






Leonardo Petrini
PhD Student @ Physics of Complex Systems Lab, EPFL Lausanne
Leonardo Petrini, Alessandro Favero, Mario Geiger, Matthieu Wyart
Theory of Neural Nets, Internal Seminar July 12, 2021
vs.
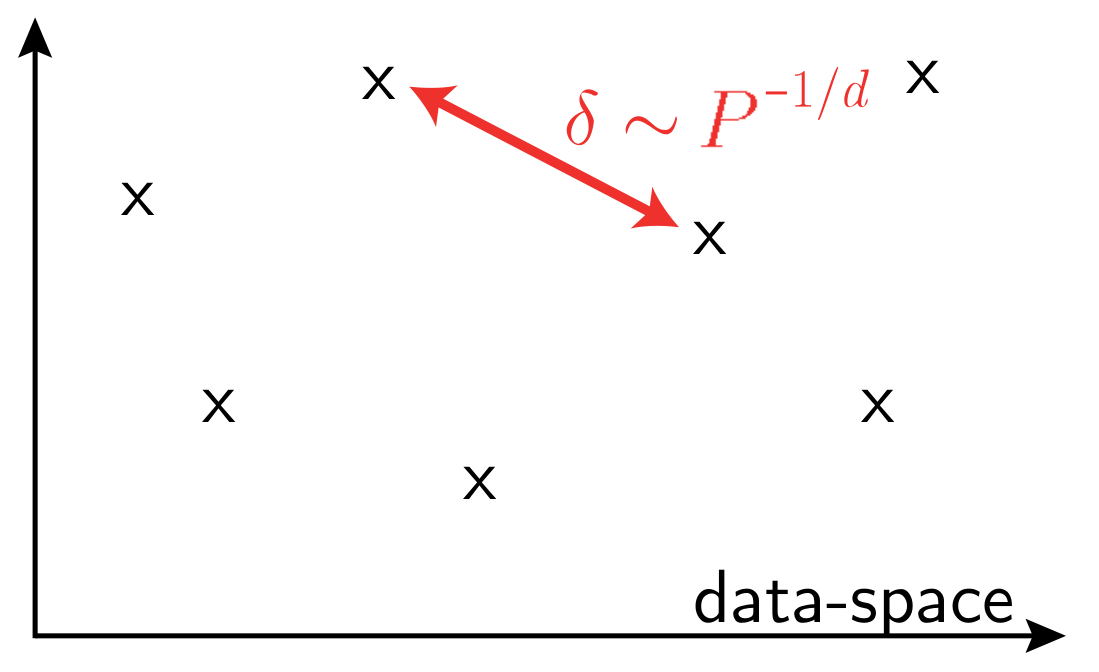
Learning in high-d implies that data is highly structured
\(P\): training set size
\(d\) data-space dimension
cats
dogs
embedding space: 3D
data manifold: 2D
task: 1D
Common idea: nets can exploit data structure by getting
invariant to some aspects of the data.
Observables:
Which invariances are learnt by neural nets?
not explaining:
Shwartz-Ziv and Tishby (2017); Saxe et al. (2019)
Ansuini et al. (2019), Recanatesi et al. (2019)
Kopitkov and Indelman (2020); Oymak et al. (2019);
Paccolat et al. (2020)
Bach (2017);
Chizat and Bach (2020); Ghorbani et al. (2019, 2020); Paccolat et al. (2020);
Refinetti et al. (2021);
Yehudai and Shamir (2019)...
Which data invariances are CNNs learning?
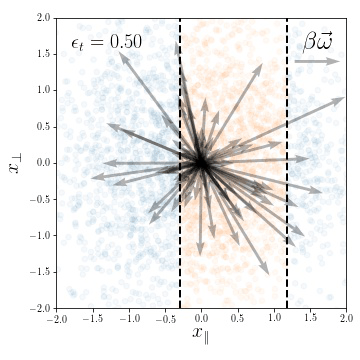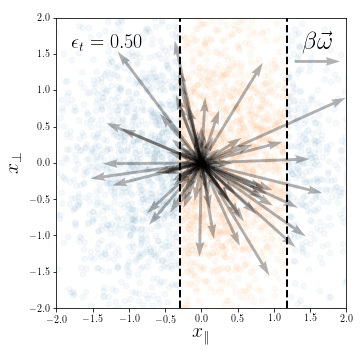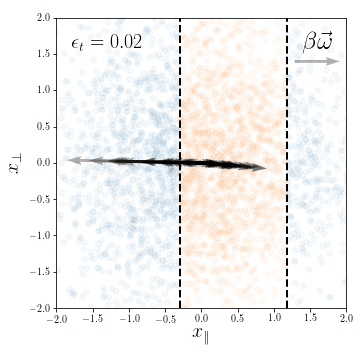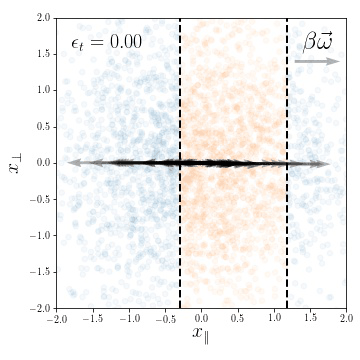
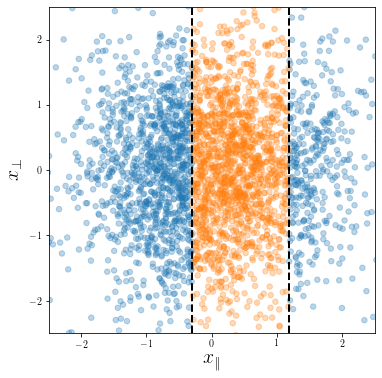
Dataset presenting a linear invariant subspace:
\(\vec x^\mu \sim \mathcal{N}(0, I_d)\), for \(\mu=1,\dots,P\)
Classification task:
\(y(\vec x) = y( x_\parallel) \in \{-1, 1\}\)
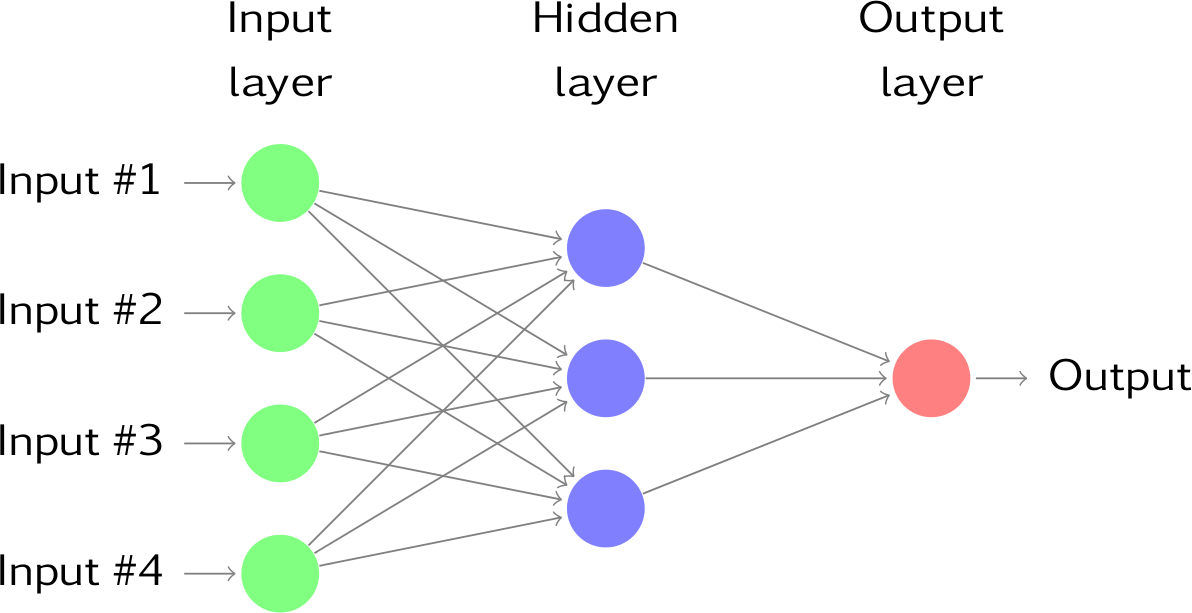
Fully connected network:
Weights evolution during training:
Fully connected network:
Fully connected nets are able to exploit linear invariances.
Hypothesis: images can be classified because the task is invariant to smooth deformations of small magnitude and CNNs exploit such invariance with training.
Bruna and Mallat (2013) Mallat (2016)
...
Is it true or not?
Can we test it?
"Hypothesis" means, informally:
\(\|f(x) - f(\tau x)\|^2\) is small if the \(\| \nabla \tau\|\) is small.
\(f\) : network function
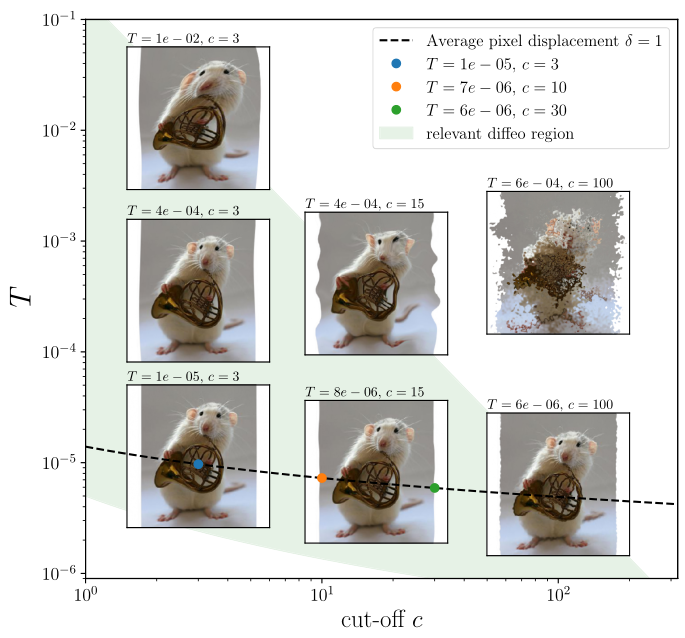
The deformation amplitude is measured by $$\| \nabla \tau\|^2=\int_{[0,1]^2}( (\nabla \tau_u)^2 + (\nabla \tau_v)^2 )dudv$$
notation:
\(x(s)\) input image intensity
\(s = (u, v)\in [0, 1]^2\) (continuous) pixel position
\(\tau\) smooth deformation
\(\tau x\) image deformed by \(\tau\)
such that \([\tau x](s)=x(s-\tau(s))\)
\(\tau(s) = (\tau_u(s),\tau_v(s))\) is a vector field
Previous empirical works show that small shifts of the input can significantly change the net output.
Issues:
Azulay and Weiss (2018); Dieleman et al. (2016); Zhang (2019) ...
notation:
\(x(s)\) input image intensity
\(s = (u, v)\in [0, 1]^2\) (continuous) pixel position
\(\tau\) smooth deformation
\(\tau x\) image deformed by \(\tau\)
such that \([\tau x](s)=x(s-\tau(s))\)
\(\tau(s) = (\tau_u(s),\tau_v(s))\) is a vector field
The deformation amplitude is measured by $$\| \nabla \tau\|^2=\int_{[0,1]^2}( (\nabla \tau_u)^2 + (\nabla \tau_v)^2 )dudv$$
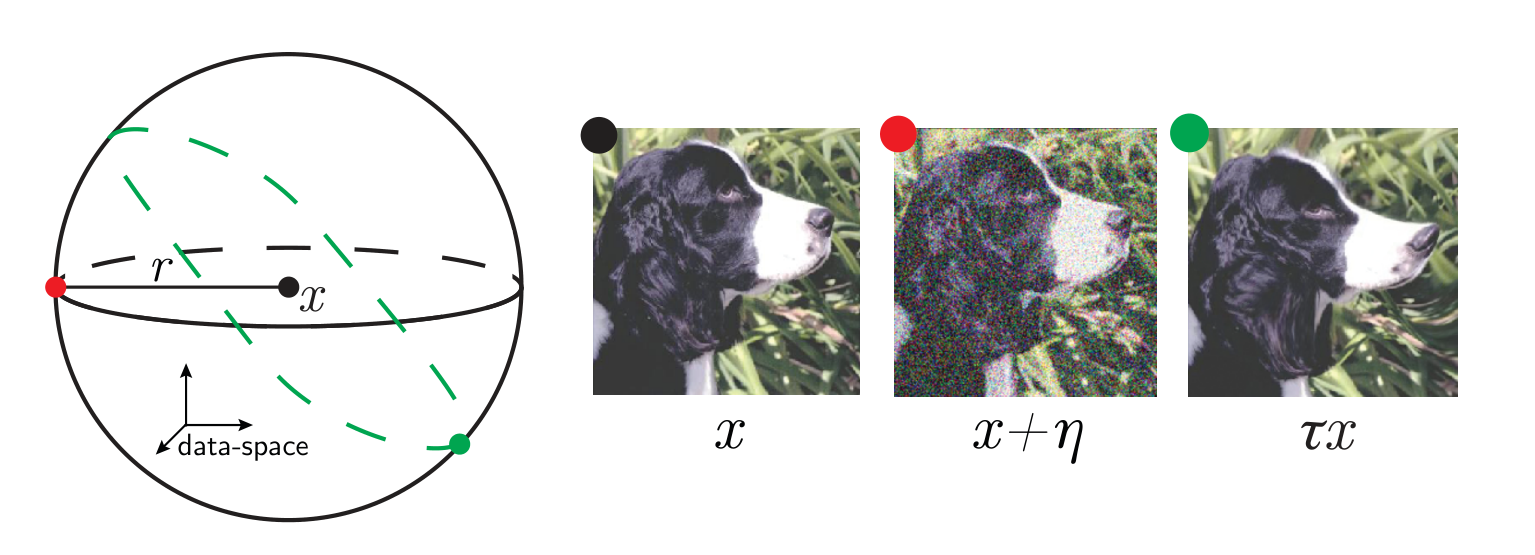
\(x\) input image
\(\tau\) smooth deformation
\(\eta\) isotropic noise with \(\|\eta\| = \langle\|\tau x - x\|\rangle\)
\(f\) network function
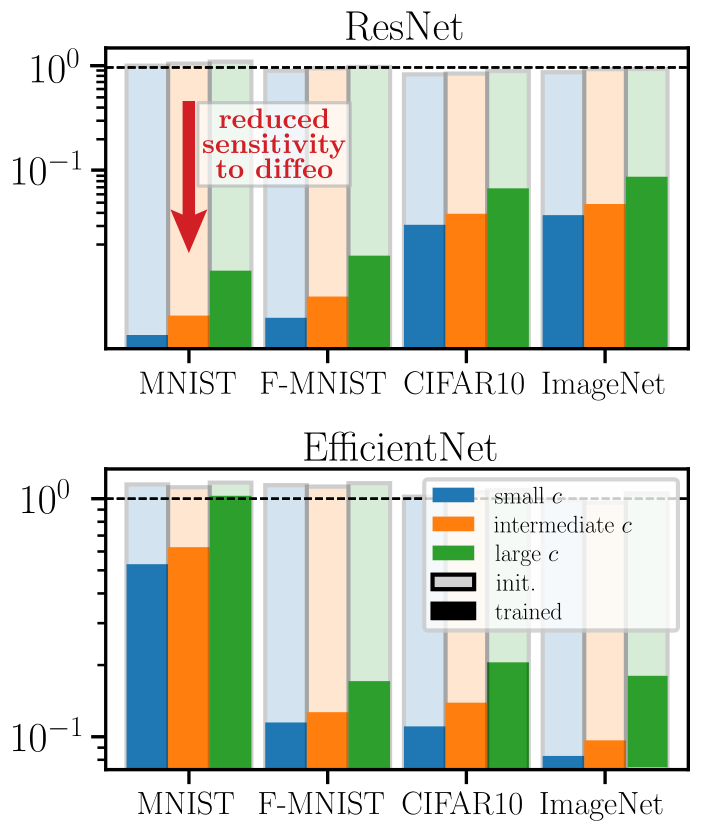
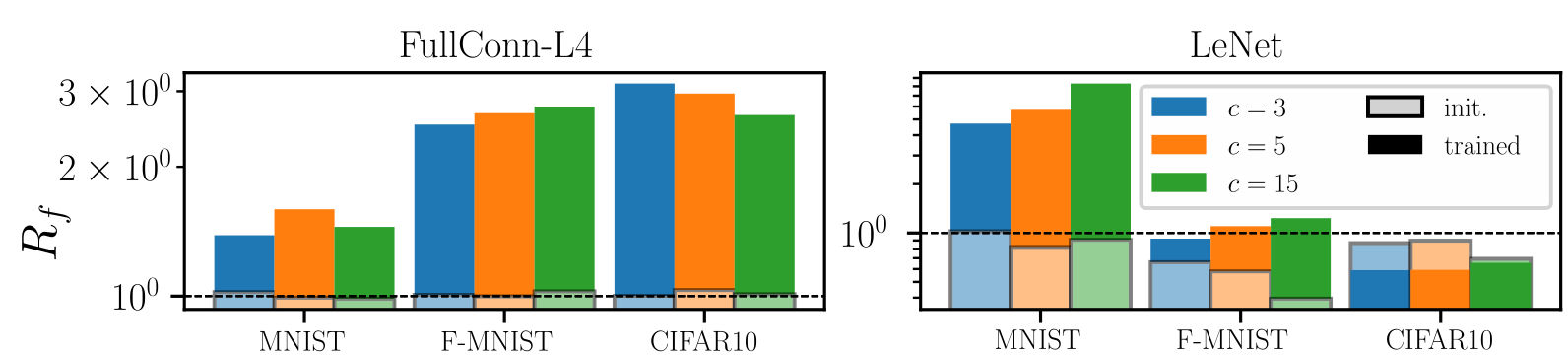
Goal: quantify how a deep net learns to become less sensitive
to diffeomorphisms than to generic data transformations
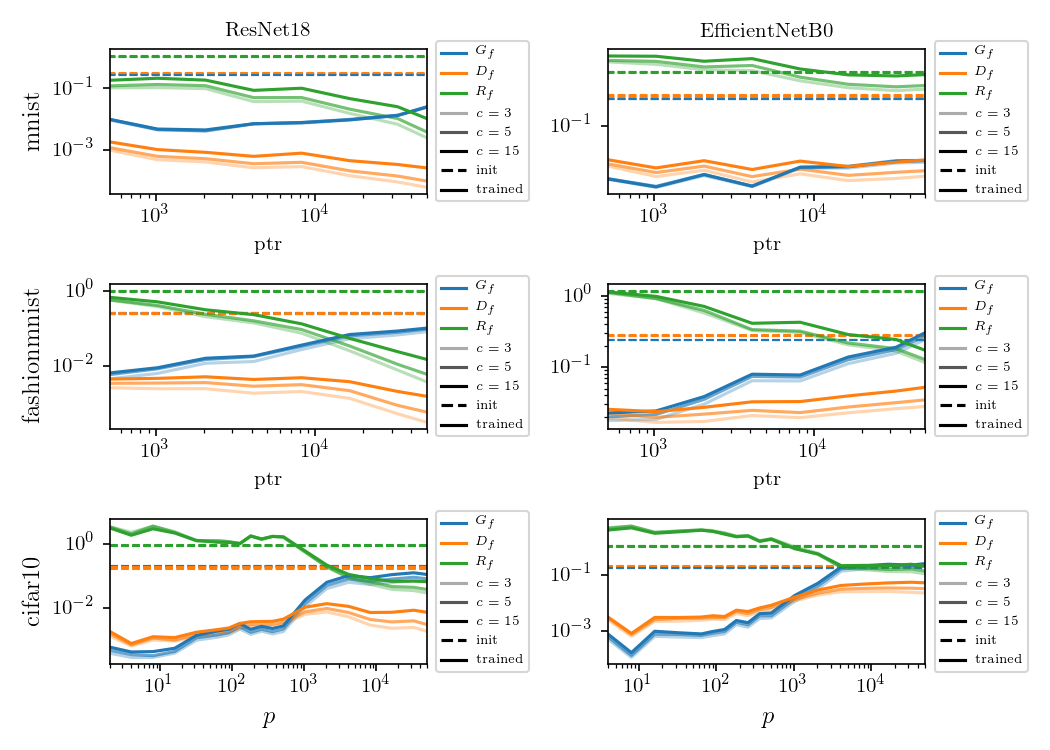
$$R_f = \frac{\langle \|f(\tau x) - f(x)\|^2\rangle_{x, \tau}}{\langle \|f(x + \eta) - f(x)\|^2\rangle_{x, \eta}}$$
Relative stability:
$$R_f = \frac{\langle \|f(\tau x) - f(x)\|^2\rangle_{x, \tau}}{\langle \|f(x + \eta) - f(x)\|^2\rangle_{x, \eta}}$$
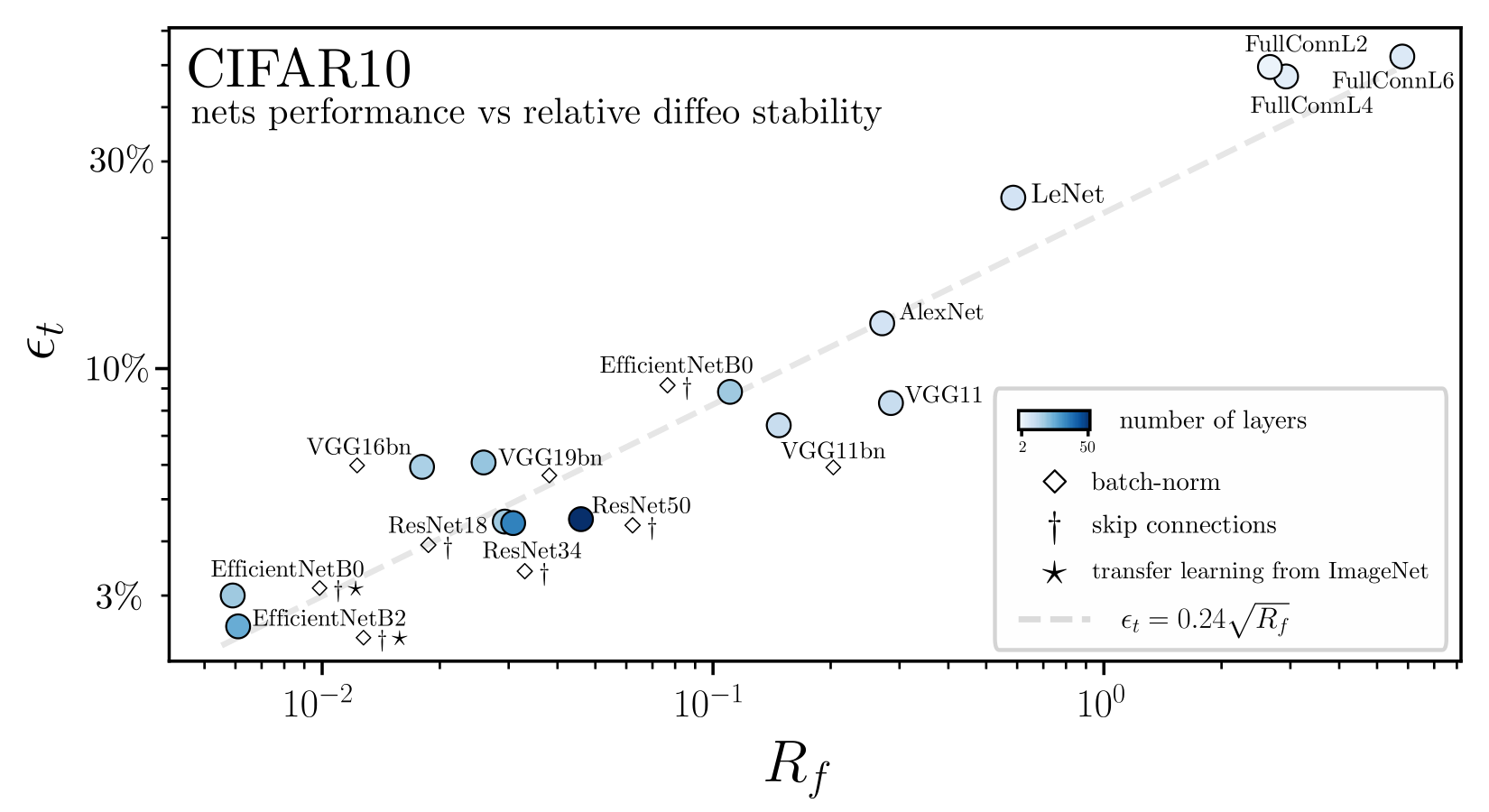
Results:
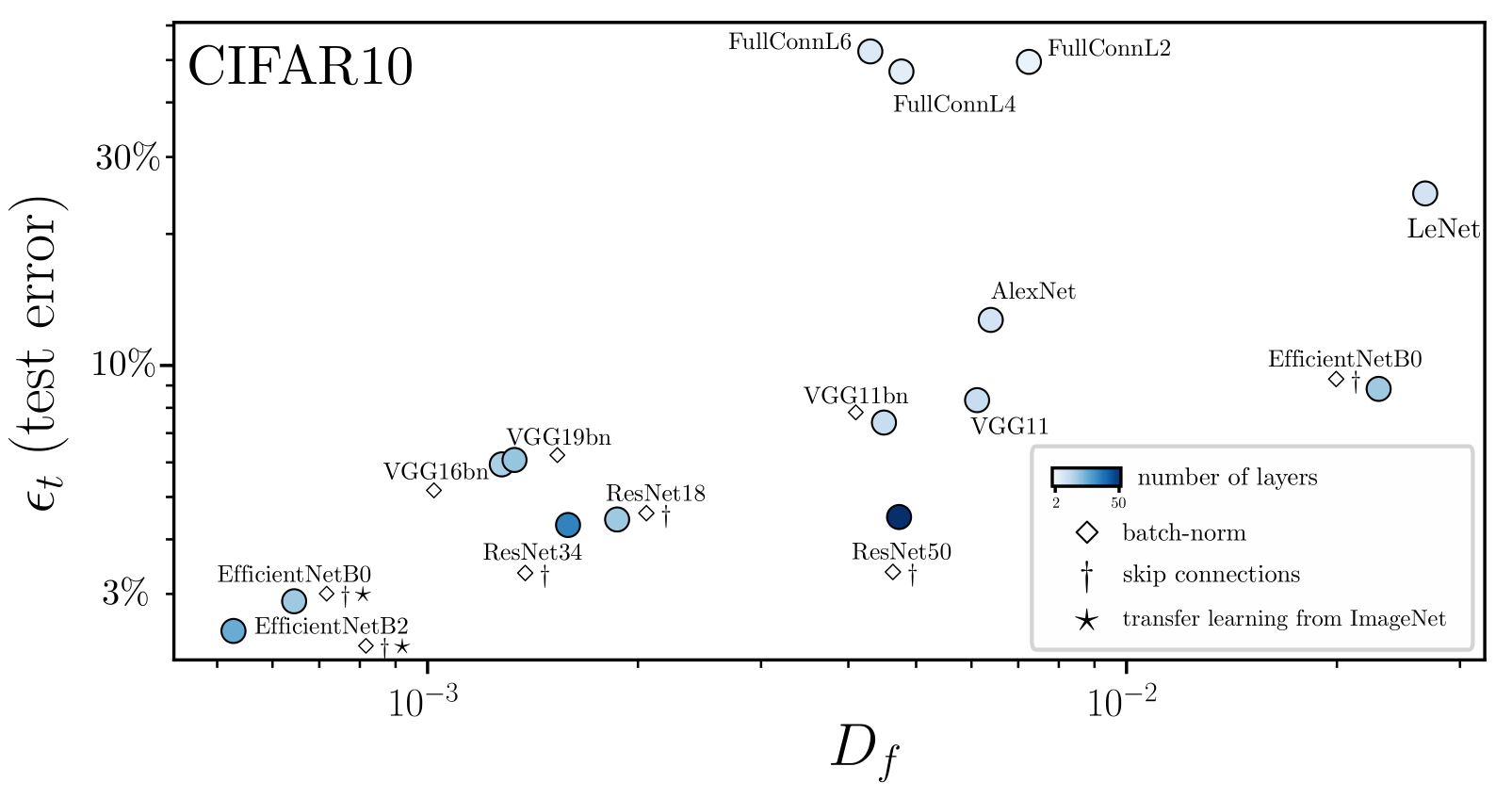
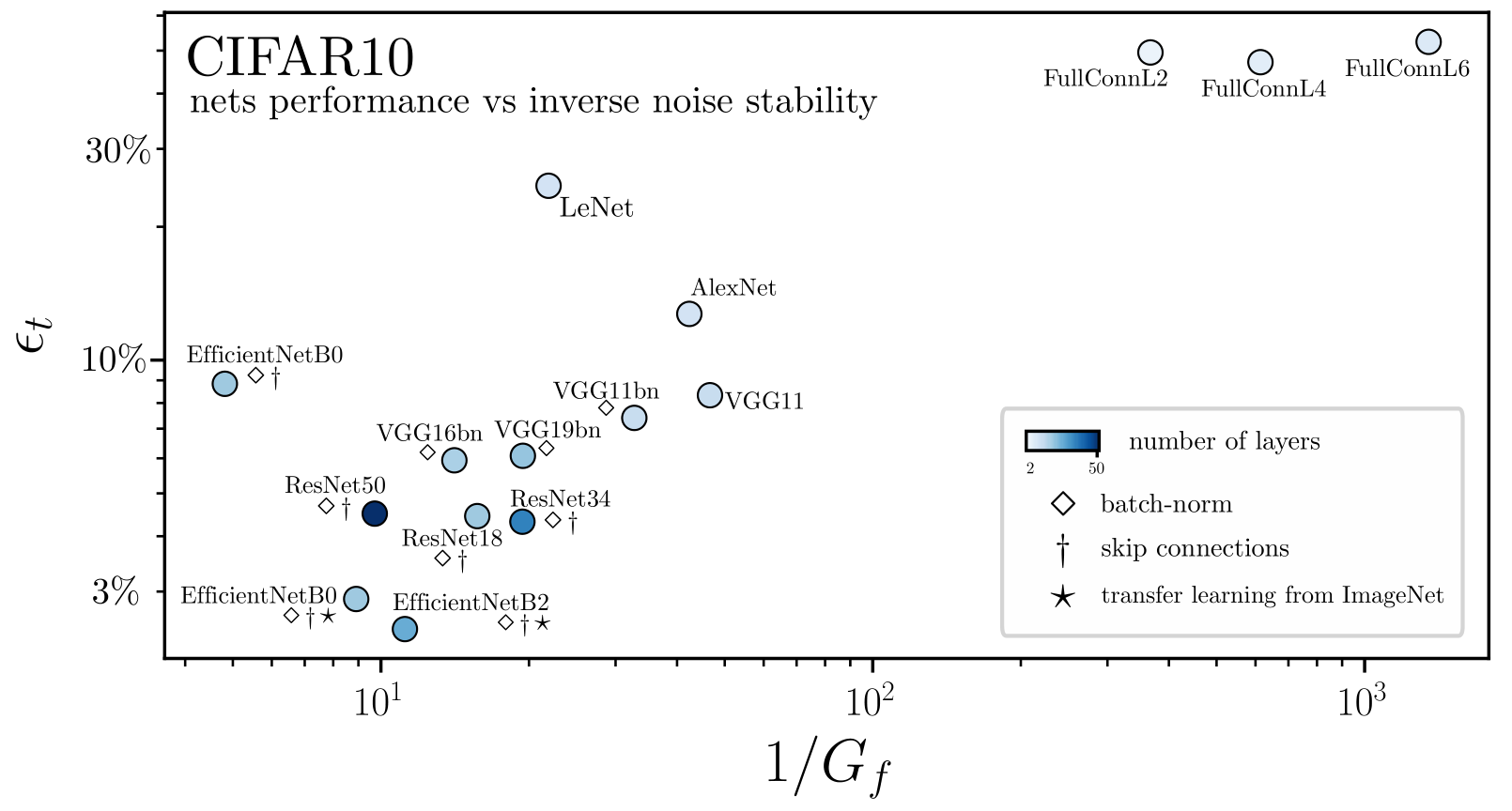
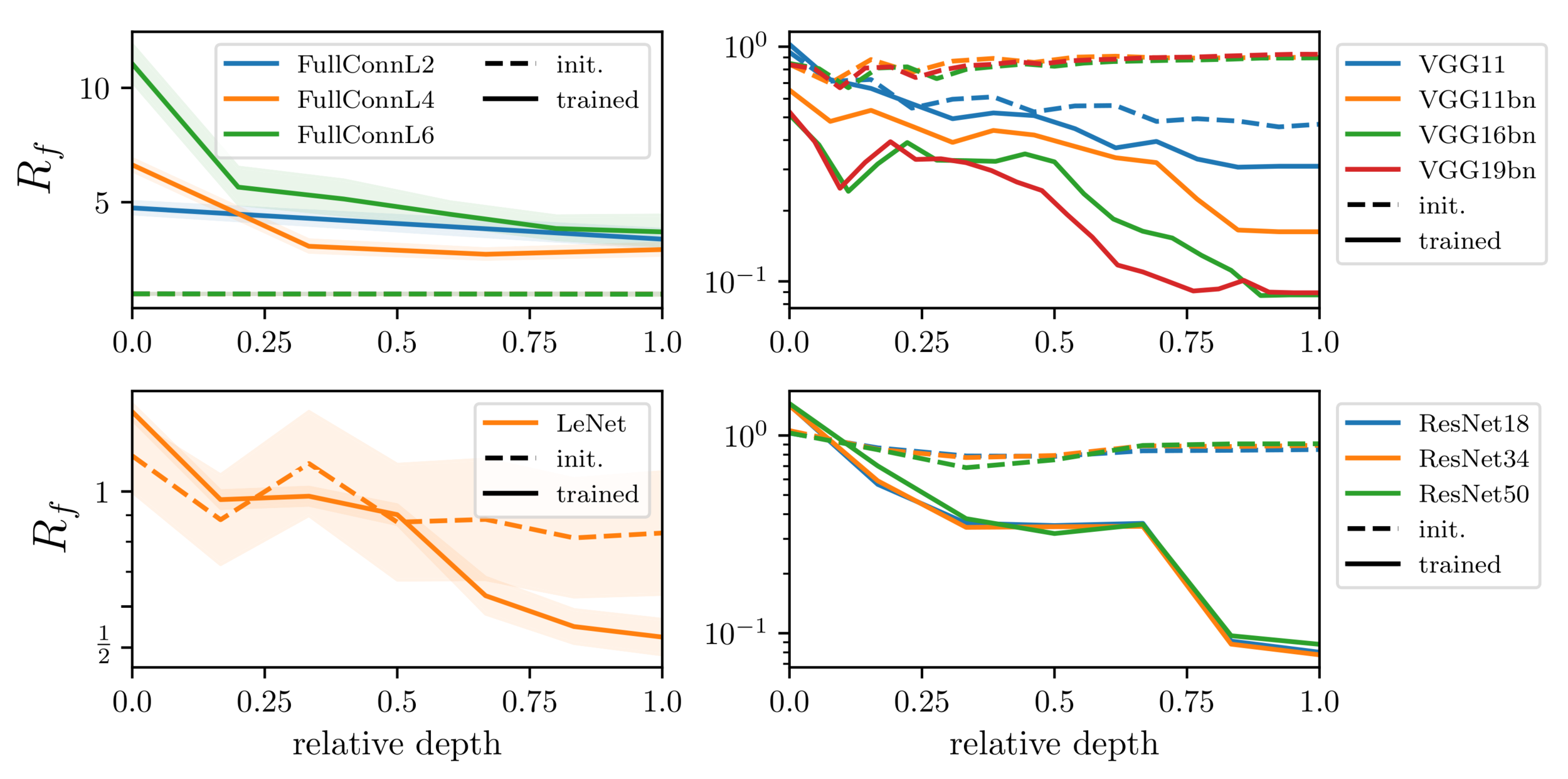
Deep nets learn to become stable to diffeomosphisms!
Relative stability can be rewritten as
diffeo stability
additive noise stability
\(P\) : train set size
Stability \(D_f\) is not the good observable to characterize how deep nets learn diffeo invariance
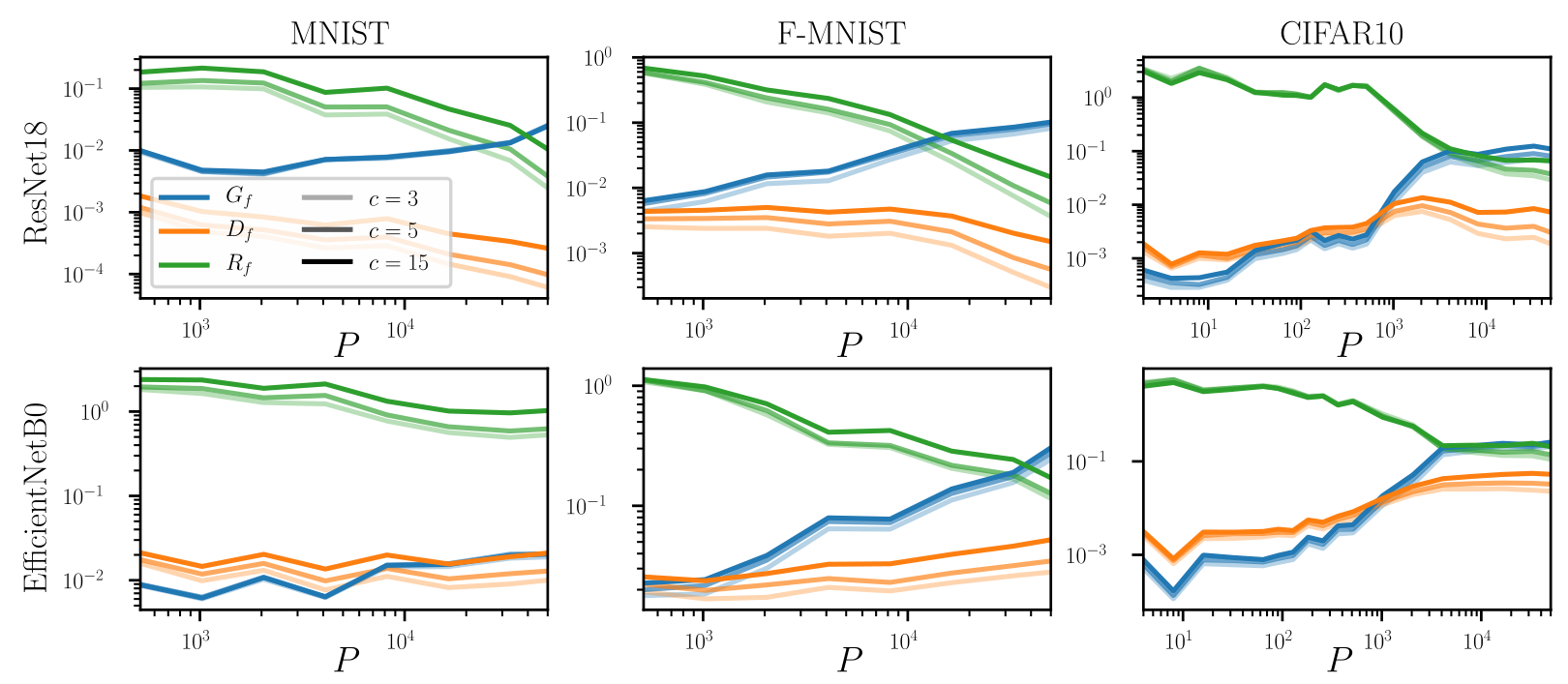
As a function of the train set size \(P\):
stability in depth:
Thanks!
By Leonardo Petrini
Teory of Neural Nets, internal seminar - July 12, 2021




