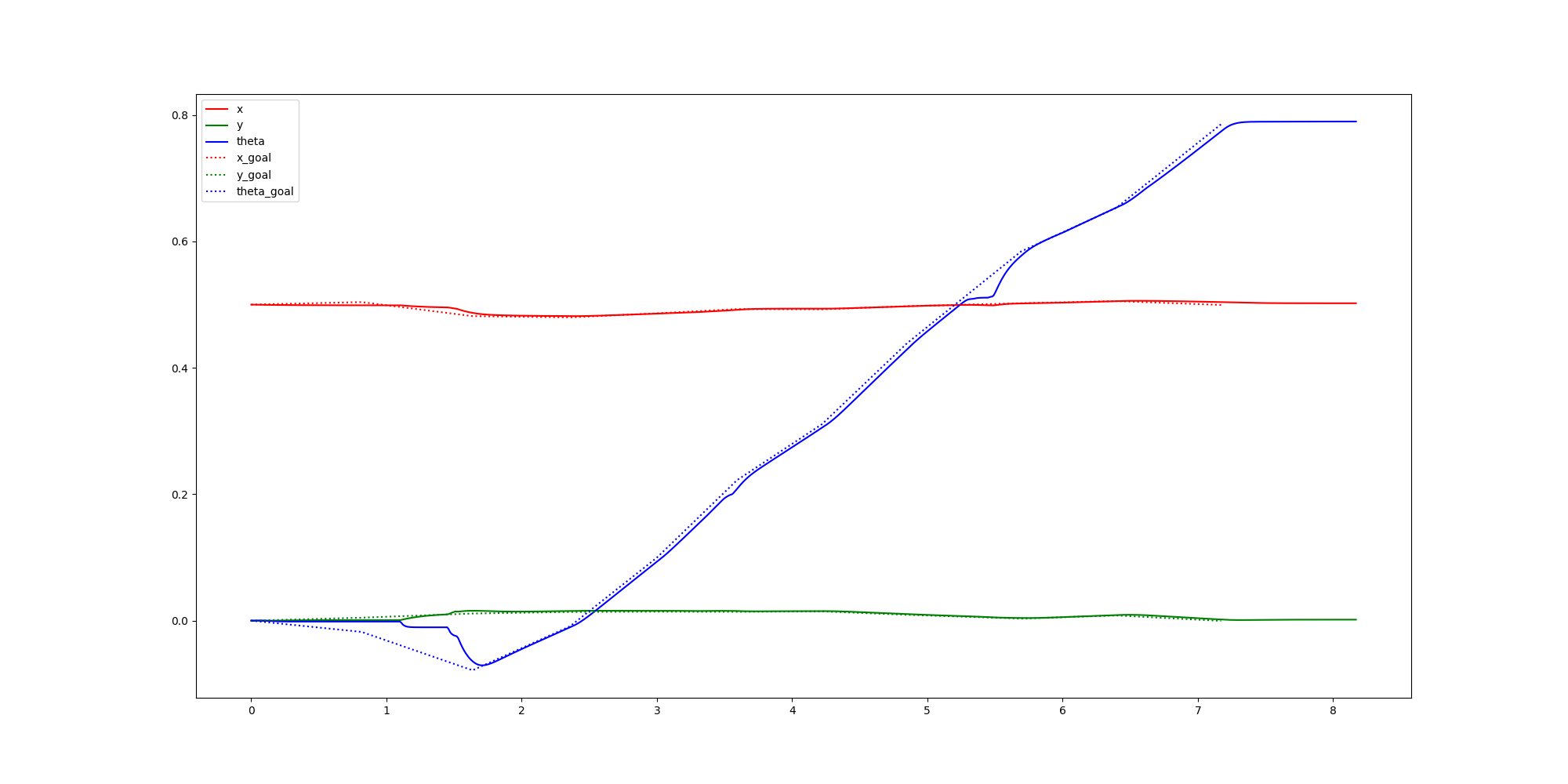
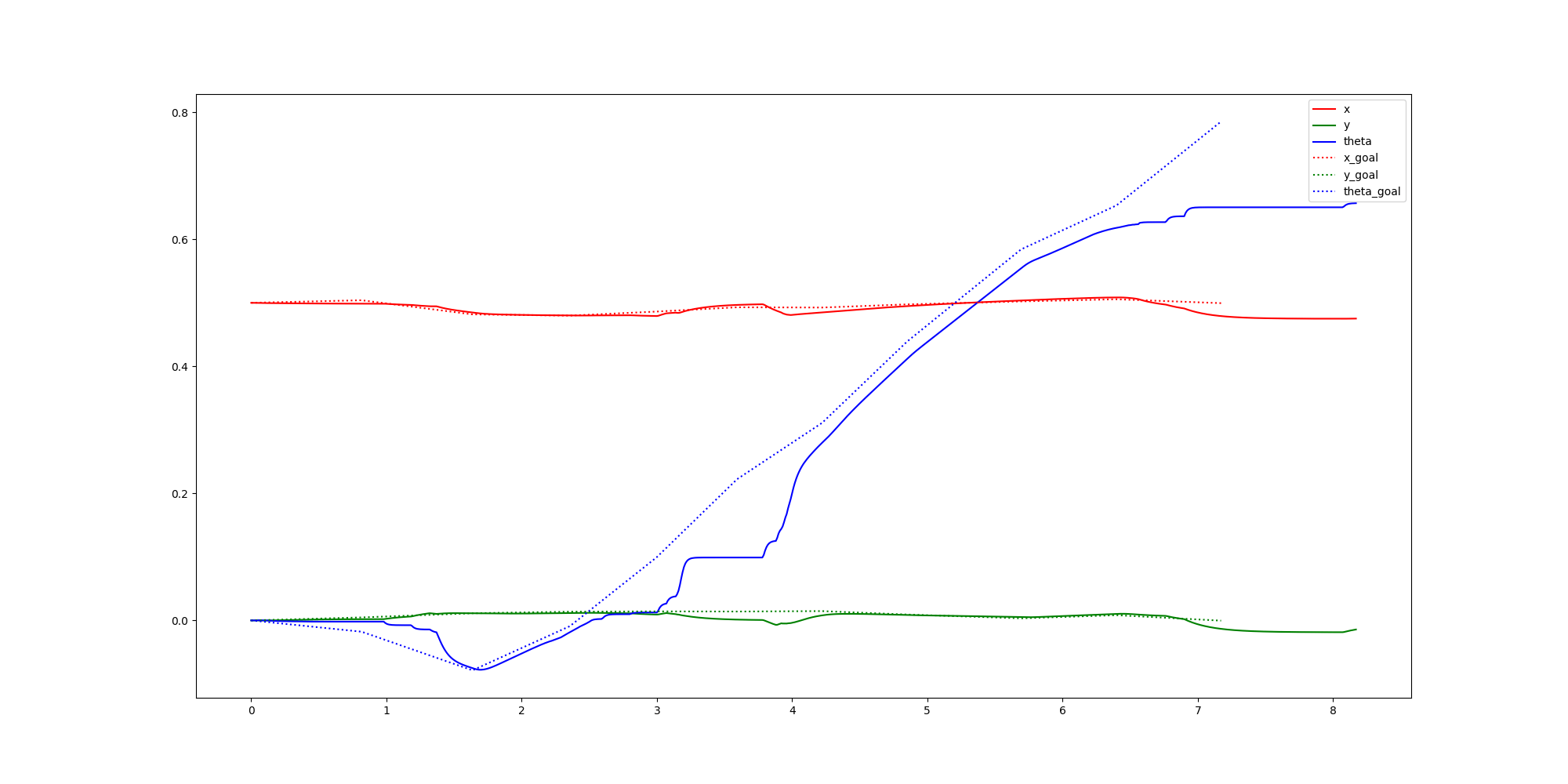
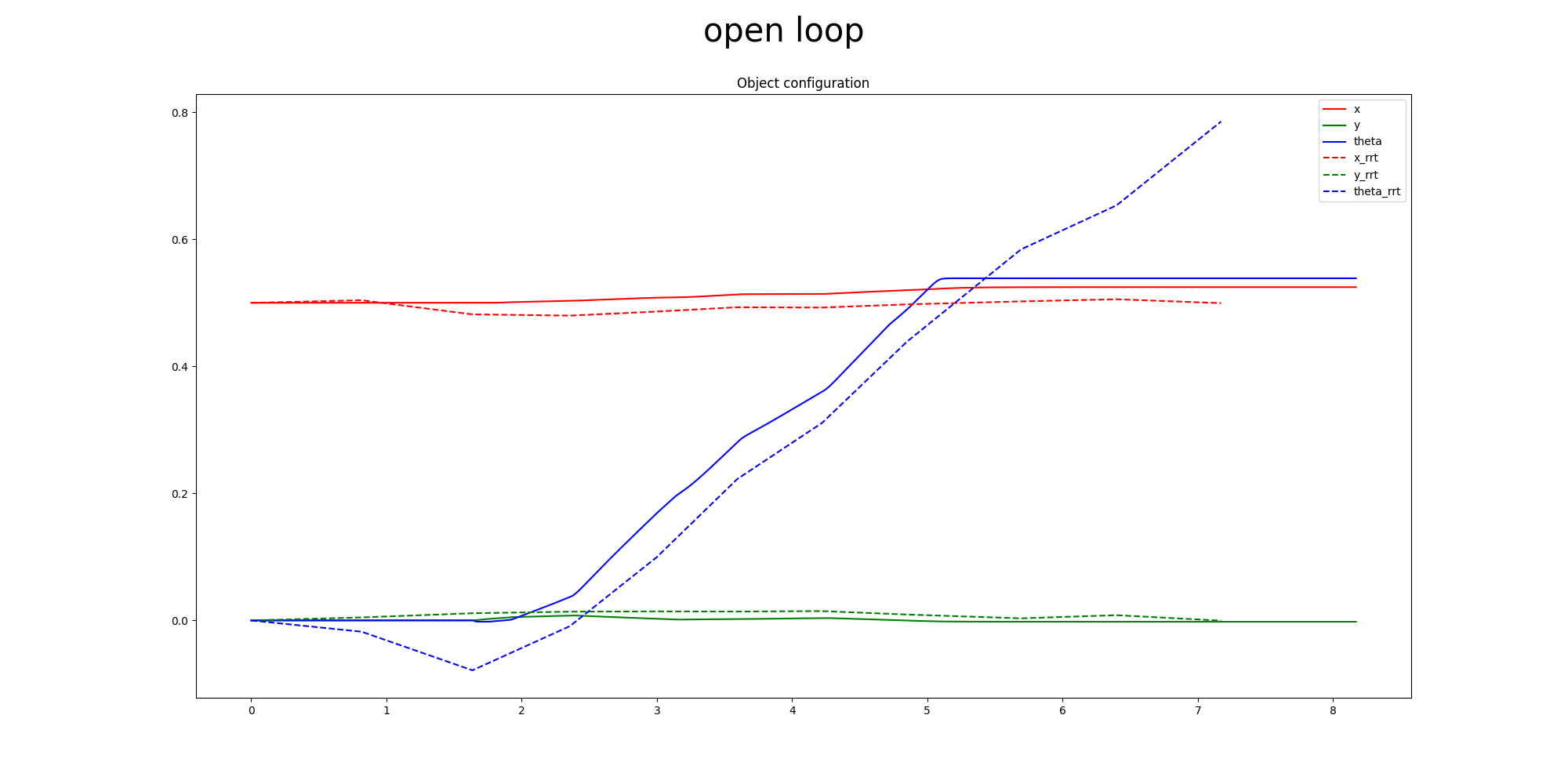
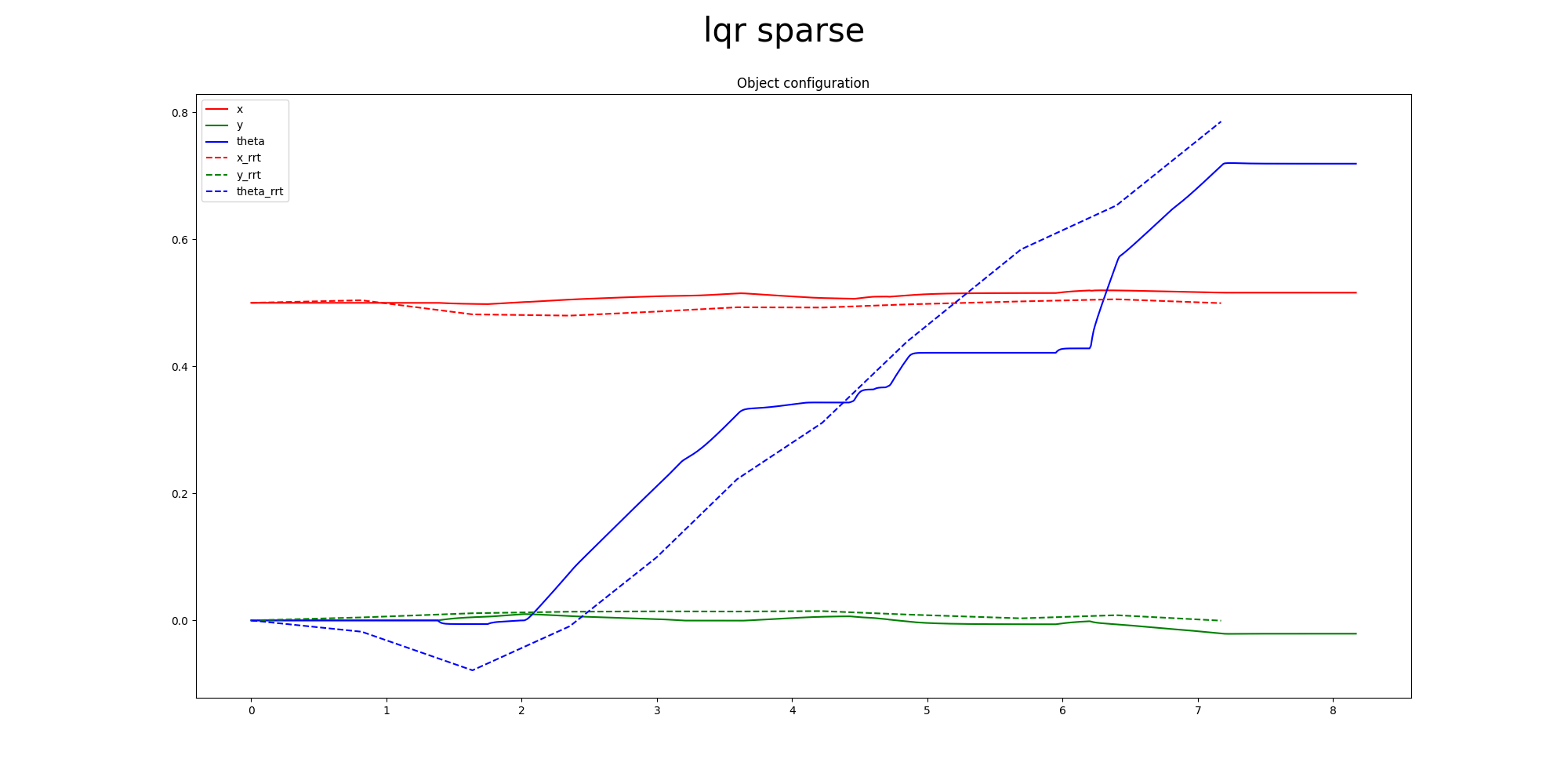
Primal Only
Open Loop
LQR
Primal-Dual
Done by Tong at BDAI
Inverse Dynamics Cost vs. Motion Set
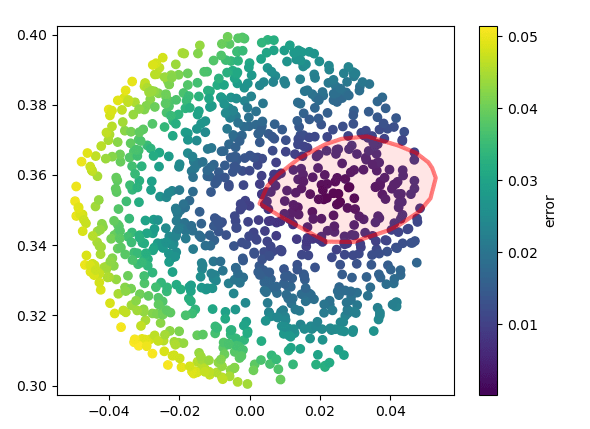

Inverse Dynamics Cost vs. Motion Set
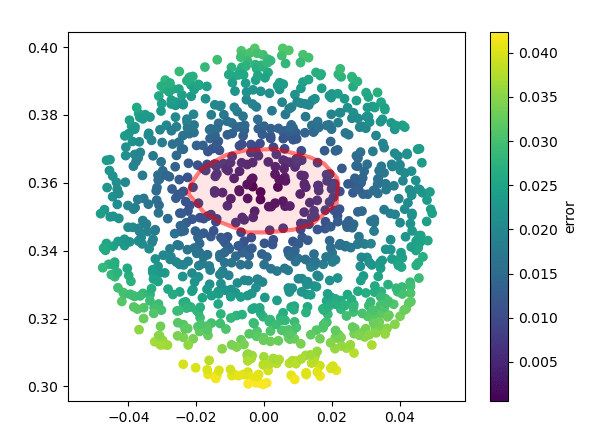
Inverse Dynamics Performance
Inverse Dynamics Performance
Inverse Dynamics Performance
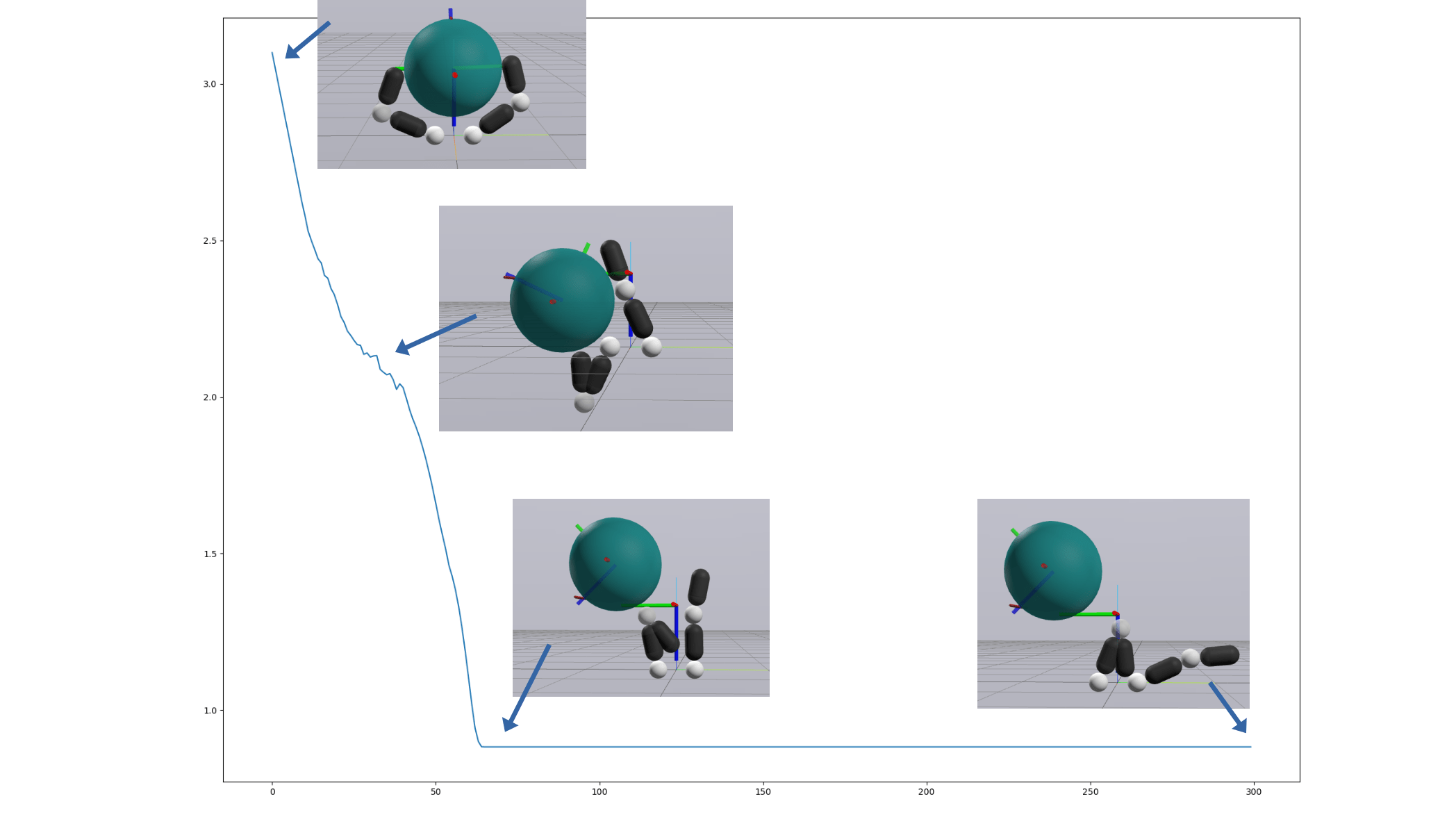
3D In-hand Reorientation
Preliminary Results for Hand
Force Control using Dual Variables
\begin{aligned}
\min_{\delta u} \quad & \|\bar{q}^\mathrm{u}_+ - \bar{q}^\mathrm{u}_{goal}\|^2_\mathbf{Q} + \|\delta u\|^2_\mathbf{R} + {\color{blue} \|\bar{\lambda}_i^\mathrm{u} - \bar{\lambda}_{i,goal}^\mathrm{u}\|^2_\mathbf{P}} \\
\text{s.t.} \quad & \bar{q}^\mathrm{u}_+ = q^\mathrm{u}_+(\bar{q},\bar{u}) + \mathbf{B}^\mathrm{u}(\bar{q},\bar{u}) \delta u, \\
& {\color{red}\bar{\lambda}^\mathrm{u}_i = \lambda^\mathrm{u}(\bar{q},\bar{u})_i + \mathbf{\Lambda}^\mathrm{u}_i(\bar{q},\bar{u})\delta u \in \mathcal{K}_i}, \\
& {\color{red}\|\delta u \|_2 \leq \varepsilon}
\end{aligned}
Primal Only
Primal-Dual
Beautifully generalizes to hybrid force/velocity controllers
May allow incorporation of tactile forces when used for estimation
Inverse Dynamics Performance
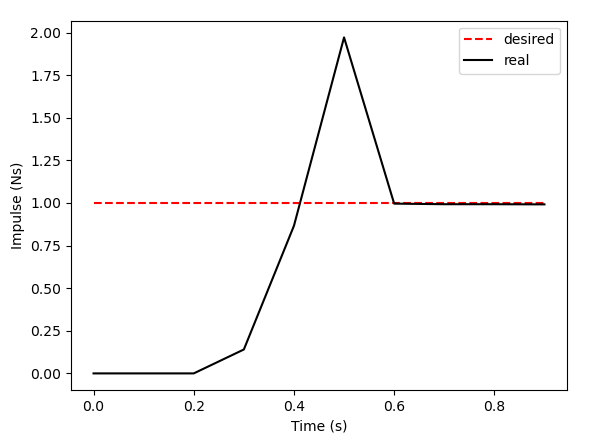
How far can we go with greedy inverse dynamics?
Why manipulation seems hard

How do we push in this direction?
How do we rotate further in presence of joint limits?


The Action-space problem in Robotics
If we had the wrong action space, the carrot problem hides a horribly difficult planning & control problem.
(Can no longer argue that set distance is CLF)
Motivating the Hybrid Action Space
q_{now}
q_{now}
Local Control
(Inverse Dynamics)
q_{next}
q_{next}
Actuator Placement if feasible
Can running RL / GCS / Online Planning in this action space give us significantly better results?
Same Story

.2s
~80s
The Hybrid Action Space
q_{now}
q_{now}
Local Control
(Inverse Dynamics)
q_{next}
q_{next}
Actuator Placement if feasible
Where do we place the actuators?
What do we mean by feasible?
Where do we do local control to?
How do we choose when to choose between each action?
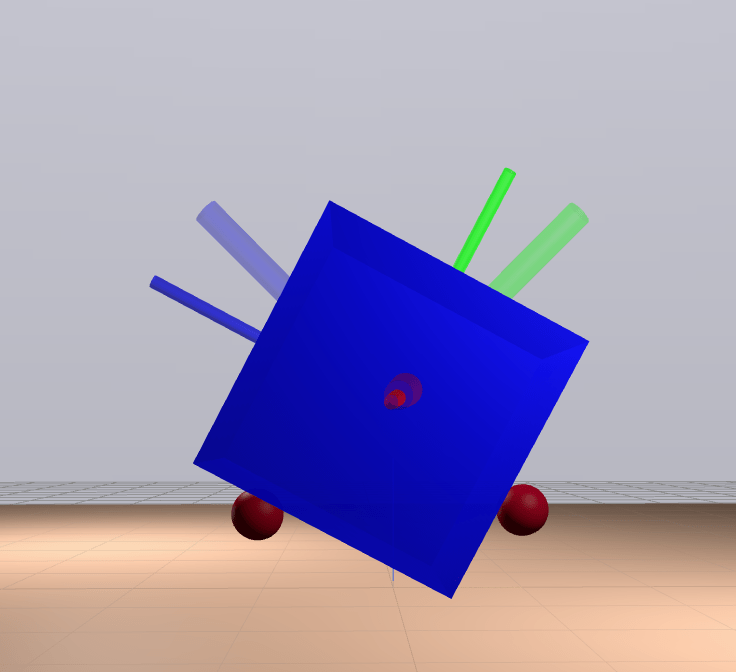
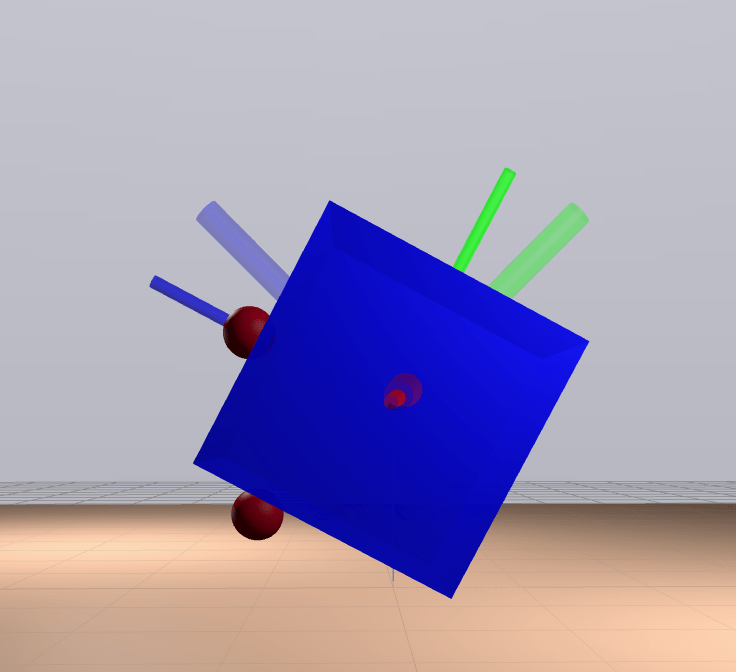
Quasi-dynamic Feasibility
We're feasible if we're stable.
Distance Metric induced by Reachable Set
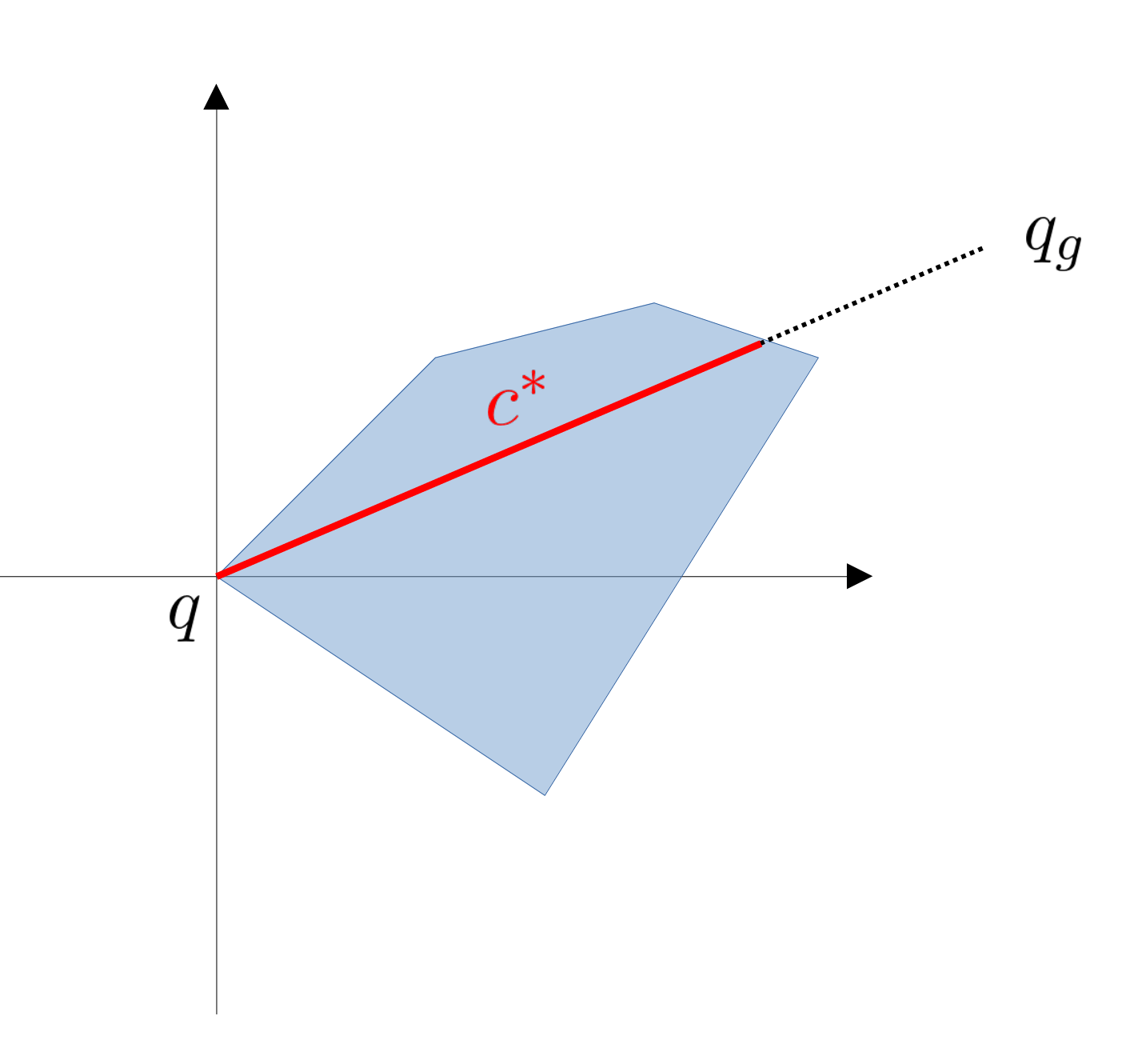
In a finite-input reachable set, the longer we can travel along the ray, the easier it is to reach.
Distance Metric induced by Reachable Set
In a finite-input reachable set, the longer we can travel along the ray, the easier it is to reach.
\begin{aligned}
\max_c \quad & c \\
\text{s.t.}\quad & c \geq 0 \\
& c v = \bar{q}^\mathrm{u}_+ \\
& \bar{q}^\mathrm{u}_+ = q^\mathrm{u}_+(\bar{q},\bar{u}) + \mathbf{B}^\mathrm{u}(\bar{q},\bar{u}) \delta u, \\
& \bar{\lambda}^\mathrm{u}_i = \lambda^\mathrm{u}(\bar{q},\bar{u})_i + \mathbf{\Lambda}^\mathrm{u}_i(\bar{q},\bar{u})\delta u \in \mathcal{K}_i, \\
& \|\delta u \|_2 \leq \varepsilon\}
\end{aligned}
\begin{aligned}
v = \frac{q - q_{goal}}{\|q - q_{goal}\|}
\end{aligned}
Distance Metric induced by Reachable Set

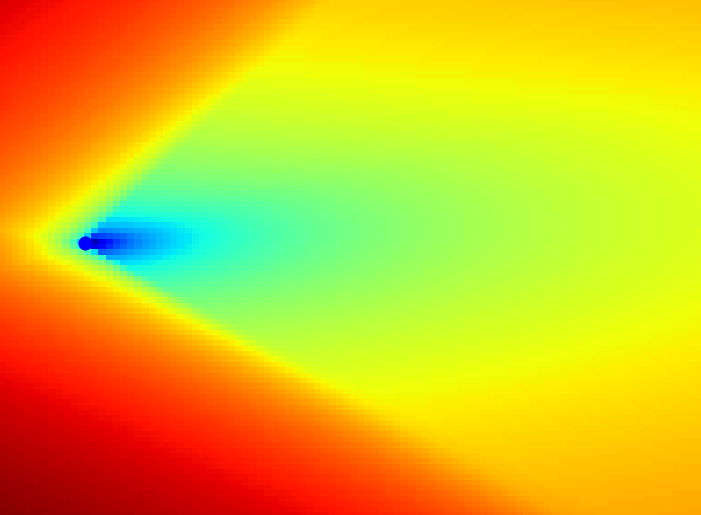

Then, the distance is defined by
\begin{aligned}
d(q;q_{goal}) = \frac{1}{(c^\star + {\color{red}\rho})}
\end{aligned}
regularization
Greedy Solution for Actuator Placement
Contact Sampling
The distance metric is incredibly useful for how we should find contacts to begin with.
\begin{aligned}
\min_{\tilde{q}^\mathrm{a}}\quad & d(\tilde{q}^\mathrm{a};q_{goal}) \\
\text{s.t.}\quad & \phi(q^\mathrm{a},q^\mathrm{u}) \geq 0
\end{aligned}
no penetration
Bad if the goal is towards left.
no penetration
movable actuators
Contact Sampling
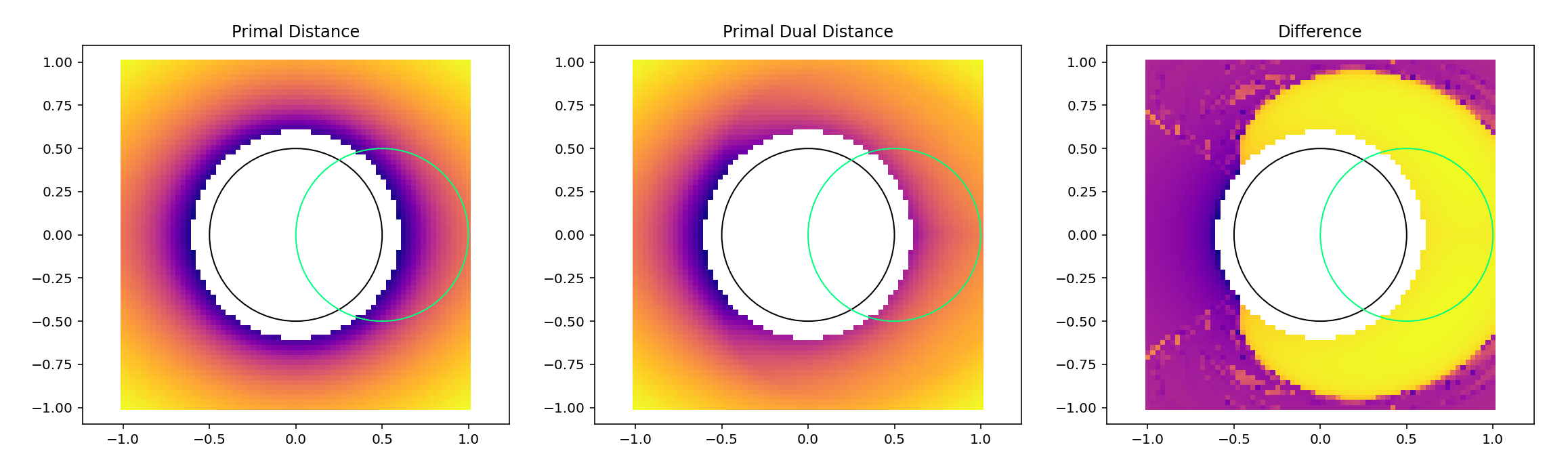
Contact Sampling
But doesn't distinguish between these two configurations

If goal is to move right, what's a better configuration?
Contact Sampling
\begin{aligned}
\min_{q^\mathrm{a}}\quad & d(q^\mathrm{a},q^\mathrm{u};q_{goal}) + \alpha {\color{red}r^2_{max}}\\
\text{s.t.}\quad & \phi(q^\mathrm{a},q^\mathrm{u}) \geq 0
\end{aligned}
We can add some robustness term from classical grasping
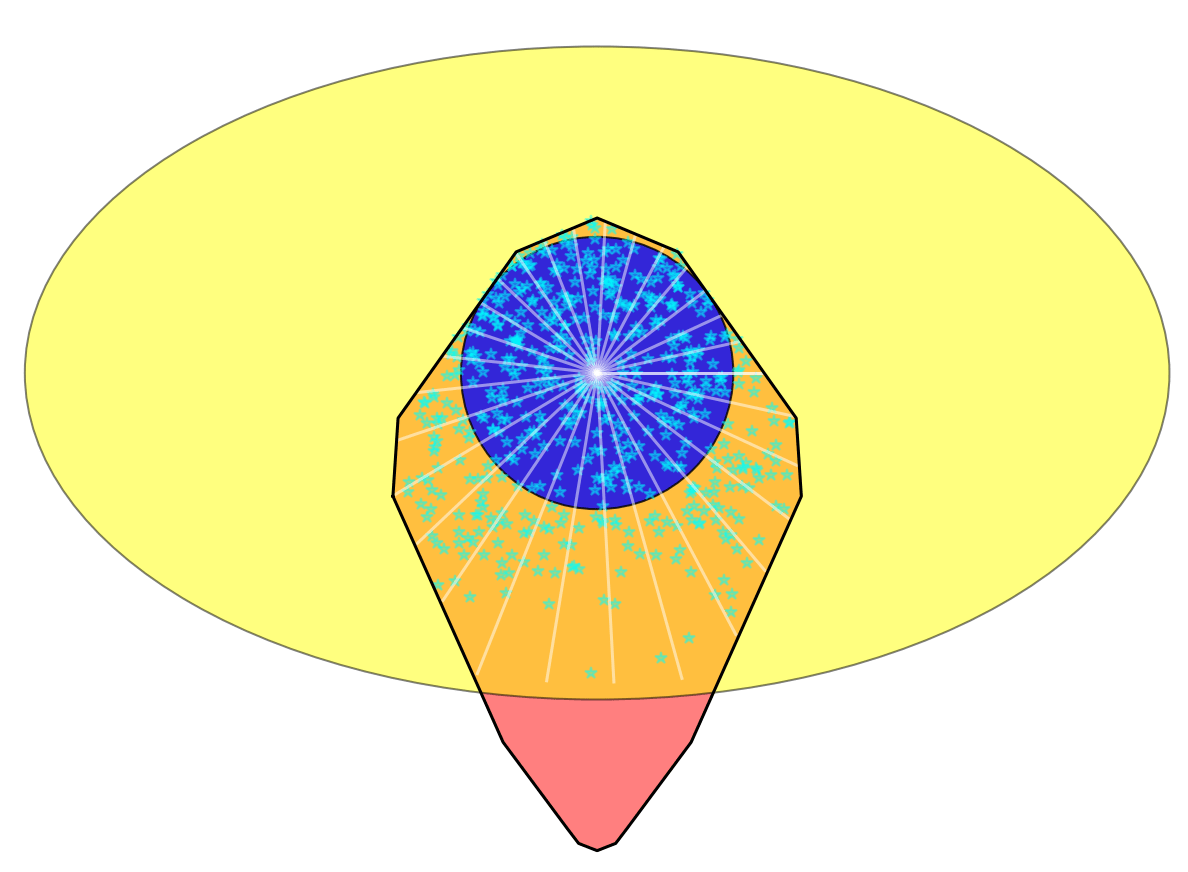
"Maximum inscribed sphere inside motion set".
Contact Sampling
But doesn't distinguish between these two configurations
If goal is to move right, what's a better configuration?
Simple Greedy Strategy
q_{now}
q_{now}
Local Control
(Inverse Dynamics)
q_{next}
q_{next}
Actuator Placement if feasible
Where do we place the actuators?
Where do we do local control to?
How do we choose when to choose between each action?
Find one which will minimize distance to goal according to distance metric.
Always go towards the goal.
Do actuator placement after time T.
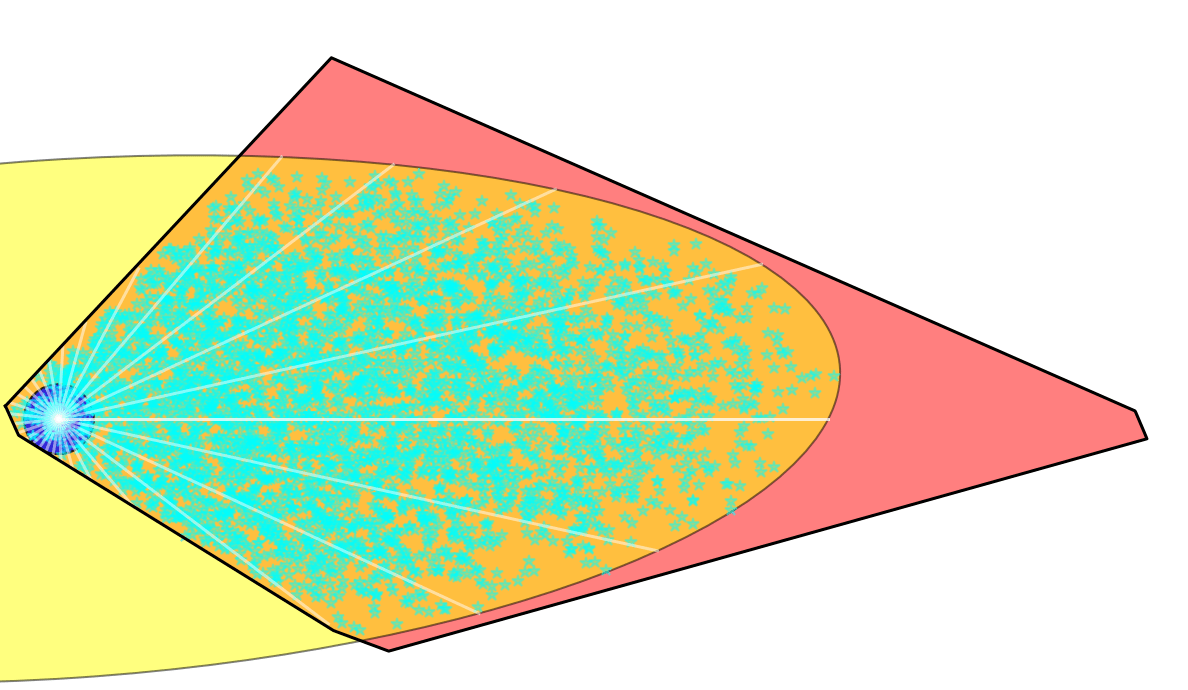
Greedy Planning
"Sparse graph" induces much less random behavior compared to 1-step based RRT.
Limitations


1
2
3
4
5
6


1
2
3
4
1
2
3
4
The hard manipulation problems are not greedy even in this space!
epsilon-Greedy extension
q_{now}
q_{now}
Local Control
(Inverse Dynamics)
q_{next}
q_{next}
Actuator Placement if feasible
Where do we place the actuators?
Where do we do local control to?
How do we choose when to choose between each action?
q_u^{subgoal} = \begin{cases}
q_u^{goal} & \text{ w.p.} \quad p_{id} \\
\sim {\color{red} \mathcal{M}(q)} & \text{ w.p. } \quad 1 - p_{id}
\end{cases}
\begin{cases}
\text{Regrasp} & \text{ w.p.} \quad p \\
\text{Inverse Dynamics for time}\quad T & \text{ w.p. } \quad 1 - p
\end{cases}
q_{next} = \begin{cases}
\text{Choose Best}(q^i_{next}) & \text{ w.p.} \quad p_{regrasp} \\
\text{Choose Random}(q^i_{next}) & \text{ w.p. } \quad 1 - p_{regrasp}
\end{cases}
q_{next}^i \sim \mathcal{P}
Selecting nodes for tree building
q_{now}
q_{now}
Local Control
(Inverse Dynamics)
q_{next}
q_{next}
Actuator Placement if feasible
How do we select which node to grow from?
q_{next} = \begin{cases}
\min_{q\in\mathcal{T}} d(q, q^u_{goal}) & \text{ w.p.} \quad p_{select} \\
\text{Choose Random}(q\in\mathcal{T}) & \text{ w.p. } \quad 1 - p_{select}
\end{cases}
Results for Tree Search
Tree Search
Greedy
Results for Tree Search
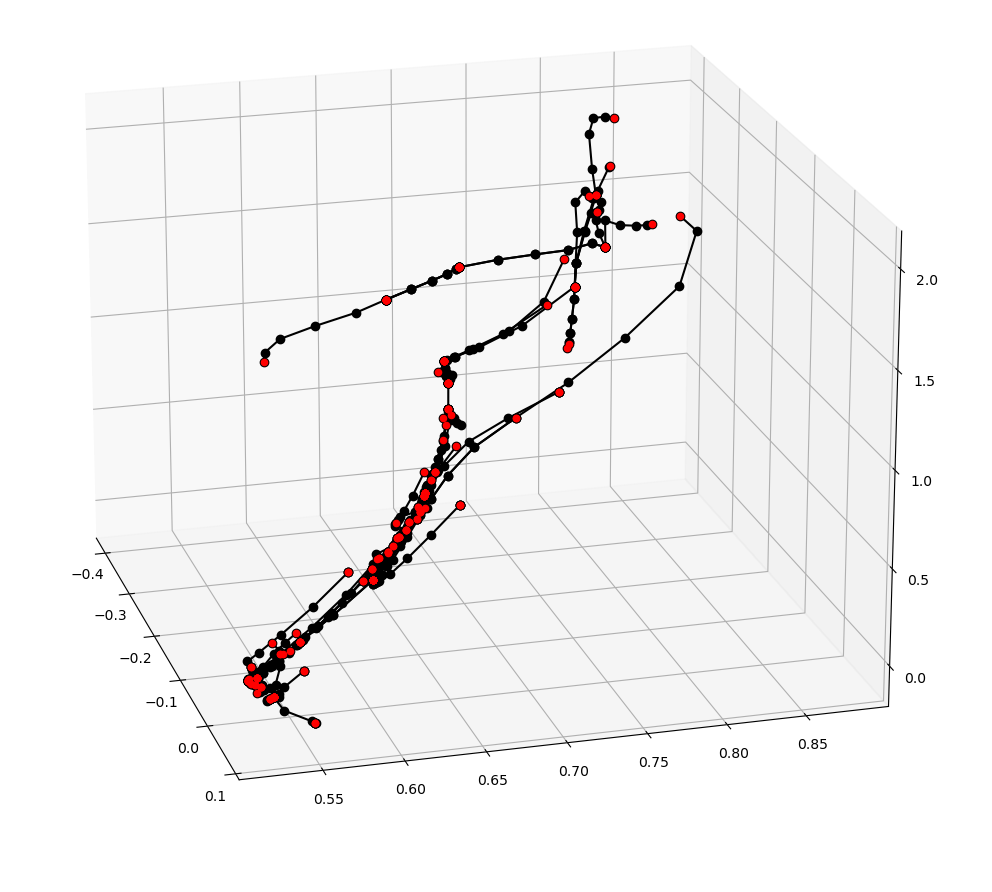
Why not do RRT?
1
2
3
4
1
2
3
4
Where do we do local control to?
q_u^{subgoal} = \begin{cases}
q_u^{goal} & \text{ w.p.} \quad p_{id} \\
\sim {\color{red} \mathcal{M}(q)} & \text{ w.p. } \quad 1 - p_{id}
\end{cases}
Why is sampling from a random direction in a motion set a better strategy compared to choosing subgoals at random?
Asking local control to do reach a subgoal here is very inefficient.
Why not do RRT?
1
2
3
4
1
2
3
4
Asking to go to locally feasible directions is more efficient.


-25.2334 / 0.0000
-2.5983 / 0.0023

-3.9133 / 0.0003
-11.6394 / 0.0002

-1.8232 / 0.0023
-3.6396 / 0.0001

-3.4371 / 0.0008
-2.4071 / 0.0011
-2.1063 / 0.0014
-12.7220 / 0.0001
-4.5312 / 0.0006
-2.7226 / 0.0011

-5.8354 / 0.0020
-10.0993 / 0.0001
-1.6193 / 0.0020
-4.9144 / 0.0007
-4.4108 / 0.0017
-4.3626 / 0.0010
-23.6115 / 0.0001
-3.1907 / 0.0022
-3.8313 / 0.0004
-5.4226 / 0.0005
-7.1475 / 0.0006
-2.7731 / 0.0024
-10.6818 / 0.002
-2.132 / 0.0007
-2.852 / 0.0020
-1.3987 / 0.0017
-7.1905 / 0.0001
-2.8716 / 0.0013
-2.0403 / 0.0012
-1.7866 / 0.0018
Min-weight Metric
\begin{aligned}
\max \quad & l \\
\text{s.t.} \quad & \bar{q}^\mathrm{u}_+ = q^\mathrm{u}_+(\bar{q},\bar{u}) + \mathbf{B}^\mathrm{u}(\bar{q},\bar{u}) \delta u, \\
& \bar{\lambda}^\mathrm{u}_i = \lambda^\mathrm{u}(\bar{q},\bar{u})_i + \mathbf{\Lambda}^\mathrm{u}_i(\bar{q},\bar{u})\delta u \\
& \bar{\lambda}^\mathrm{u}_i \geq l \\
& \|\delta u \|_2 \leq \varepsilon
\end{aligned}
Planning
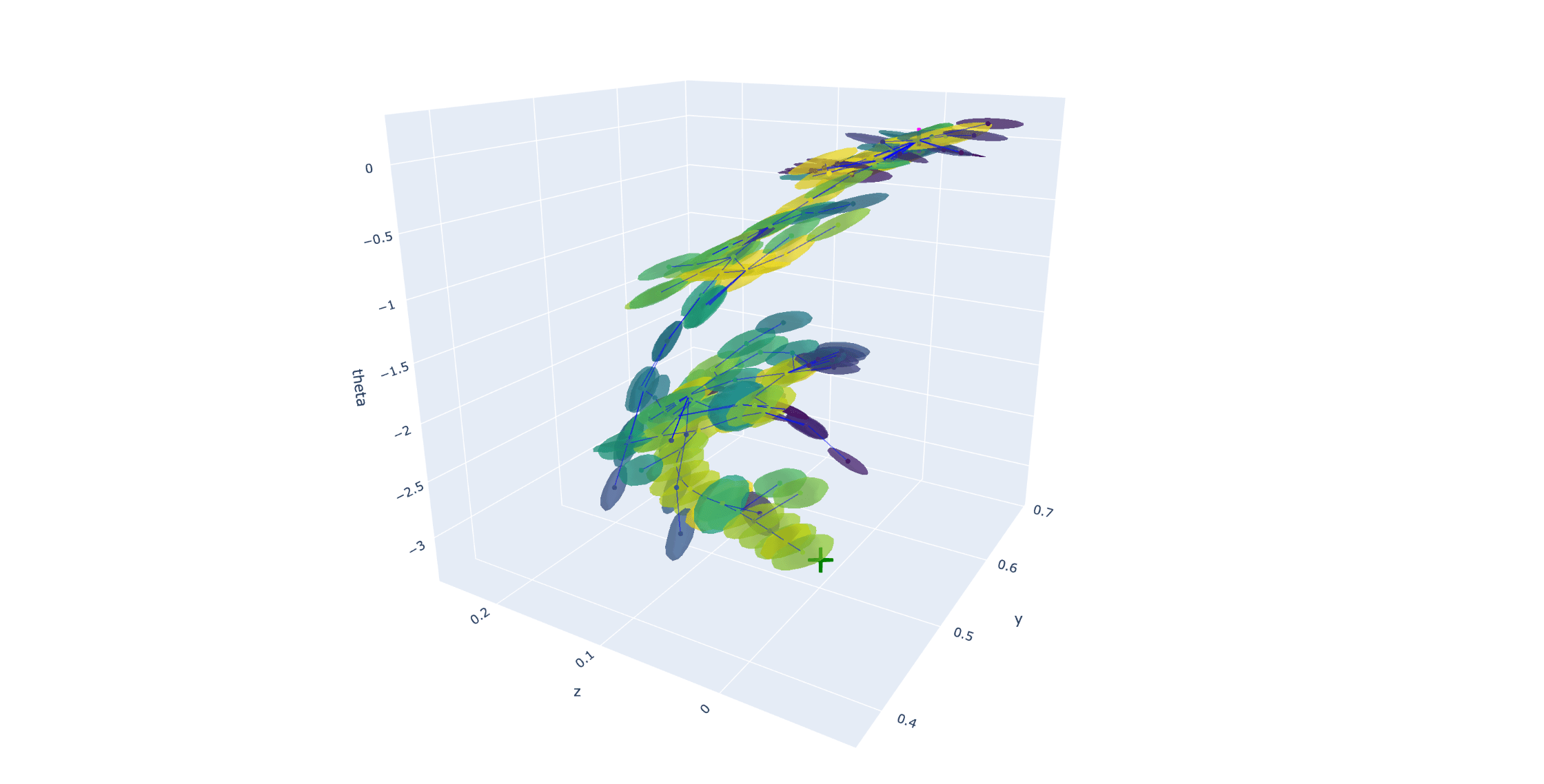
Better Distance Metric w. Motion Sets

Better Extension w. Inverse Dynamics
Better Goal-Conditioned Regrasping
How much does this improve previous planning?
Planning
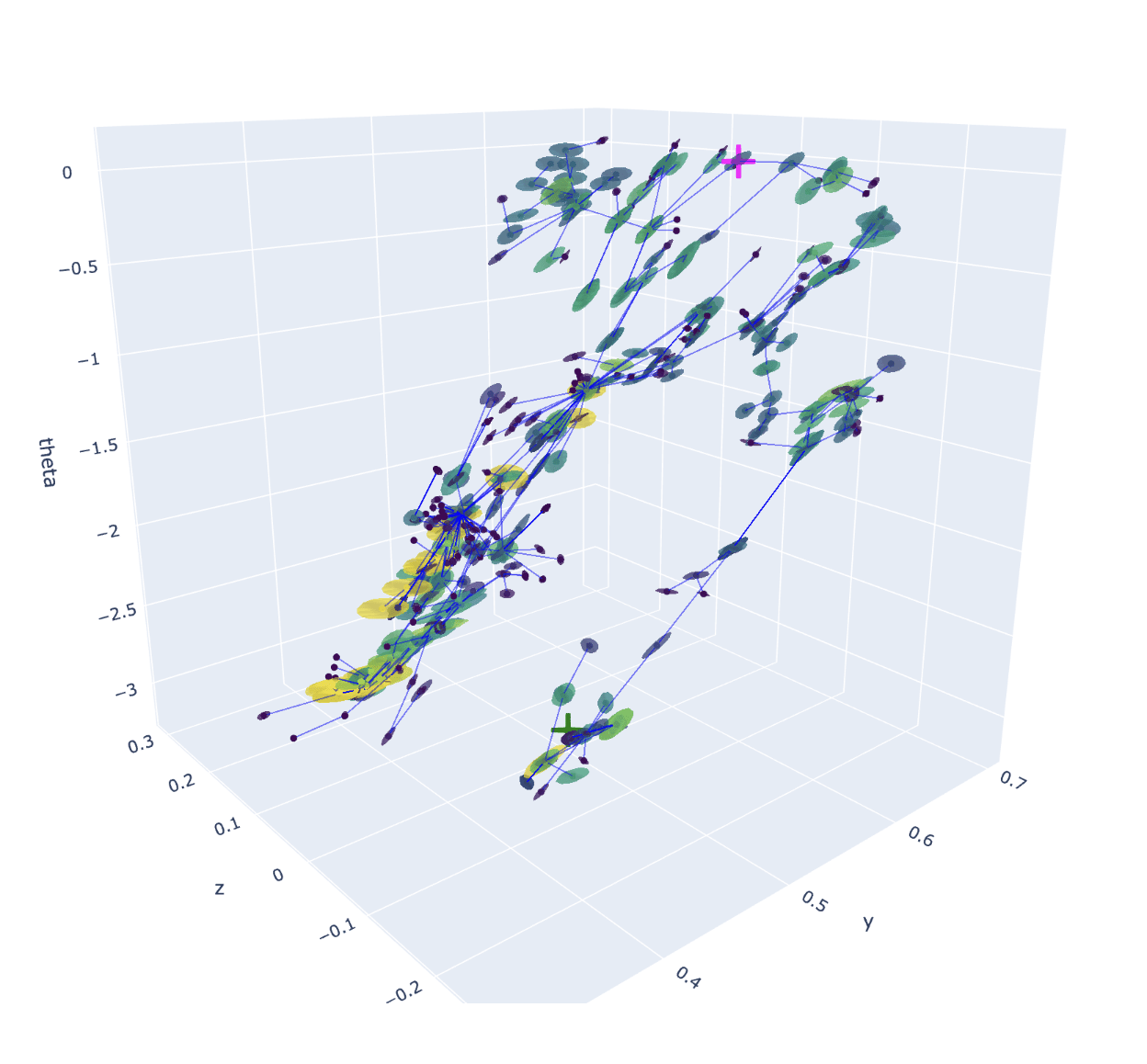
Example old tree
Example new tree
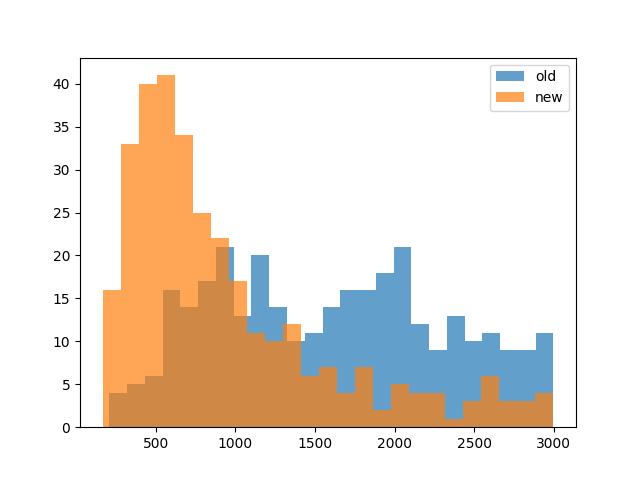
Number of nodes in trees for 320 successful RRTs from random initial object poses
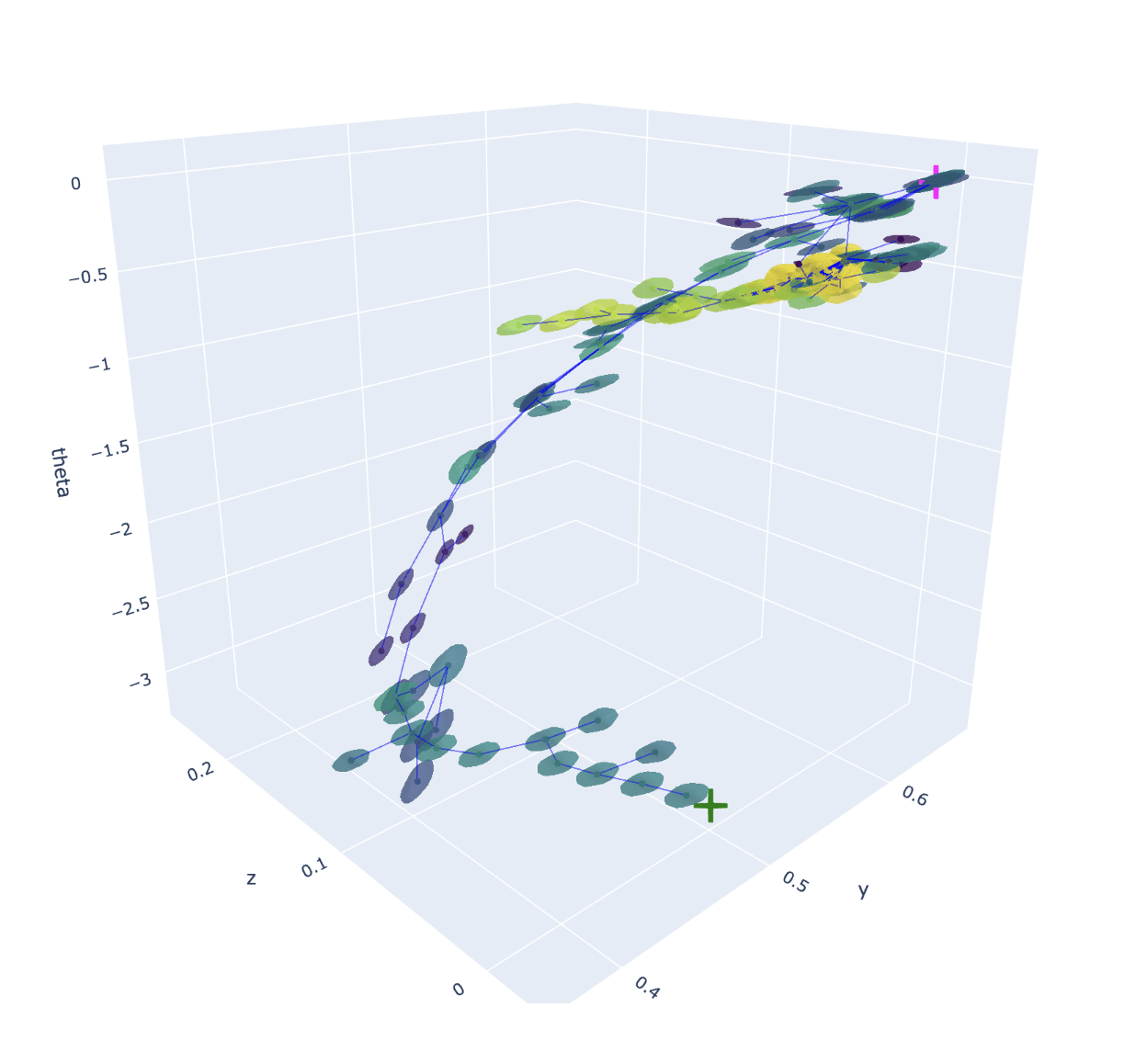
Planning
Current node q
Next node q
Inverse dynamics
Collision-free motion planning
When do we choose between options?
MotionSets
By Terry Suh




