Differentiable RL
Stream of Consciousness....
Policy Search Problem
\begin{aligned}
V(x_t,\alpha)\quad & \coloneqq \mathbb{E}_{w_{t:\infty}\sim p}\left[\sum^\infty_{t'=t} \gamma^{t'-t} r(x_{t'},u_{t'})\right] \\
\text{s.t.}\quad & x_{t+1}=f(x_t,u_t),\; u_t = \pi(x_t,\alpha) + w_t
\end{aligned}
Value Function
\begin{aligned}
\min_\alpha \mathbb{E}_{x_1\sim\eta}\left[V(x_1,\alpha)\right]
\end{aligned}
Initial distribution of rewards
Gaussian Policy
Deterministic & Differentiable Dynamics
Policy Optimization given Critic
Model Value Expansion
\begin{aligned}
V^H_\theta(x_1,\alpha) & \coloneqq \mathbb{E}_{w_{0:H-1}\sim p}\left[{\color{red}\sum^{H-1}_{t=0} \gamma^t r(x_t,u_t)} + {\color{blue}\gamma^H V_\theta(x_H)}\right] \\
\end{aligned}
Suppose we have a estimate of our value function / Q-function.
\begin{aligned}
V^H_\theta(x_1,\alpha) & \coloneqq \mathbb{E}_{w_{0:H-1}\sim p}\left[{\color{red}\sum^{H-1}_{t=0} \gamma^t r(x_t,u_t)} + {\color{blue}\gamma^H \mathbb{E}_{w_H}Q_\theta(x_H,u_H)}\right] \\
\end{aligned}
Model-Based Component
Model-Free Component
\begin{aligned}
H=\infty
\end{aligned}
\begin{aligned}
H=0
\end{aligned}
DDPG
BPTT
\begin{aligned}
u_H = \pi(x_H,\alpha) + w_H
\end{aligned}
Policy Optimization given Critic
Model Value Expansion
Suppose we have a estimate of our value function / Q-function.
\begin{aligned}
\frac{\partial}{\partial \alpha}V^H_\theta(x_1,\alpha) & \coloneqq \mathbb{E}_{w_{0:H-1}\sim p}\left[{\frac{\partial}{\partial\alpha}\color{red}\sum^{H-1}_{t=0} \gamma^t r(x_t,u_t)} + {\color{blue}\gamma^H \frac{\partial}{\partial\alpha}\mathbb{E}_{w_H}Q_\theta(x_H,u_H)}\right] \\
\end{aligned}
\begin{aligned}
u_H = \pi(x_H,\alpha) + w_H
\end{aligned}
Model-Based Component
Model-Free Component
\begin{aligned}
H=\infty
\end{aligned}
\begin{aligned}
H=0
\end{aligned}
DDPG
BPTT
Bias-Variance Tradeoff
Model Value Expansion
Suppose we have a estimate of our value function / Q-function.
\begin{aligned}
\frac{\partial}{\partial \alpha}V^H_\theta(x_1,\alpha) & \coloneqq \mathbb{E}_{w_{0:H-1}\sim p}\left[{\frac{\partial}{\partial\alpha}\color{red}\sum^{H-1}_{t=0} \gamma^t r(x_t,u_t)} + {\color{blue}\gamma^H \frac{\partial}{\partial\alpha}\mathbb{E}_{w_H}Q_\theta(x_H,u_H)}\right] \\
\end{aligned}
Model-Based Component
Model-Free Component
- Unbiased in Expectation
- Potentially High Variance
- Biased Estimate
- Low Variance
Bias-Variance Tradeoff
Model Value Expansion
Suppose we have a estimate of our value function / Q-function.
\begin{aligned}
\frac{\partial}{\partial \alpha}V^H_\theta(x_1,\alpha) & \coloneqq \mathbb{E}_{w_{0:H-1}\sim p}\left[{\frac{\partial}{\partial\alpha}\color{red}\sum^{H-1}_{t=0} \gamma^t r(x_t,u_t)} + {\color{blue}\gamma^H \frac{\partial}{\partial\alpha}\mathbb{E}_{w_H}Q_\theta(x_H,u_H)}\right] \\
\end{aligned}
Model-Based Component
Model-Free Component
- Unbiased in Expectation
- Potentially High Variance
- Biased Estimate
- Low Variance
Q1: How do we choose the horizon for a given system?
Horizon Selection
Model Value Expansion
Suppose we have a estimate of our value function / Q-function.
\begin{aligned}
\frac{\partial}{\partial \alpha}V^H_\theta(x_1,\alpha) & \coloneqq \mathbb{E}_{w_{0:H-1}\sim p}\left[{\frac{\partial}{\partial\alpha}\color{red}\sum^{H-1}_{t=0} \gamma^t r(x_t,u_t)} + {\color{blue}\gamma^H \frac{\partial}{\partial\alpha}\mathbb{E}_{w_H}Q_\theta(x_H,u_H)}\right] \\
\end{aligned}
Model-Based Component
Model-Free Component
- Unbiased in Expectation
- Potentially High Variance
- Biased Estimate
- Low Variance
Consider a simple rule:
\begin{aligned}
\min_H \quad & \textbf{Bias}\left[\frac{\partial}{\partial\alpha} V^H_\theta(x_0,\alpha)\right] \\
\text{s.t.} \quad & \textbf{Var}\left[\frac{\partial}{\partial\alpha} V^H_\theta(x_0,\alpha)\right] \leq C
\end{aligned}
Horizon Selection
Model Value Expansion
Suppose we have a estimate of our value function / Q-function.
\begin{aligned}
\frac{\partial}{\partial \alpha}V^H_\theta(x_1,\alpha) & \coloneqq \mathbb{E}_{w_{0:H-1}\sim p}\left[{\frac{\partial}{\partial\alpha}\color{red}\sum^{H-1}_{t=0} \gamma^t r(x_t,u_t)} + {\color{blue}\gamma^H \frac{\partial}{\partial\alpha}\mathbb{E}_{w_H}Q_\theta(x_H,u_H)}\right] \\
\end{aligned}
Model-Based Component
Model-Free Component
- Unbiased in Expectation
- Potentially High Variance
- Biased Estimate
- Low Variance
Consider a simple rule:
\begin{aligned}
\min_H \quad & \textbf{Bias}\left[\frac{\partial}{\partial\alpha} V^H_\theta(x_0,\alpha)\right] \\
\text{s.t.} \quad & \textbf{Var}\left[\frac{\partial}{\partial\alpha} V^H_\theta(x_0,\alpha)\right] \leq C
\end{aligned}
Maximize horizon to minimize bias
Until the variance is too difficult to handle
Horizon Selection
Model Value Expansion
Suppose we have a estimate of our value function / Q-function.
\begin{aligned}
\frac{\partial}{\partial \alpha}V^H_\theta(x_1,\alpha) & \coloneqq \mathbb{E}_{w_{0:H-1}\sim p}\left[{\frac{\partial}{\partial\alpha}\color{red}\sum^{H-1}_{t=0} \gamma^t r(x_t,u_t)} + {\color{blue}\gamma^H \frac{\partial}{\partial\alpha}\mathbb{E}_{w_H}Q_\theta(x_H,u_H)}\right] \\
\end{aligned}
Model-Based Component
Model-Free Component
- Unbiased in Expectation
- Potentially High Variance
- Biased Estimate
- Low Variance
Consider a simple rule:
\begin{aligned}
\max_H \quad & H \\
\text{s.t.} \quad & \textbf{Var}\left[\frac{\partial}{\partial\alpha} V^H_\theta(x_0,\alpha)\right] \leq C
\end{aligned}
Maximize horizon to minimize bias
Until the variance is too difficult to handle
Controlling Model Variance
Variance Reduction
Can use empirical variance, but tend to be difficult to estimate.
\begin{aligned}
\textbf{Var}\left[\frac{\partial}{\partial\alpha} V^H_\theta(x_0,\alpha)\right] & = \textbf{Var}\left[\frac{\partial}{\partial\alpha} \sum_{t=0}^{H-1} \gamma^t r_t\right]\\
& = \mathcal{O}(H^4 {\color{red} L_f^{4H}}L_\pi^{4H}/M)
\end{aligned}
Bound on First-order Gradient Variance given Lipschitz Constants
Controlling Dynamic Stiffness Alleviates Variance!
Controlling Model Variance
Variance Reduction
Can use empirical variance, but tend to be difficult to estimate.
\begin{aligned}
\textbf{Var}\left[\frac{\partial}{\partial\alpha} V^H_\theta(x_0,\alpha)\right] & = \textbf{Var}\left[\frac{\partial}{\partial\alpha} \sum_{t=0}^{H-1} \gamma^t r_t\right]\\
& = \mathcal{O}(H^4 {\color{red} L_f^{4H}}L_\pi^{4H}/M)
\end{aligned}
Bound on First-order Gradient Variance given Lipschitz Constants
Controlling Dynamic Stiffness Alleviates Variance!
\begin{aligned}
\max_H \quad & H \\
\text{s.t.} \quad & \textbf{Var}\left[\frac{\partial}{\partial\alpha} V^H_\theta(x_0,\alpha)\right] \leq C
\end{aligned}
Less Stiff Dynamics Leads to Longer Model-Based Horizon
Dynamics Smoothing
\begin{aligned}
q_1 = {\color{blue} \mathbb{E}_{w\sim \rho}}\left[f^\mathrm{u}(q_0,u_0 + {\color{blue}w})\right]
\end{aligned}
\begin{aligned}
q_1 = f^\mathrm{u}(q_0,u_0)
\end{aligned}

Non-smooth Contact Dynamics
Smooth Surrogate Dynamics

\begin{aligned}
q^\mathrm{u}_1
\end{aligned}
\begin{aligned}
u_0
\end{aligned}
No Contact
Contact
\begin{aligned}
u_0
\end{aligned}
\begin{aligned}
q^\mathrm{u}_1
\end{aligned}
Averaged
Differentiable Simulator Comes with a Knob on Smoothness
Bias-Variance Tradeoff
Horizon Expansion
Dynamic Smoothing
High Gradient Estimation Variance
Low Gradient Estimation Bias
(Due to value estimation)
Low Gradient Estimation Variance
High Gradient Estimation Bias
(due to wrong dynamics)
Bias-Variance Tradeoff
Horizon Expansion
Dynamic Smoothing
High Dynamics Bias
Low Policy Gradient Variance
High Gradient Estimation Variance
Low Gradient Estimation Bias
(Due to value estimation)
Low Gradient Estimation Variance
High Gradient Estimation Bias
(due to wrong dynamics)
High Function Estimation Bias
Low Policy Gradient Variance
"The Path of Manageable Variance"
Bias-Variance Tradeoff
Horizon Expansion
Dynamic Smoothing
High Dynamics Bias
Low Policy Gradient Variance
High Gradient Estimation Variance
Low Gradient Estimation Bias
(Due to value estimation)
Low Gradient Estimation Variance
High Gradient Estimation Bias
(due to wrong dynamics)
High Function Estimation Bias
Low Policy Gradient Variance
"The Path of Manageable Variance"
But how does annealing help?
If we only cared about low variance, might as well just run H=0 DDPG!
Does annealing help with value function estimation?
\begin{aligned}
q^\mathrm{u}_0
\end{aligned}
\begin{aligned}
q^\mathrm{a}_0
\end{aligned}
\begin{aligned}
q^\mathrm{u}_{goal}
\end{aligned}
\begin{aligned}
u
\end{aligned}
\begin{aligned}
\min_{u_0} \quad & \frac{1}{2}{\color{red} \mathbb{E}_{w\sim \rho}}\|f^\mathrm{u}(q_0,u_0 {\color{red} + w}) - q^\mathrm{u}_{goal}\|^2
\end{aligned}
Reinforcement Learning
Cost
Contact
No Contact
Averaged
\begin{aligned}
u_0
\end{aligned}
Dynamic Smoothing
\begin{aligned}
\min_{u_0} \quad & \frac{1}{2}\|{\color{red} \mathbb{E}_{w\sim \rho}}\left[f^\mathrm{u}(q_0,u_0 {\color{red} + w})\right] - q^\mathrm{u}_{goal}\|^2
\end{aligned}
Averaged
Contact
No Contact
No Contact
Previous analysis doesn't capture
dynamic smoothing benefits...
Dynamic Smoothing vs. Diffusion?
Score-based Generative Modeling
Policy Optimization through Contact
True data distribution lives on manifold, gradient is too stiff.
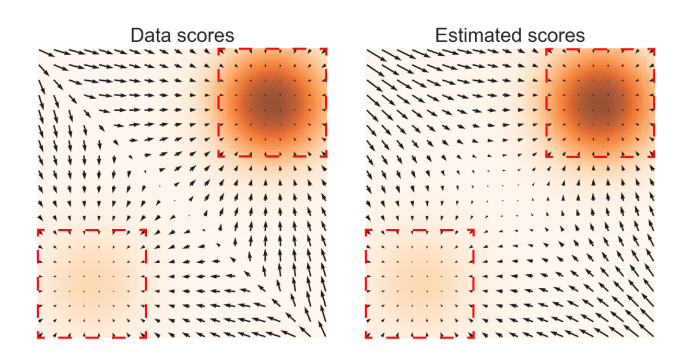
True contact dynamics is too stiff
Value Function Estimation
Model Value Expansion
Suppose we have a estimate of our value function / Q-function.
\begin{aligned}
\frac{\partial}{\partial \alpha}V^H_\theta(x_1,\alpha) & \coloneqq \mathbb{E}_{w_{0:H-1}\sim p}\left[{\frac{\partial}{\partial\alpha}\color{red}\sum^{H-1}_{t=0} \gamma^t r(x_t,u_t)} + {\color{blue}\gamma^H \frac{\partial}{\partial\alpha}\mathbb{E}_{w_H}Q_\theta(x_H,u_H)}\right] \\
\end{aligned}
Model-Based Component
Model-Free Component
Q2: What's the right way to estimate the value,
1. Given that we will be using gradients,
2. Given that we chose some horizon H?
Bounding Gradient Bias
\begin{aligned}
\min_\alpha \mathbb{E}_{x_1\sim\eta}\left[V(x_1,\alpha)\right]
\end{aligned}
Original Problem (True Value)
Surrogate Problem
\begin{aligned}
\min_\alpha \mathbb{E}_{x_1\sim\eta}\left[V^H_\theta(x_1,\alpha)\right]
\end{aligned}
\begin{aligned}
\textbf{Bias}(V^H_\theta)\coloneqq \left\|\frac{\partial}{\partial \alpha}\mathbb{E}_{x_1\sim\eta}\left[V(x_1,\alpha)\right] - \frac{\partial}{\partial \alpha}\mathbb{E}_{x_1\sim\eta}\left[V^H_\theta(x_1,\alpha)\right]\right\|^2
\end{aligned}
Gradient Bias (Quantity of Interest)
Bounding Gradient Bias
\begin{aligned}
\textbf{Bias}(V^H_\theta)\coloneqq \left\|\frac{\partial}{\partial \alpha}\mathbb{E}_{x_1\sim\eta}\left[V(x_1,\alpha)\right] - \frac{\partial}{\partial \alpha}\mathbb{E}_{x_1\sim\eta}\left[V^H_\theta(x_1,\alpha)\right]\right\|^2
\end{aligned}
Gradient Bias (Quantity of Interest)
\begin{aligned}
\frac{\partial}{\partial\alpha}V^H_\theta(x_1,\alpha) & \coloneqq \mathbb{E}_{w_{0:H-1}\sim p}\left[{\color{red}\frac{\partial}{\partial\alpha}\sum^{H-1}_{t=0} \gamma^t r(x_t,u_t)} + {\color{blue}\gamma^H \frac{\partial}{\partial \alpha}\mathbb{E}_{w_H}Q_\theta(x_H,u_H,\alpha)}\right] \\
\end{aligned}
\begin{aligned}
\frac{\partial}{\partial \alpha} V(x_1,\alpha) & \coloneqq \mathbb{E}_{w_{0:H-1}\sim p}\left[{\color{red}\frac{\partial}{\partial\alpha}\sum^{H-1}_{t=0} \gamma^t r(x_t,u_t)} + {\color{blue}\gamma^H \frac{\partial}{\partial\alpha}\mathbb{E}_{w_H}Q(x_H,u_H,\alpha)}\right] \\
\end{aligned}
This part is unbiased
Bounding Gradient Bias
\begin{aligned}
\textbf{Bias}(V^H_\theta)\coloneqq \left\|\frac{\partial}{\partial \alpha}\mathbb{E}_{x_1\sim\eta}\left[V(x_1,\alpha)\right] - \frac{\partial}{\partial \alpha}\mathbb{E}_{x_1\sim\eta}\left[V^H_\theta(x_1,\alpha)\right]\right\|^2
\end{aligned}
Gradient Bias (Quantity of Interest)
\begin{aligned}
\textbf{Bias}(V_\theta^H) & = \gamma^{2H}\left\|\mathbb{E}_{x_H\sim \mu_H}\mathbb{E}_{w_H\sim p}\left[\frac{\partial}{\partial\alpha}Q(x_H,u_H) - \frac{\partial}{\partial \alpha}Q_\theta(x_H,u_H)\right]\right\|^2 \\
\end{aligned}
\begin{aligned}
\textbf{Bias}(V_\theta^H) & = \gamma^{2H}\left\|\mathbb{E}_{x_H\sim \mu_H}\left[\frac{\partial}{\partial\alpha}V(x_H) - \frac{\partial}{\partial \alpha}V_\theta(x_H)\right]\right\|^2 \\
\end{aligned}
State Value Estimation
State-Action Value Estimation
Gradients need to match well over distribution of states at time t.
Push-forward measure from initial distribution under closed-loop dynamics
\begin{aligned}
u_H = \pi(x_H,\alpha) + w_H
\end{aligned}
Bounding Gradient Bias
Gradient Bias (Quantity of Interest)
\begin{aligned}
\textbf{Bias}(V_\theta^H) & = \gamma^{2H}\left\|\mathbb{E}_{x_H\sim \mu_H}\left[\frac{\partial}{\partial\alpha}V(x_H) - \frac{\partial}{\partial \alpha}V_\theta(x_H)\right]\right\|^2 \\
\end{aligned}
Usual Regression for Value Function Estimation
\begin{aligned}
\min_\theta \mathbb{E}_{(x,x',r)\sim\beta}\left[(V_\theta(x) - \left(r + \gamma V_\theta(x')\right)^2\right]
\end{aligned}
\begin{aligned}
\min_\theta \mathbb{E}_{(x,u,r,x',u')\sim\beta}\left[(Q_\theta(x,u) - \left(r + \gamma Q_\theta(x',u')\right)^2\right]
\end{aligned}
Sources of Bias
1. Distribution of data is from different behavior policy.
2. Accurate modeling of value does not guarantee modeling of gradients.
3. Bootstrapping bias.
Value Function Estimation
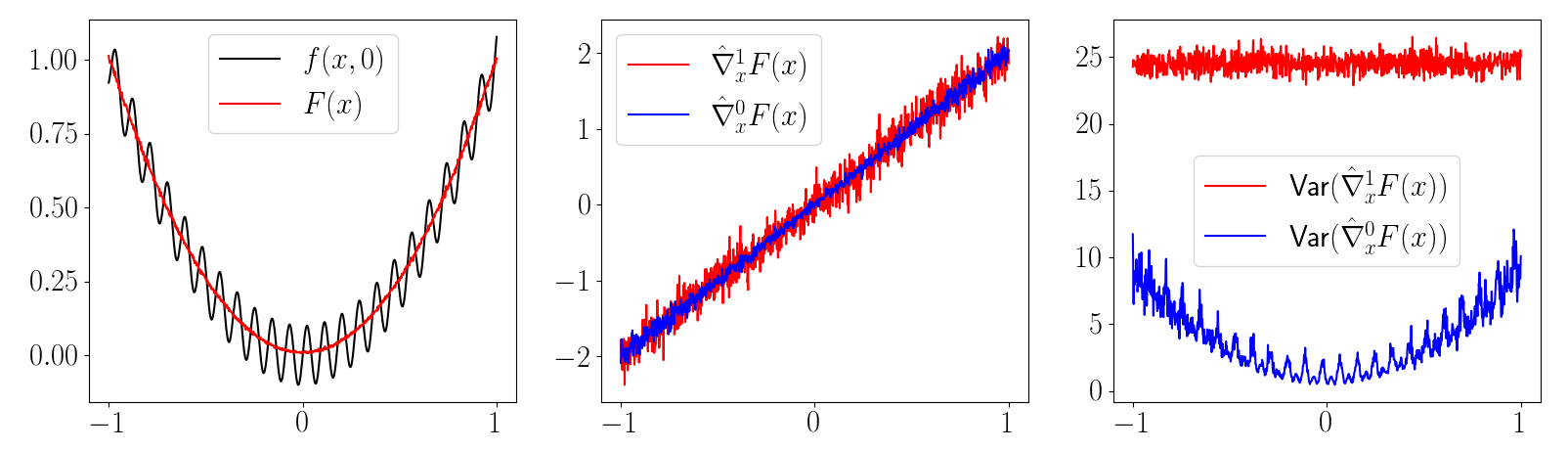
Finite-error modeling of value does not guarantee good gradients.
DDPG is equally questionable?
Value Gradient Boostrapping
\begin{aligned}
\textbf{Bias}(V^H_\theta)\coloneqq \left\|\frac{\partial}{\partial \alpha}\mathbb{E}_{x_1\sim\eta}\left[V(x_1,\alpha)\right] - \frac{\partial}{\partial \alpha}\mathbb{E}_{x_1\sim\eta}\left[V^H_\theta(x_1,\alpha)\right]\right\|^2
\end{aligned}
Gradient Bias (Quantity of Interest)
\begin{aligned}
\textbf{Bias}(V_\theta^H) & = \gamma^{2H}\left\|\mathbb{E}_{x_H\sim \mu_H}\left[\frac{\partial}{\partial\alpha}V(x_H) - \frac{\partial}{\partial \alpha}V_\theta(x_H)\right]\right\|^2 \\
& = \gamma^{2H}\left\|\mathbb{E}_{x_H\sim \mu_H}\left[{\color{red}\frac{\partial V}{\partial x_H}}\frac{\partial x_H}{\partial\alpha} - {\color{red}\frac{\partial V_\theta}{\partial x_H}}\frac{\partial x_H}{\partial \alpha}\right]\right\|^2 \\
\end{aligned}
State Value Estimation
In known dynamics case, suffices to estimate dV/dx well.
Value Gradient Boostrapping
\begin{aligned}
V(x_t,\alpha) = \mathbb{E}_{w_t}\left[r_t + \gamma V(x_{t+1},\alpha)\right]
\end{aligned}
Bellman Equation
Consider the boostrapping equation for TD(0)
\begin{aligned}
\min_\theta \mathbb{E}_{x_t,r_t,x_{t+1}\sim\mathcal{D}}\left\|V_\theta(x_t) - \mathbb{E}_{w_t}\left[r_t + \gamma V_\theta(x_{t+1})\right]\right\|^2
\end{aligned}
Value Gradient Boostrapping
\begin{aligned}
V(x_t,\alpha) = \mathbb{E}_{w_t}\left[r_t + \gamma V(x_{t+1},\alpha)\right]
\end{aligned}
Bellman Equation
Consider the boostrapping equation for TD(0)
\begin{aligned}
\min_\theta \mathbb{E}_{x_t,r_t,x_{t+1}\sim\mathcal{D}}\left\|V_\theta(x_t) - \mathbb{E}_{w_t}\left[r_t + \gamma V_\theta(x_{t+1})\right]\right\|^2
\end{aligned}
\begin{aligned}
{\color{red}\frac{\partial V}{\partial x_t}} = \mathbb{E}_{w_t}\left[\frac{\partial r_t}{\partial x_t} + \frac{\partial r_t}{\partial u_t}\frac{\partial u_t}{\partial x_t} + \gamma{\color{red}\frac{\partial V}{\partial x_{t+1}}}\left[\frac{\partial x_{t+1}}{\partial x_t} + \frac{\partial x_{t+1}}{\partial u_t}\frac{\partial u_t}{\partial x_t}\right]\right]
\end{aligned}
Bellman Gradient Equation
We can boostrap the gradient directly!
\begin{aligned}
\min_\theta \mathbb{E}_{x_t,u_t,r_t,x_{t+1}\sim\mathcal{D}}\left\|{\color{red}z_\theta(x_t)} - \mathbb{E}_{w_t}\left[\frac{\partial r_t}{\partial x_t} + \frac{\partial r_t}{\partial u_t}\frac{\partial u_t}{\partial x_t} + \gamma{\color{red} z_\theta(x_{t+1})}\left[\frac{\partial x_{t+1}}{\partial x_t} + \frac{\partial x_{t+1}}{\partial u_t}\frac{\partial u_t}{\partial x_t}\right]\right]\right\|^2
\end{aligned}
TD(k) Bootstrapping
\begin{aligned}
\min_\theta \mathbb{E}_{x_t,u_t,r_t,x_{t+1}\sim\mathcal{D}}\left\|{\color{red}z_\theta(x_t)} - \mathbb{E}_{w_{t:t+H}\sim p}\left[\frac{\mathrm{d}}{\mathrm{d} x_t}\sum_{t'=t}^{t+H-1} \gamma^{t'-t}r_{t'} + \gamma^{H}{\color{red} z_\theta(x_{t+H})}\left[\frac{\mathrm{d} x_{t+H}}{\mathrm{d} x_t}\right]\right]\right\|^2
\end{aligned}
Actor Loss
\begin{aligned}
\frac{\partial}{\partial \alpha}V^H_\theta(x_1,\alpha) & \coloneqq \mathbb{E}_{w_{0:H-1}\sim p}\left[{\frac{\partial}{\partial\alpha}\sum^{H-1}_{t=0} \gamma^t r_t} + \gamma^H\frac{\partial}{\partial\alpha}V_\theta(x_H)\right] \\
& = \mathbb{E}_{w_{0:H-1}\sim p}\left[{\frac{\partial}{\partial\alpha}\sum^{H-1}_{t=0} \gamma^t r_t} + \gamma^H{\color{red} \frac{\partial V}{\partial x_H}}\frac{\partial x_H}{\partial \alpha}\right] \\
& = \mathbb{E}_{w_{0:H-1}\sim p}\left[\frac{\partial}{\partial\alpha}\sum^{H-1}_{t=0} \gamma^t r_t + \gamma^H {\color{red} z_\theta(x_{H})}\frac{\partial x_{H}}{\partial\alpha}\right]
\end{aligned}
TD(k) Gradient Boostrapping (Critic Loss), can be weighted for TD Lambda
TD(k) Bootstrapping
\begin{aligned}
\min_\theta \mathbb{E}_{x_t,u_t,r_t,x_{t+1}\sim\mathcal{D}}\left\|{\color{red}z_\theta(x_t)} - \mathbb{E}_{w_{t:t+H}\sim p}\left[\frac{\mathrm{d}}{\mathrm{d} x_t}\sum_{t'=t}^{t+H-1} \gamma^{t'-t}r_{t'} + \gamma^{H}{\color{red} z_\theta(x_{t+H})}\left[\frac{\mathrm{d} x_{t+H}}{\mathrm{d} x_t}\right]\right]\right\|^2
\end{aligned}
TD(k) Gradient Boostrapping (Critic Loss), can be weighted for TD Lambda
Actor Loss
\begin{aligned}
\frac{\partial}{\partial \alpha}V^H_\theta(x_1,\alpha) & = \mathbb{E}_{w_{0:H-1}\sim p}\left[\frac{\partial}{\partial\alpha}\sum^{H-1}_{t=0} \gamma^t r_t + \gamma^H {\color{red} z_\theta(x_{H})}\frac{\partial x_{H}}{\partial\alpha}\right]
\end{aligned}
Critic H and Actor H does need not be the same!
Hypothesis: Actually it's beneficial to use the same H
1. Distribution of data is from different behavior policy.
2. Accurate modeling of value does not guarantee modeling of gradients.
3. Bootstrapping bias.
TD(k) Bootstrapping
\begin{aligned}
\min_\theta \mathbb{E}_{x_t,u_t,r_t,x_{t+1}\sim\mathcal{D}}\left\|{\color{red}z_\theta(x_t)} - \mathbb{E}_{w_{t:t+H}\sim p}\left[\frac{\mathrm{d}}{\mathrm{d} x_t}\sum_{t'=t}^{t+H-1} \gamma^{t'-t}r_{t'} + \gamma^{H}{\color{red} z_\theta(x_{t+H})}\left[\frac{\mathrm{d} x_{t+H}}{\mathrm{d} x_t}\right]\right]\right\|^2
\end{aligned}
Sources of Bias


TD(k) Gradient Boostrapping (Critic Loss), can be weighted for TD Lambda
Gradient Boostrapping Performance
\begin{aligned}
\min_\theta \mathbb{E}_{x_t,u_t,r_t,x_{t+1}\sim\mathcal{D}}\left\|{\color{red}z_\theta(x_t)} - \mathbb{E}_{w_{t:t+H}\sim p}\left[\frac{\mathrm{d}}{\mathrm{d} x_t}\sum_{t'=t}^{t+H-1} \gamma^{t'-t}r_{t'} + \gamma^{H}{\color{red} z_\theta(x_{t+H})}\left[\frac{\mathrm{d} x_{t+H}}{\mathrm{d} x_t}\right]\right]\right\|^2
\end{aligned}
Relies on Gradients from Models
High does dynamic stiffness affect estimation error?
TD(k) Gradient Boostrapping (Critic Loss), can be weighted for TD Lambda
Variance for long H and stiff dynamics tells us that
we should use less H for stiff dynamics!
Smoothing Conditioned Value Gradient
Critic Learning
Smoothing Conditioned Value Gradient
\begin{aligned}
\min_\theta \mathbb{E}_{x_t,u_t,r_t,x_{t+1}\sim\mathcal{D}}\left\|{\color{red}z_\theta(x_t,\rho)} - \mathbb{E}_{w_{t:t+H}\sim p}\left[\frac{\mathrm{d}}{\mathrm{d} x_t}\sum_{t'=t}^{t+H-1} \gamma^{t'-t}r_{t'} + \gamma^{H}{\color{red} z_\theta(x_{t+H},\rho)}\left[\frac{\mathrm{d} x_{t+H}}{\mathrm{d} x_t}\right]\right]\right\|^2
\end{aligned}
\begin{aligned}
z_\theta(x,{\color{red}\rho}) = \frac{\partial}{\partial x}V(x,{\color{red}\rho})
\end{aligned}
Actor Learning
\begin{aligned}
\frac{\partial}{\partial \alpha}V^H_\theta(x_1,\alpha) & = \mathbb{E}_{w_{0:H-1}\sim p}\left[\frac{\partial}{\partial\alpha}\sum^{H-1}_{t=0} \gamma^t r_t + \gamma^H {\color{red} z_\theta(x_{H},\rho)}\frac{\partial x_{H}}{\partial\alpha}\right]
\end{aligned}
Anneal H and rho simultaneously
(Noise Conditioned) Score Function under the
Control as Inference Interpretation
Differentiable Simulators
TinyDiffSim
gradSim
dFlex
Warp
Brax
Have my own preference on how I would implement it,
but not willing to go through the giant engineering time.
Mujoco FD
Personally have more trust in these,
but don't like soft contact models.
DiffRL
By Terry Suh




