




Leonardo Petrini
PhD Student @ Physics of Complex Systems Lab, EPFL Lausanne
Leonardo Petrini, Alessandro Favero, Mario Geiger, Matthieu Wyart
vs.
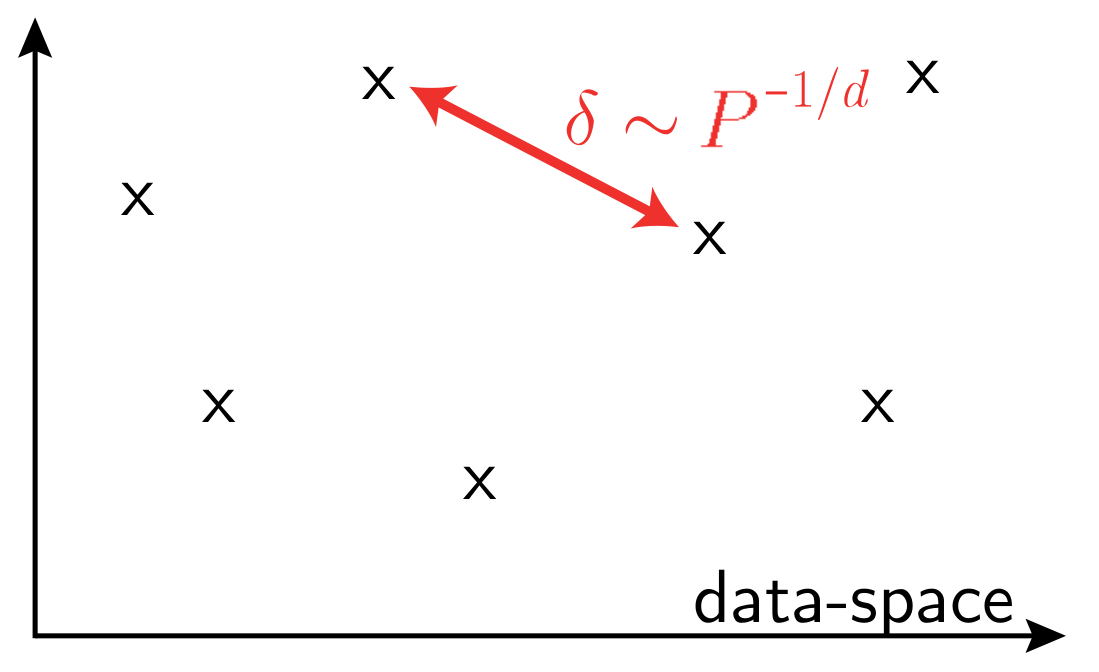
\(P\): training set size
\(d\) data-space dimension
What is the structure of real data?
Cat
Bruna and Mallat (2013), Mallat (2016), ...
\(S = \frac{\|f(x) - f(\tau x)\|}{\|\nabla\tau\|}\)
\(f\) : network function
Is it true or not?
Can we test it?
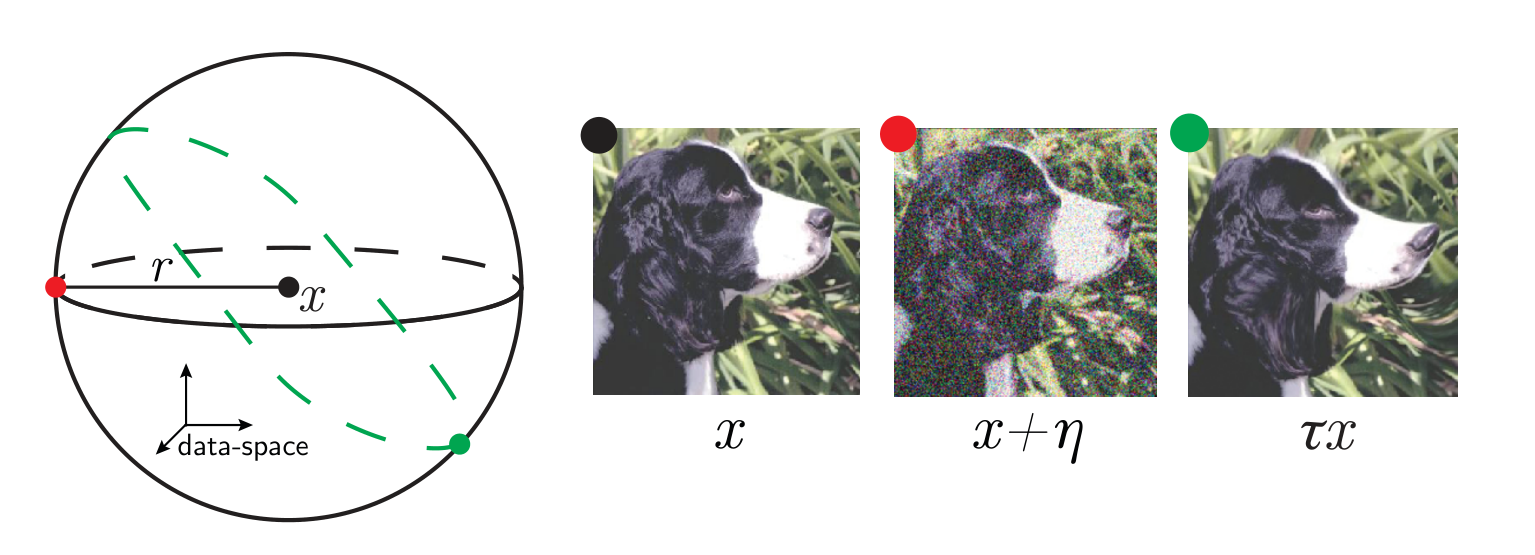
\(x-\)translations
\(y-\)translations
\(x\) input image
\(\tau\) smooth deformation
\(\eta\) isotropic noise with \(\|\eta\| = \langle\|\tau x - x\|\rangle\)
\(f\) network function
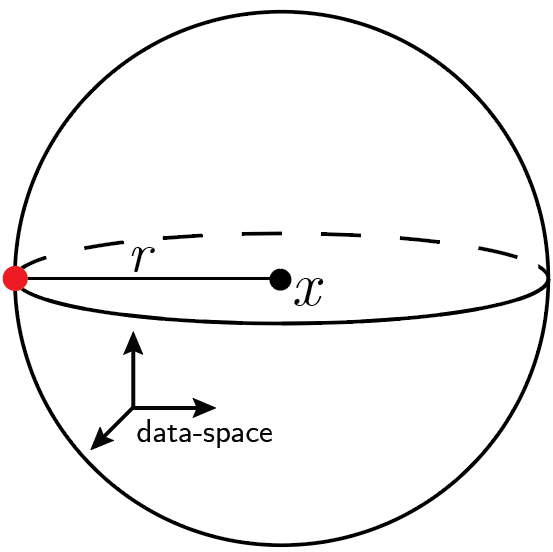
Observable that quantifies if a deep net is less sensitive to diffeomorphisms than to generic data transformations
$$R_f = \frac{\langle \|f(x) - f(\tau x)\|^2\rangle_{x, \tau}}{\langle \|f(x) - f(x + \eta)\|^2\rangle_{x, \eta}}$$
Relative stability:
$$R_f = \frac{\langle \|f(\tau x) - f(x)\|^2\rangle_{x, \tau}}{\langle \|f(x + \eta) - f(x)\|^2\rangle_{x, \eta}}$$
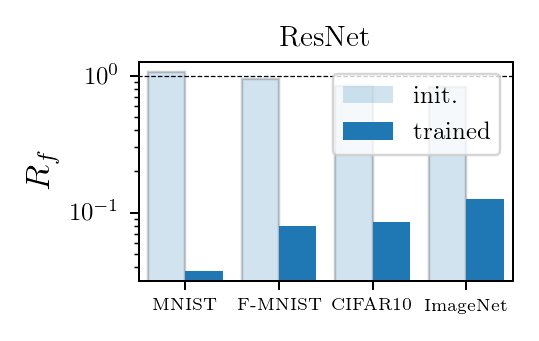
Results:
Deep nets learn to become stable to diffeomosphisms!
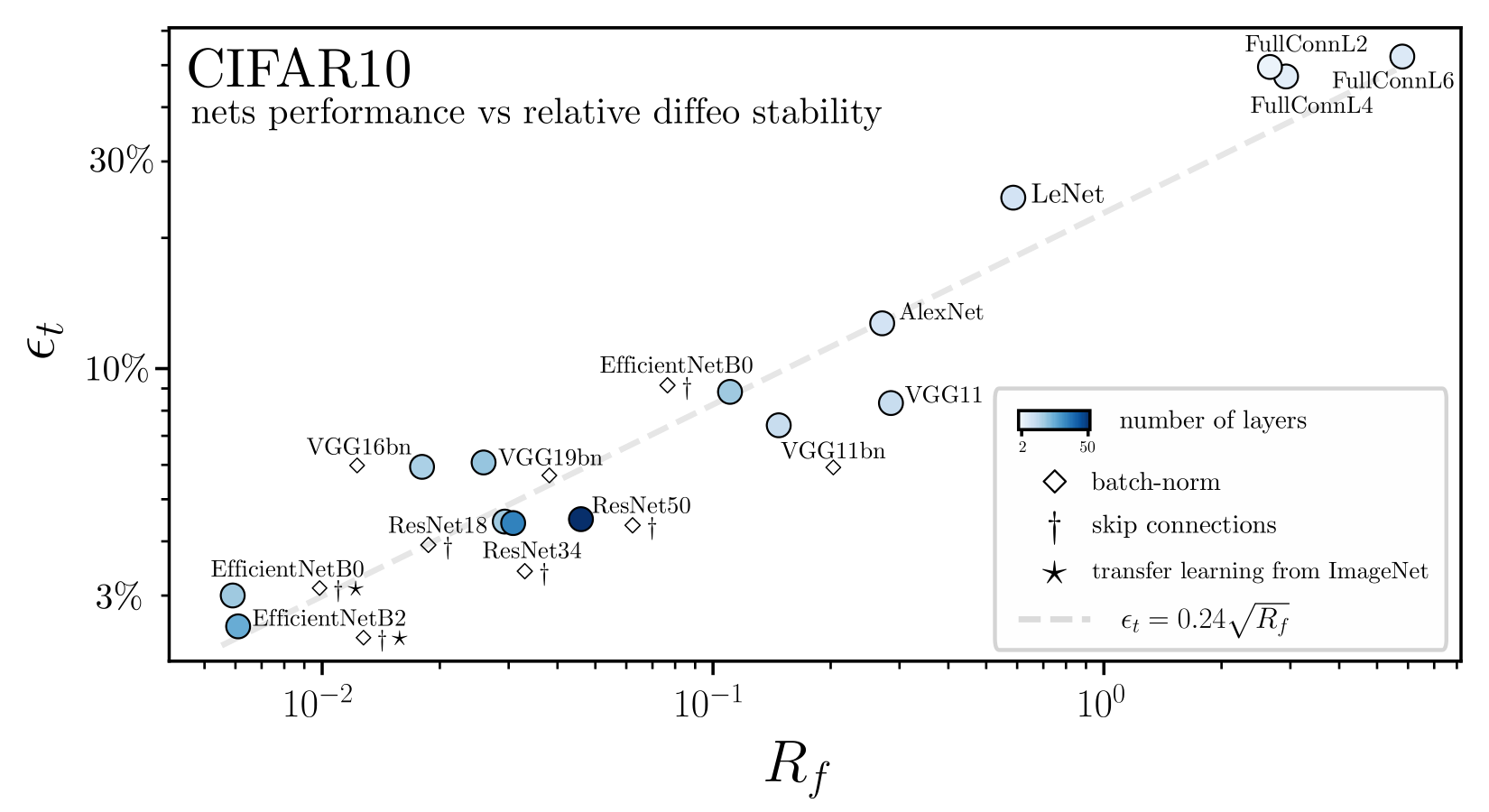
Relation with performance?
1. How to rationalize this behavior?
2. How do CNNs build diffeo stability and perform well?
Thanks!
By Leonardo Petrini
TOPML Workshop




