






Leonardo Petrini
PhD Student @ Physics of Complex Systems Lab, EPFL Lausanne
Vardan Papyana, X. Y. Hanb and David L. Donoho
train error
train loss
Vardan Papyana, X. Y. Hanb and David L. Donoho
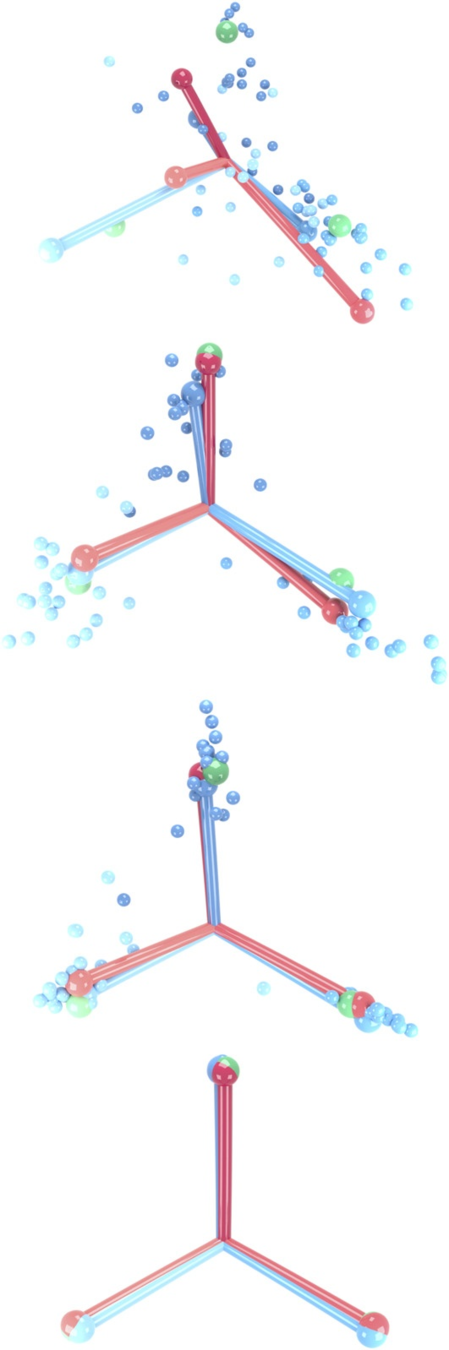
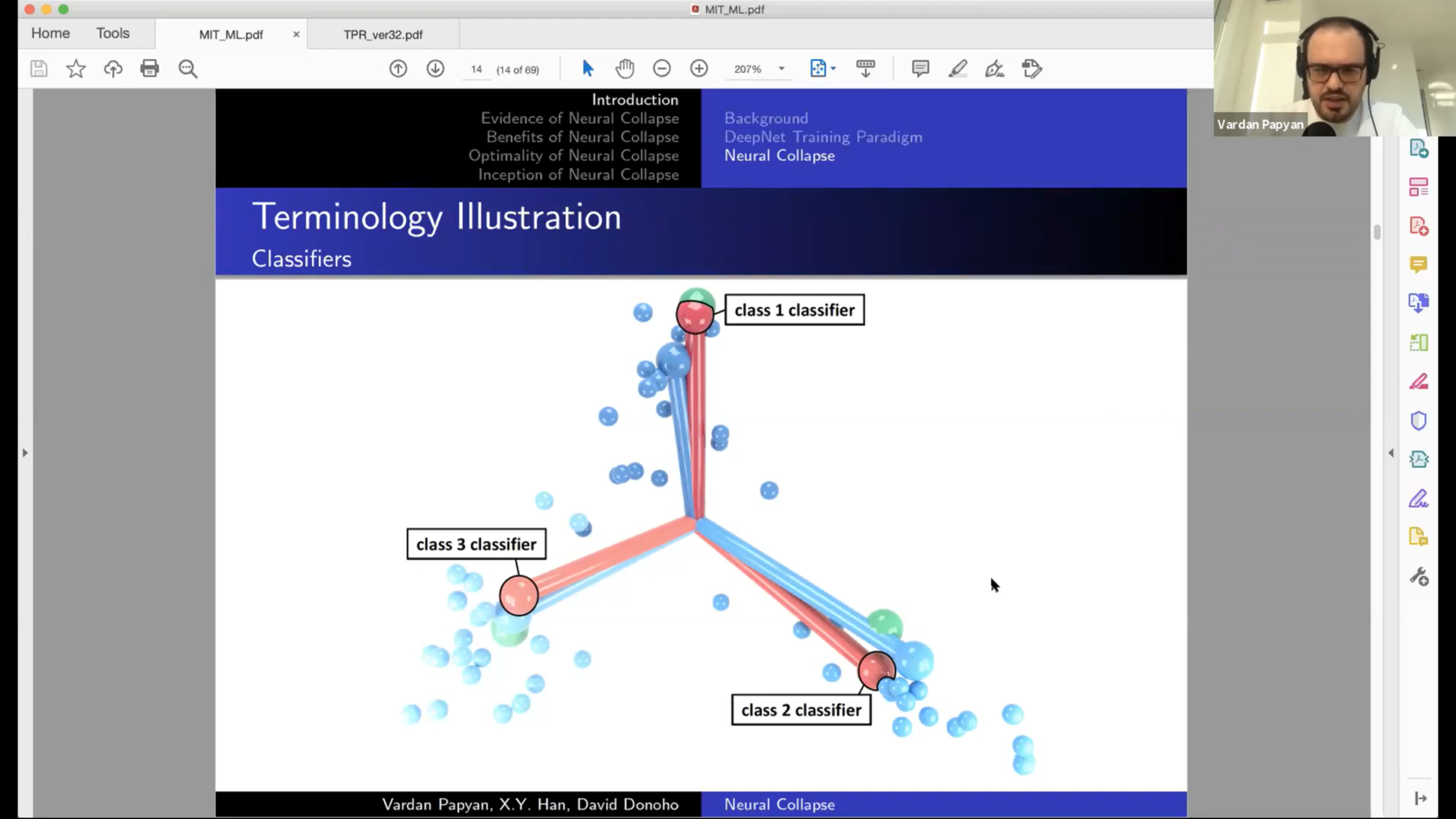
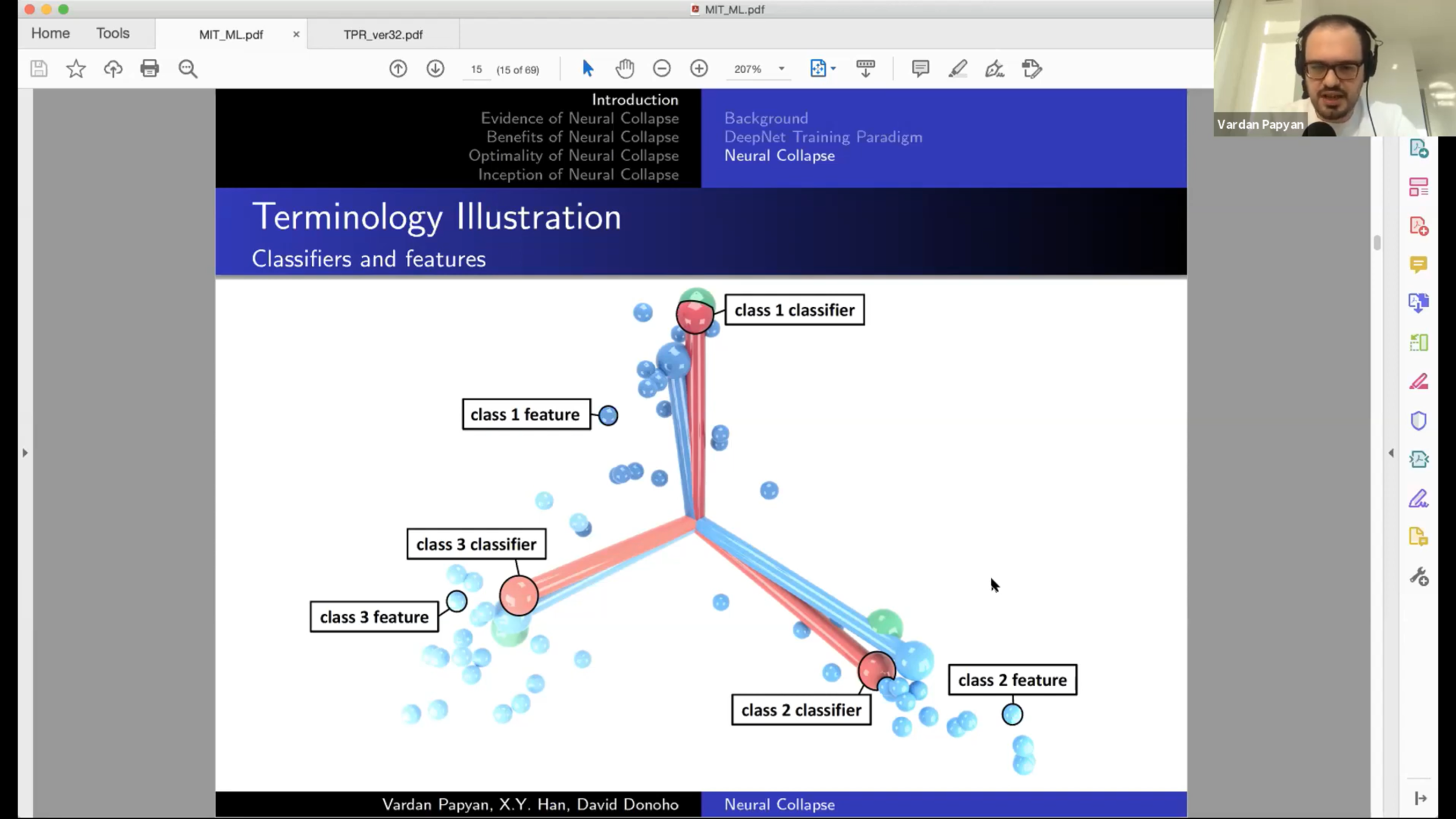
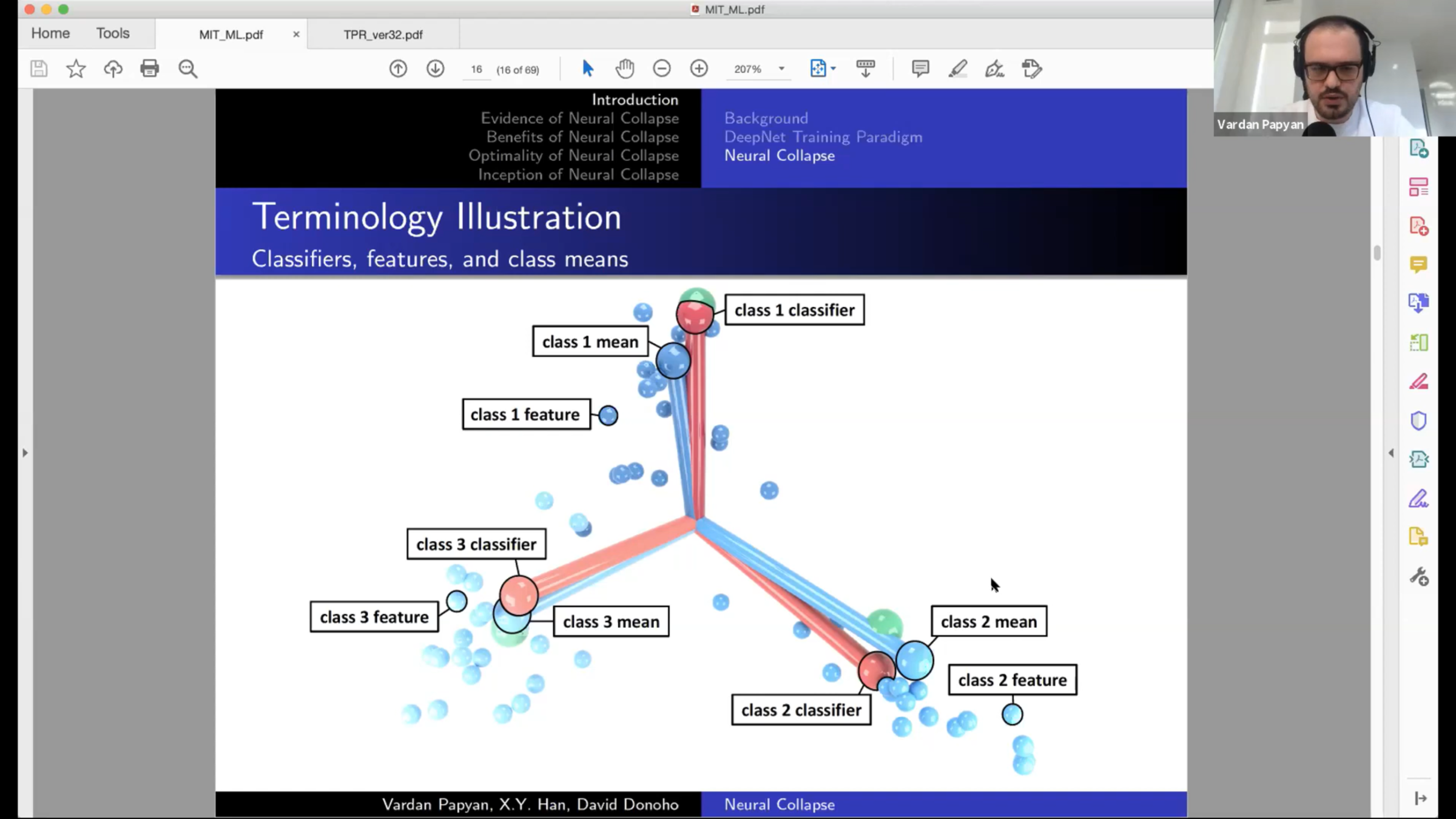
Features
Classifier weights
Classifier output for class \(c\)
(focus on last layer)
Notice that the features \(h_{i,c}\) and the classifier weights \(w_c\) live in the same space.
That's the space in which we observe Neural Collapse.
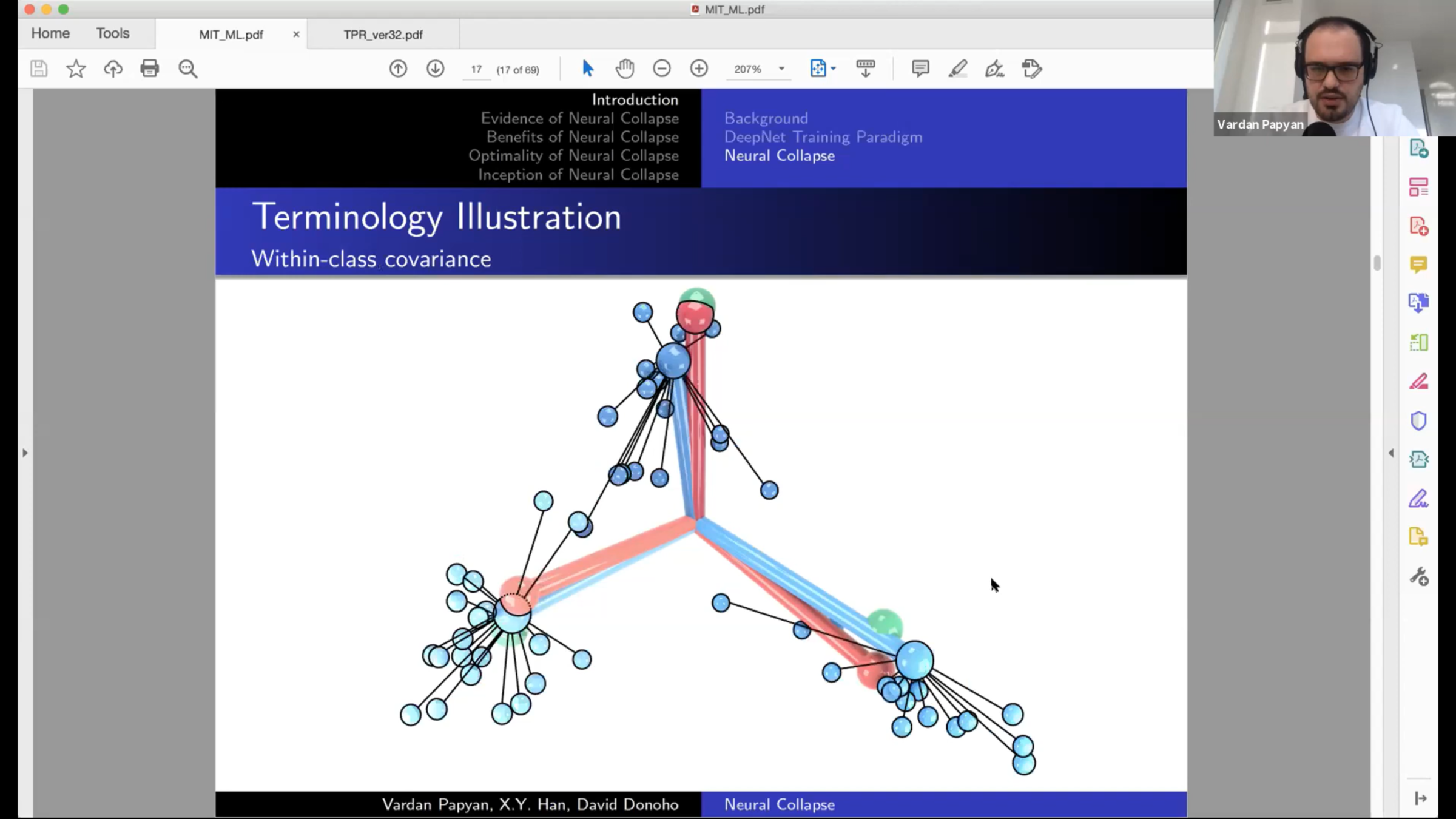
Within-class covariance: \(\quad \Sigma_W = \langle (h_{i,c}-\mu_c)(h_{i,c}-\mu_c)^T \rangle_{i,c}\)
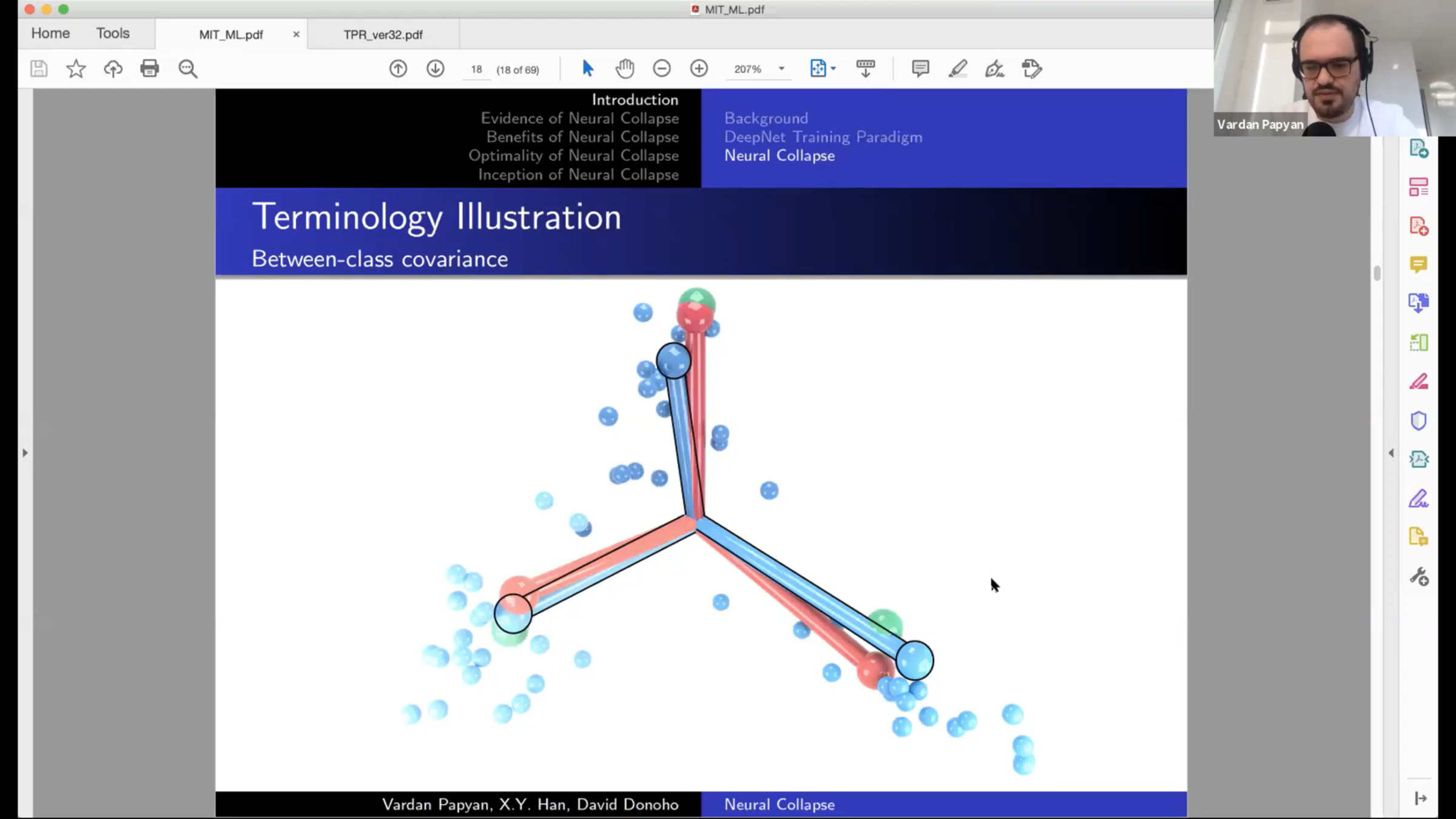
Between-class covariances: \(\quad \Sigma_B = \langle (\mu_c-\mu_G)(\mu_c-\mu_G)^T \rangle_{c}\)
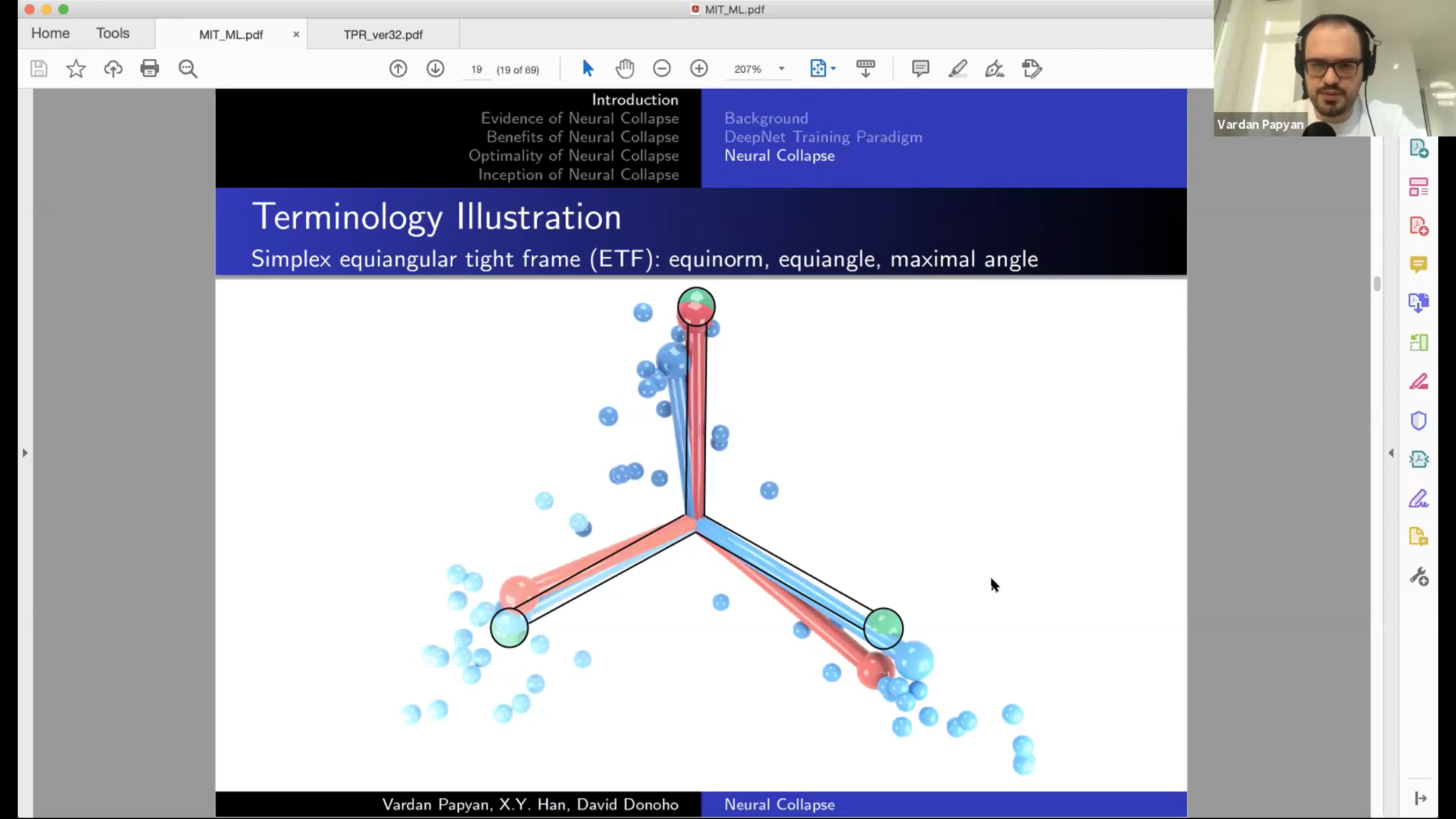
Simplex Equiangular Tight Frame (ETF):
Set of vectors which are
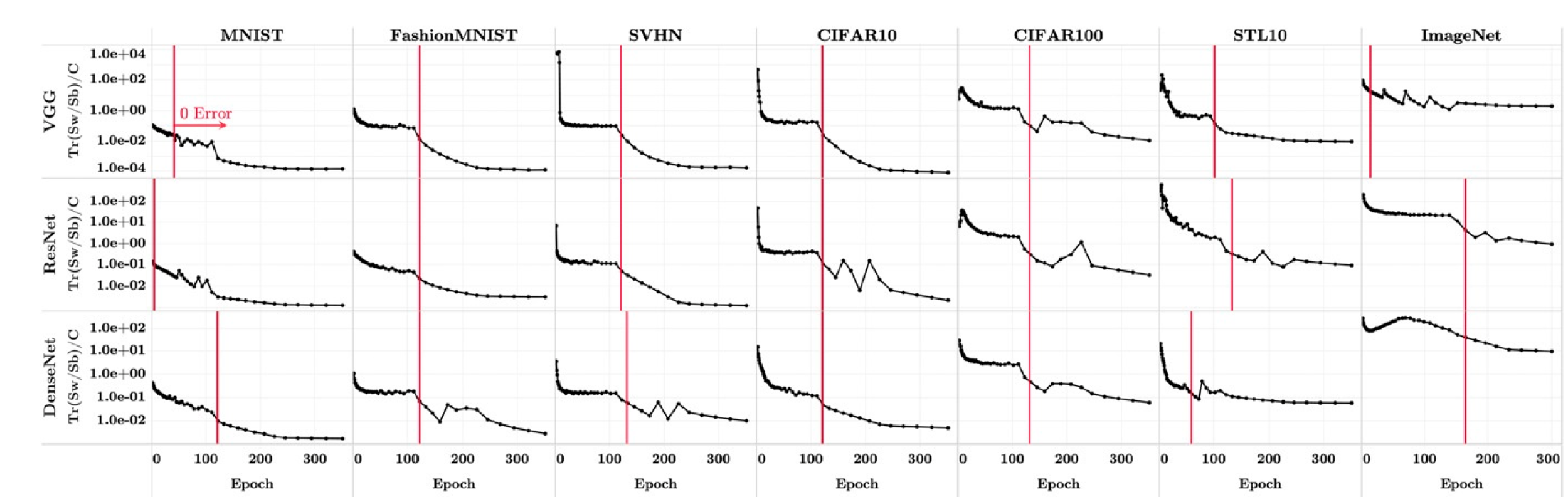
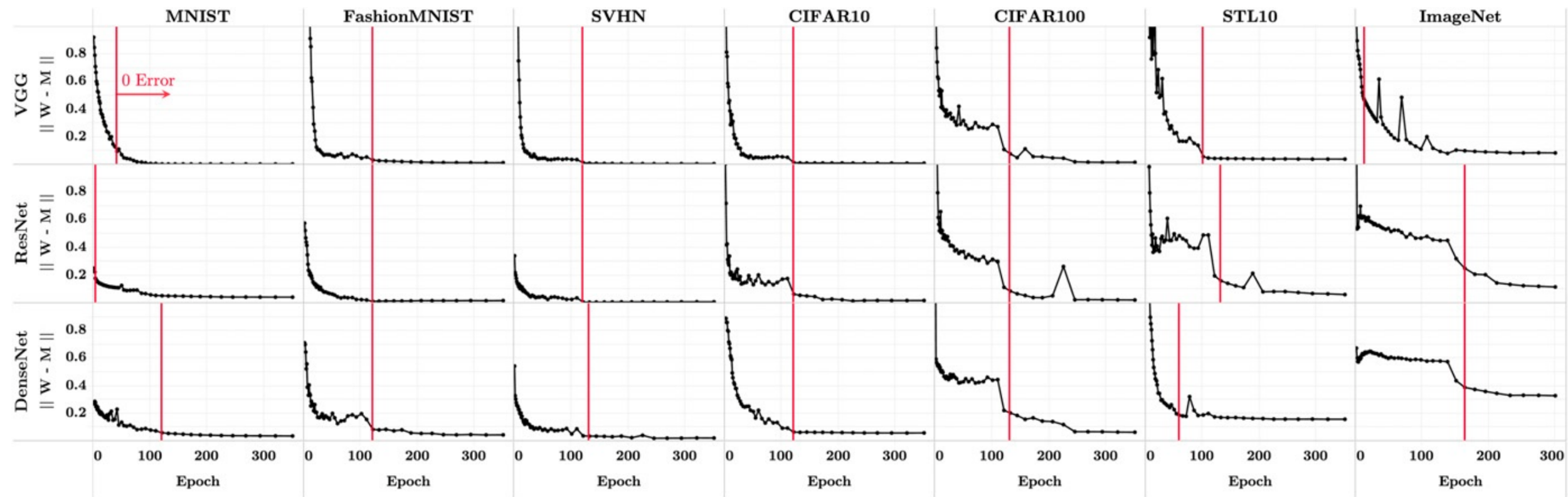
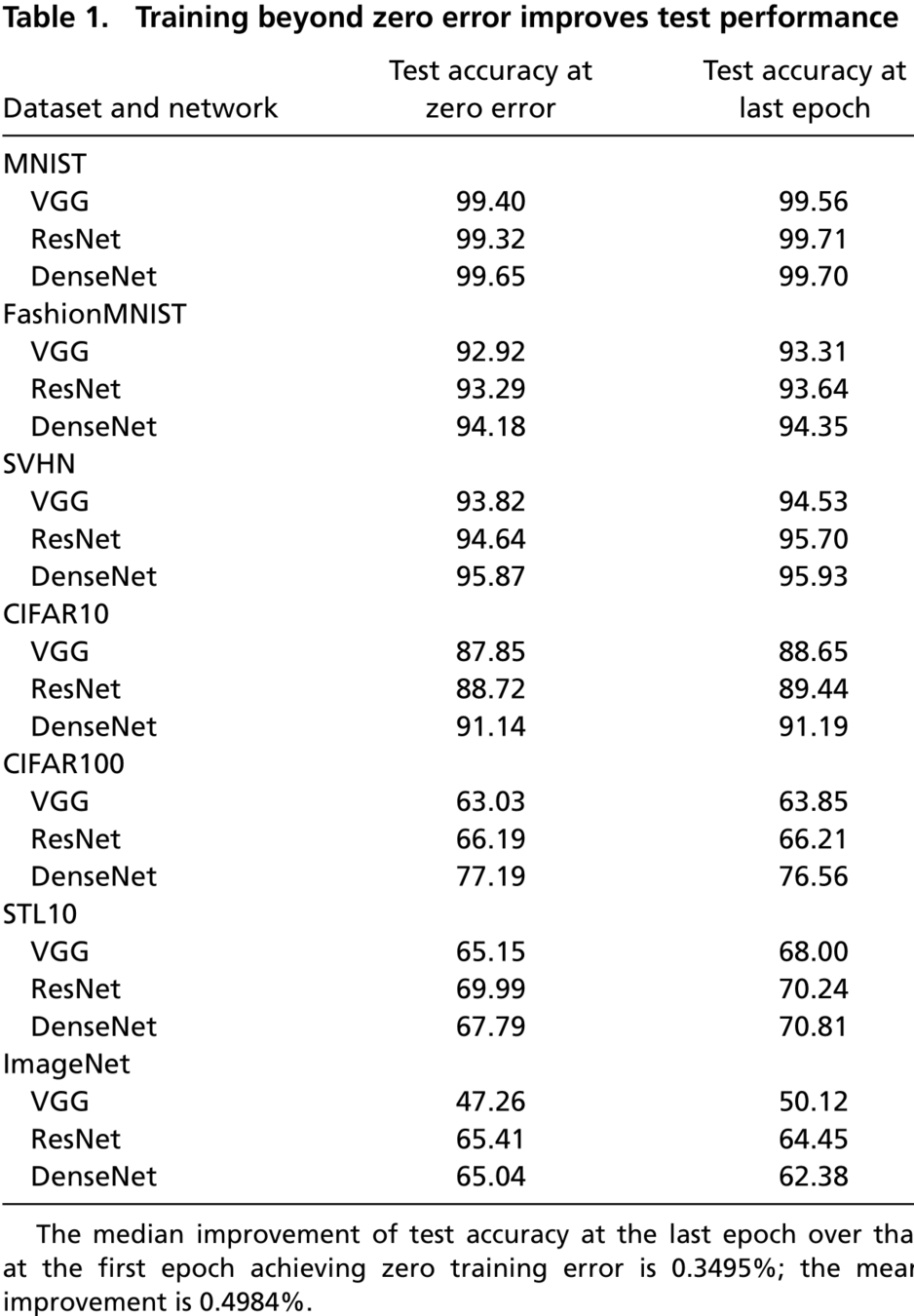
A net trained past \(\epsilon_\text{train} = 0\), while \(\mathcal{L}(\text{train-set}) \to 0\) frequently induces neural collapse (NC).
NC is characterized by:
VGG-13 trained on CIFAR-10
[NC1] Within-class variability collapses
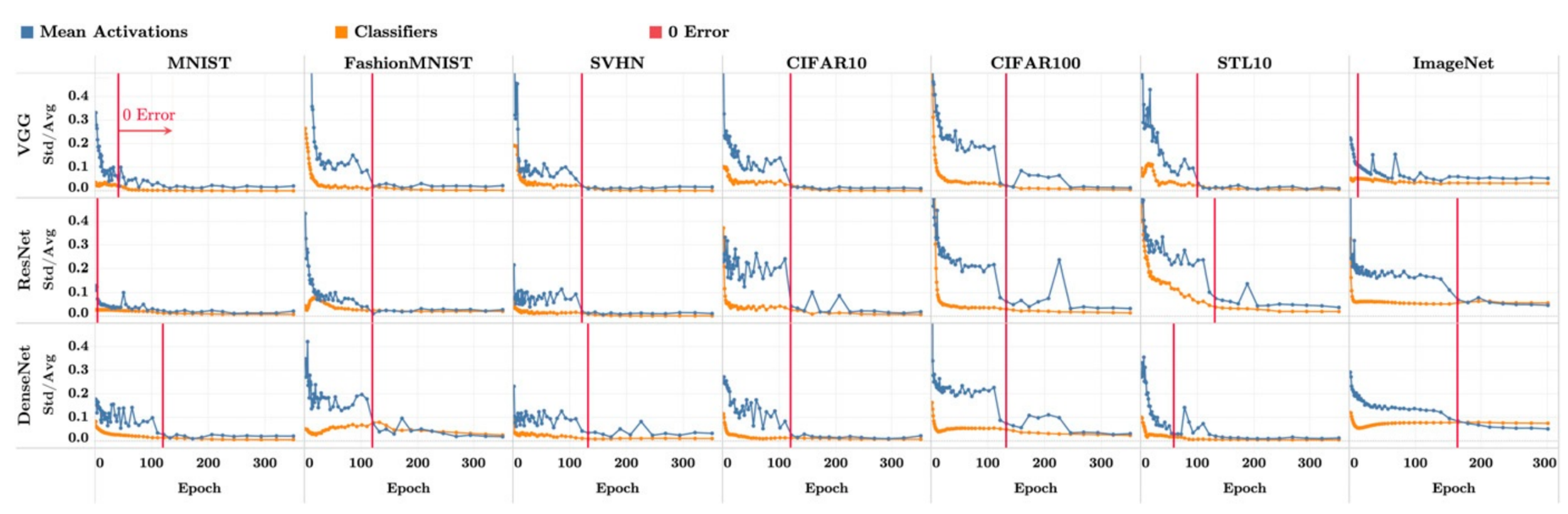
[NC2a] Class means become equinorm
y-axis:
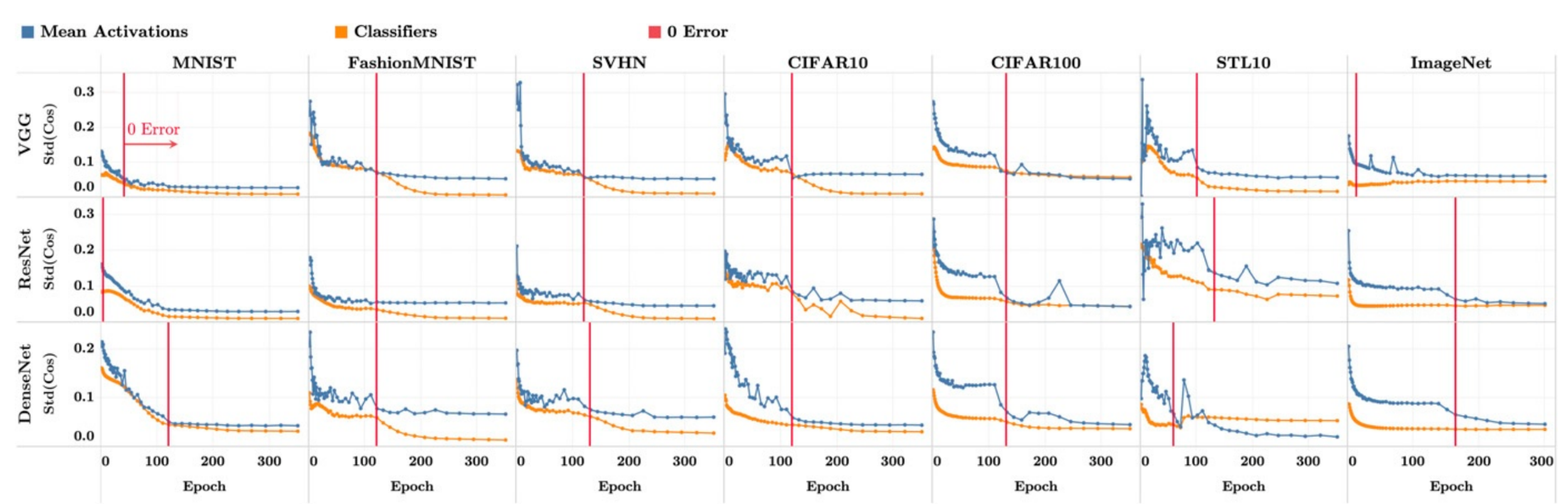
[NC2b] Class means approach equiangularity
y-axis:
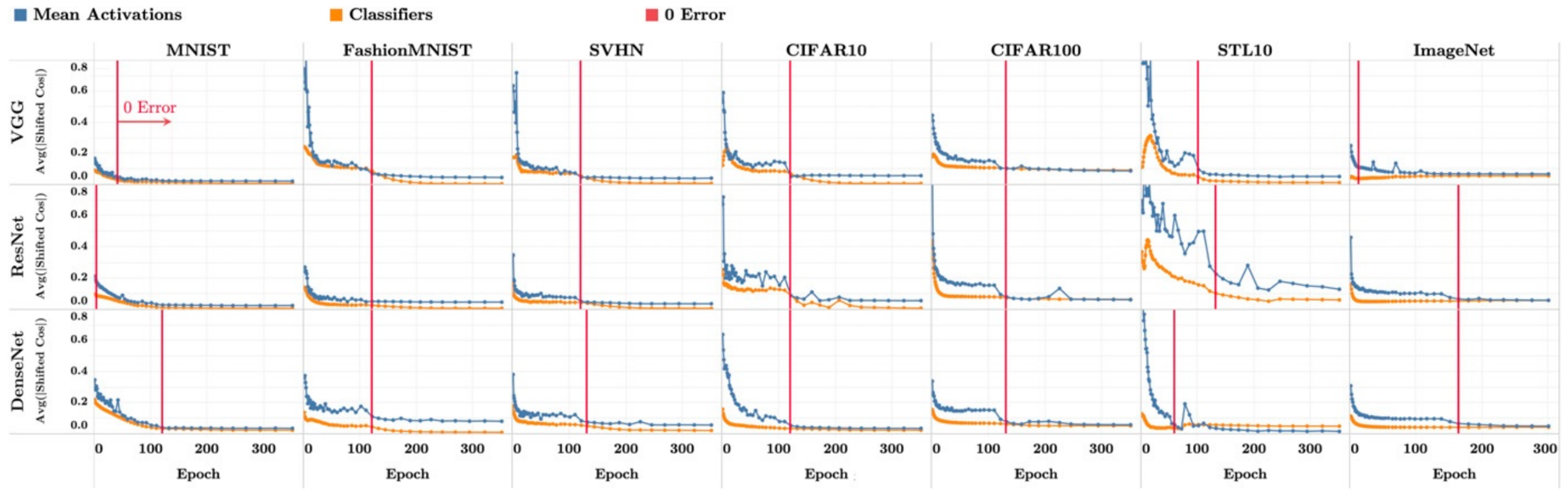
[NC2c] Class means approach maximal angle
y-axis:
[NC3] Self-duality
Class means matrix: \(\mathbf{M} = [\mu_c - \mu_G,\: c \in \{1, \dots, C\}]\)
Classifiers weights matrix \(\mathbf{W}\)
y-axis:
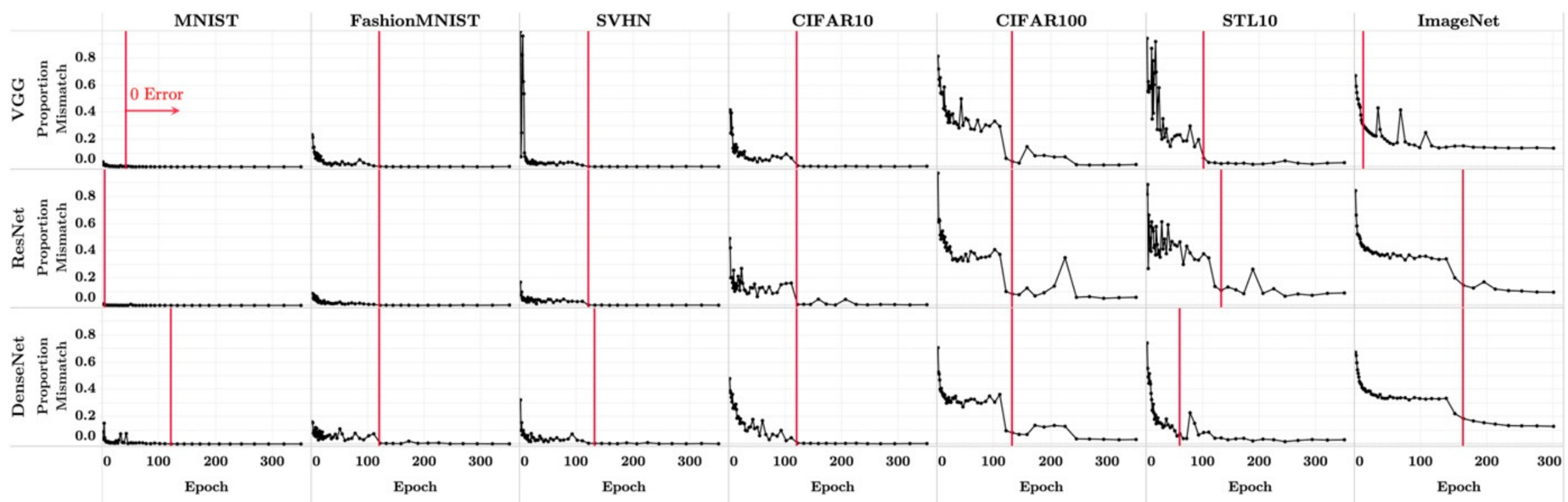
[NC4] Last layer ~ nearest-neighbor classifier w.r.t. class means
Net classifier: \(\argmax_c\langle w_c, h(x)\rangle + b_c\)
Nearest-neighbor classifier: \(\argmin_c ||h(x) - \mu_c||_2\)
y-axis: mismatches between the two classifiers
Optimiality Criterion: large deviation error exponent
$$\beta(\mathbf M, \mathbf w, \mathbf b) = -\lim_{\sigma\to 0} \sigma^2 \log P_\sigma\{\hat \gamma (h) \neq \gamma\}$$
Theorem. Optimal error exponent \(\beta^* = \max_{(\mathbf M, \mathbf w, \mathbf b)}\beta(\mathbf M, \mathbf w, \mathbf b)\) is achieved by the simplex ETF, \(\mathbf M^*\):
$$\beta(\mathbf M^*,\mathbf M^*,0) = \beta^*$$
codewords are transmitted over a noisy channel
linear decoder
Information theory perspective
(norm constraint ~ limit to signal strenght)
design decoder and codebook for optimal retrieval
[NC1]
[Shannon, 1959]
Simplex ETF emerges as the optimal structure in the presence of [NC1] and Gaussian noise
slides from Papyan talk @ MIT 9.520/6.860: Statistical Learning Theory and Applications Fall 2020
slides from Papyan talk @ MIT 9.520/6.860: Statistical Learning Theory and Applications Fall 2020
The margin is the same for each point in the dataset and it is as large as it can possibly be.
By Leonardo Petrini




