








russtedrake PRO
Roboticist at MIT and TRI
a prelude to RL and Control
MIT 6.4210/2:
Robotic Manipulation
Fall 2022, Lecture 17
Follow live at https://slides.com/d/KfJ018c/live
(or later at https://slides.com/russtedrake/fall22-lec17)
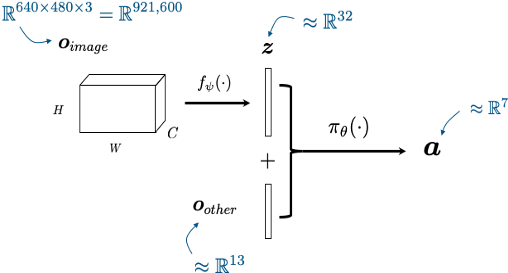
policy needs to know
state of the robot x state of the environment
http://www.ai.mit.edu/projects/leglab/robots/robots.html
System
State-space
Auto-regressive (eg. ARMAX)
input
output
state
noise/disturbances
parameters
2017
Levine*, Finn*, Darrel, Abbeel, JMLR 2016
from hand-coded policies in sim
and teleop on the real robot
Standard "behavior-cloning" objective + data augmentation
"push box"
"flip box"
Policy is a small LSTM network (~100 LSTMs)
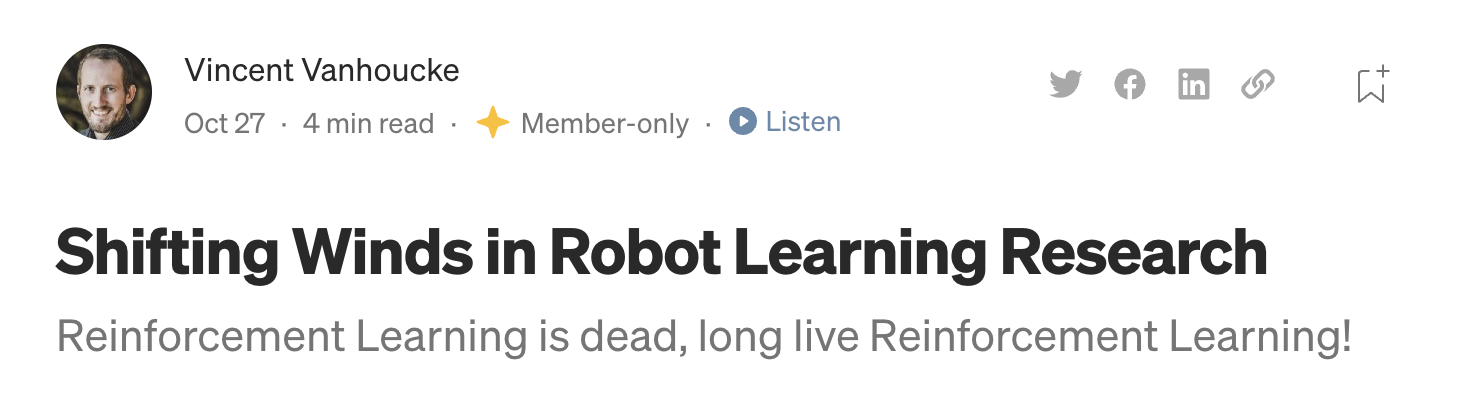
"And then … BC methods started to get good. Really good. So good that our best manipulation system today mostly uses BC, with a sprinkle of Q learning on top to perform high-level action selection. Today, less than 20% of our research investments is on RL, and the research runway for BC-based methods feels more robust."
Andy Zeng's MIT CSL Seminar, April 4, 2022
Andy's slides.com presentation
By russtedrake
MIT Robotic Manipulation Fall 2020 http://manipulation.csail.mit.edu


