









海之音
INFOR 36th 學術長 @小海_夢想特急_夢城前
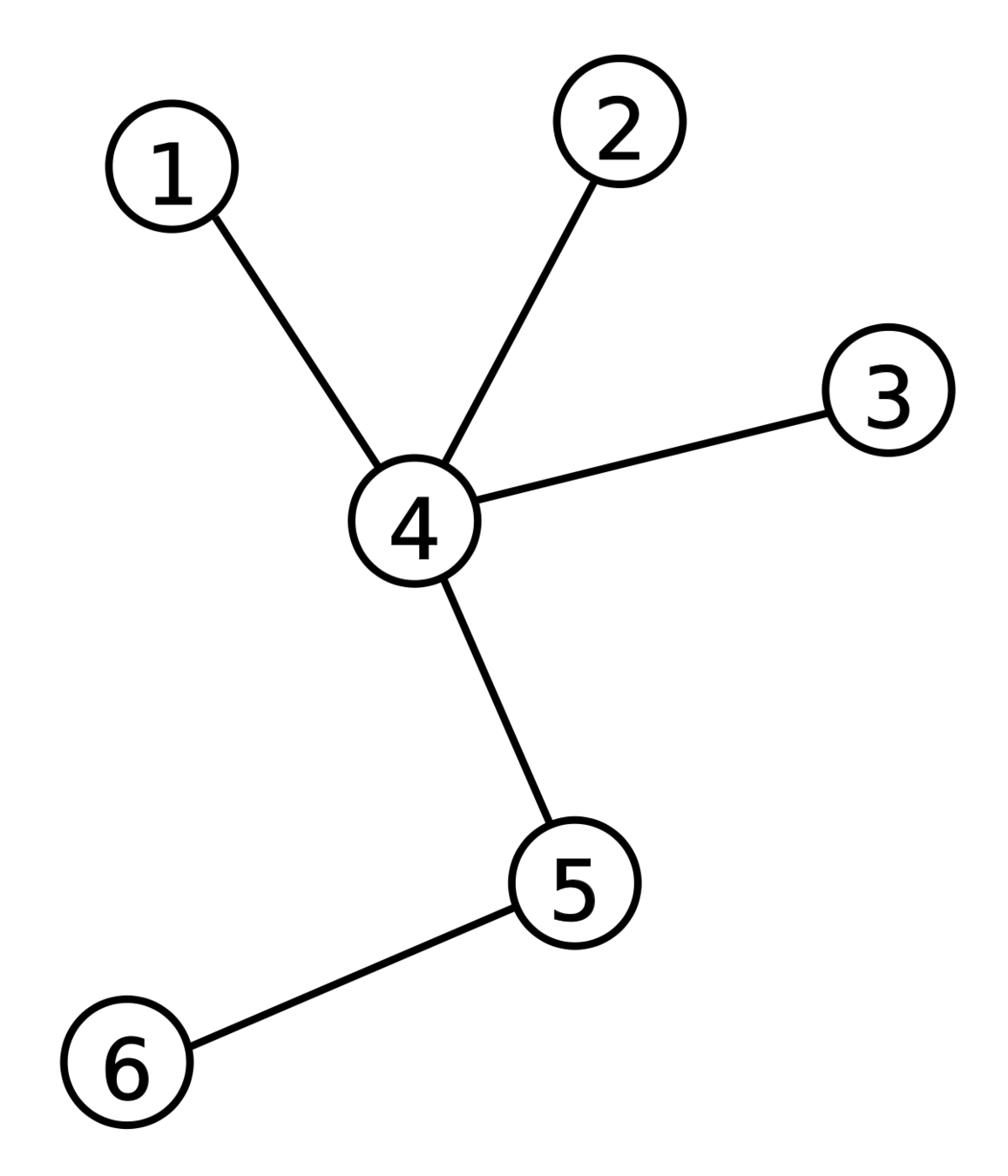
圖論。
INFOR 36th. @小海_夢想特急_夢城前
Glossary.
如果你不知道這是啥,這是教育部的解釋
A graph is a structure amounting to a set of objects in which some pairs of the objects are in some sense "related".
「一張圖是一種結構,描述了一個集合中成對物件之間的關聯性。」
「一張圖是一種結構,描述了一個集合中成對物件之間的關聯性。」
結構兩字可以理解成資料結構,雖然它的本意更接近程式中的 object
「一張圖是一種結構,描述了一個集合中成對物件之間的關聯性。」
結構兩字可以理解成資料結構,雖然它的本意更接近程式中的 object
「一張圖是一種結構,描述了一個集合中成對物件之間的關聯性。」
結構兩字可以理解成資料結構,雖然它的本意更接近程式中的 object
「一張圖是一種結構,描述了一個集合中成對物件之間的關聯性。」
結構兩字可以理解成資料結構,雖然它的本意更接近程式中的 object
:點
:邊
點集:點構成的集合,以 表示
邊集:邊構成的集合,以 表示
圖:點和邊構成的集合,以 表示
Path
Trace
Track
Circuit
Cycle
一般做法 或 ,但可以
怪題思考題
Storage.
在開始前,先了解一下我的習慣...
#include <bits/stdc++.h>
using namespace std;
int n; // |V|
int m; // |E|
int u, v, vertex; // 某個點
int e, edge; // 某個邊
int w, weight; // 某個權重
int cur; // 通常是遞迴時現在在哪個點
int pre, prev; // 上一個點
int next, nxt; // 下一個點
vector<vector<type>> graph; // 圖
vector<int> neighbor; // 一個點附近的點
const int INF = 1e9 + 7;int n, m;
cin >> n >> m;
vector<vector<bool>> graph(n, vector<bool>(n, 0));
for (int i = 0; i < m; i++) {
int u, v;
cin >> u >> v;
graph[u][v] = 1;
graph[v][u] = 1;
}空間複雜度?
int n, m;
cin >> n >> m;
vector<vector<int>> graph(n);
for (int i = 0; i < m; i++) {
int u, v;
cin >> u >> v;
graph[u].push_back(v);
graph[v].push_back(u);
}因為這東西比較常用,所以如果後面有 graph 應該都是指鄰接串列的存法
| 方式 | 鄰接矩陣 | 鄰接串列 |
|---|---|---|
| 空間複雜度 | ||
| 存取特定邊 | ||
| 枚舉邊 |
struct Node {
int weight; // 點的資訊
struct Edge {
int v;
int weight; // 邊的資訊
};
vector<Edge> neighbor;
};
vector<Node> graph;比較少用到的東西
int n, m;
cin >> n >> m;
vector<pair<int, int>> edges;
for (int i = 0; i < m; i++) {
int u, v;
cin >> u >> v;
edges.push_back({u, v});
}edge_id
edge_id
edge_id
edge_id
edge_id
edge_id
edge_id
edge_id
struct Graph {
struct Edge {
int next;
int v;
} edges[max_m];
int neighbor[max_n];
int edge_id = 0;
void add_edge(int u, int v) {
edges[edge_id].v = v;
edges[edge_id].next = neighbor[u];
neighbor[u] = edge_id;
edge_id++;
}
};Traversal.
Graph traversal refers to the process of visiting each node in a graph".
「圖的遍歷代表以某種方式走過圖的每個點」
這次夠白話了吧
等等 是不是哪裡怪怪的
等等 是不是哪裡怪怪的
:那記錄上一個點是誰,然後不要往回走啊
好像還有哪裡怪怪的欸
改成記錄走過的點?
2 號節點表示自己被排擠了
要回溯看看之前的其他點,所以我們採用遞迴
void dfs(int cur, const vector<vector<int>> &graph) {
static vector<bool> visited(graph.size(), false);
visited[cur] = true;
for (const int &nxt: graph[cur])
if(!visited[nxt]) dfs(nxt, graph);
}記得在進點時就要記錄 visited
不然你會兩個點一直來回跳
你會發現,距離越近的點淹得越快
如何知道下一輪要淹哪?
你可以在淹一輪後掃過整個點集
如果這個點有淹水且它的鄰居沒有淹就淹下去
你可以在淹一輪後掃過整個點集
如果這個點有淹水且它的鄰居沒有淹就淹下去
時間複雜度?
時間複雜度?
時間複雜度?
花太多時間決定下一輪淹哪了
時間複雜度?
每個點被經過一次 + 每條邊最多被處理兩次
void bfs(int start, const vector<vector<int>> &graph) {
queue<int> nexts;
vector<int> visited(graph.size(), false);
nexts.push(start), visited[start] = true;
while(!nexts.empty()) {
int cur = nexts.top();
nexts.pop();
for (const int &nxt: graph[cur]) {
if(visited[nxt]) continue;
visited[nxt] = true;
nexts.push(nxt);
}
}
}在 push 進 queue 時就要記得 visited!
小觀察:把 queue 換成 stack 就是在 dfs 了
但通常會用遞迴啦 好寫
const int dx[] = {1, 0, -1};
const int dy[] = {1, 0, -1};
void dfs(int cur_x, int cur_y, const vector<vector<int>> &graph) {
vector<vector<bool>> visited(graph.size(), vector<bool> graph[0].size());
for (int i: dx)
for (int j: dy)
if (!visited[cur_x + i][cur_y + j])
visited[cur_x + i][cur_y + j] = true,
dfs(cur_x + i, cur_y + j, graph);
}把重複的部分換成迴圈
如果你只要上下左右就自己調整吧
二分圖的課時會講更酷的做法
iscoj 4534 (電研一四學術上機考 B3)
補:2023 APCS 10月場 P3 / ZJ m372
但我懶得用 DFS 題解在後面 DSU
Topological Sort.
ㄆ
ㄨ
Queue: {}
Result: {}
Queue: {0, 4}
Result: {}
Queue: {4, 1}
Result: {0}
Queue: {1}
Result: {0, 4}
Queue: {2}
Result: {0, 4, 1}
Queue: {3}
Result: {0, 4, 1, 2}
Queue: {}
Result: {0, 4, 1, 2, 3}
vector<int> topological_sort(const vector<vector<int>> &graph) {
vector<int> result;
vector<int> indegree(graph.size(), 0);
for (const auto &i : graph)
for (const auto &j : i)
indegree[j]++;
queue<int> origin;
for (int v = 0; v < graph.size(); v++)
if (!indegree[v]) origin.push(v);
while (!origin.empty()) {
int cur = origin.front();
result.push_back(cur);
origin.pop();
for (auto &neighbor : graph[cur])
if (--indegree[neighbor] == 0) origin.push(neighbor);
}
return result;
}扣
話說真的真的可以這樣寫欸
struct Node {
int in_time, out_time;
bool visited = false;
vector<int> neighbor;
};
void dfs(int cur, vector<Node> &graph) {
static int time_stamp = 0;
graph[cur].in_time = time_stamp++;
graph[cur].visited = true;
for (const auto &nxt : graph[cur].neighbor)
if (!graph[nxt].visited) dfs(nxt, graph);
graph[cur].out_time = time_stamp++;
}vector<int> topological_sort(const vector<vector<int>> &graph) {
vector<int> result;
result.reserve(graph.size());
vector<int> in_time(graph.size(), 0), out_time(graph.size(), 0);
auto dfs = [&](int cur, auto &&dfs) -> bool {
static int time_stamp = 0;
in_time[cur] = ++time_stamp;
for (const auto &nxt : graph[cur]) {
if (!in_time[nxt]) {
if (!dfs(nxt, dfs)) return false;
}
else if (!out_time[nxt]) {
return false;
}
}
result.push_back(cur);
out_time[cur] = ++time_stamp;
return true;
};
for (int origin = 0; origin < graph.size(); origin++)
if (!in_time[origin])
if (!dfs(origin, dfs)) return vector<int>(0);
return result;
}注意如果是用 vector 直接 push_back 排出來的結果是由輩分小到大
bool dfs(int cur, const vector<vector<int>> &graph, vector<int> &result, vector<int> &in_time, vector<int> &out_time) {
static int time_stamp = 0;
in_time[cur] = ++time_stamp;
for (const auto &nxt : graph[cur]) {
if (!in_time[nxt]) {
if (!dfs(nxt, graph, result, in_time, out_time)) return false;
} else if (!out_time[nxt])
return false;
}
result.push_back(cur);
out_time[cur] = ++time_stamp;
return true;
}
vector<int> topological_sort(const vector<vector<int>> &graph) {
vector<int> result;
result.reserve(graph.size());
vector<int> in_time(graph.size(), 0), out_time(graph.size(), 0);
for (int origin = 0; origin < graph.size(); origin++)
if (!in_time[origin])
if (!dfs(origin, graph, result, in_time, out_time)) return vector<int>(0);
return result;
}給看不懂 lambda 函式的人
很多都是負責人丟給我的(
Shortest Path.
vector<int> Bellman_Ford(int origin, int n, const vector<vector<pair<int, int>>> &graph) {
vector<int> d(graph.size(), INF); // 從源點到各個點的答案
for (int i = 0; i < graph.size(); i++)
for (int v = 0; v < graph.size(); v++)
for (const pair<int, int> &edge: graph[v])
#define edge.second w
#define edge.first u
if (d[v] + w < d[u]) d[u] = d[v] + w;
return d;
}vector<int> SPFA(int origin, const vector<vector<pair<int, int>>> &graph;) {
vector<int> d(graph.size(), INF);
vector<bool> inQueue(graph.size(), false);
queue<int> nexts;
nexts.push(origin);
inQueue[origin] = true;
while (!nexts.empty()) {
int v = nexts.front();
nexts.pop();
inQueue[v] = false;
for (const pair<int, int> &edge : graph[v]) {
#define w edge.second
#define u edge.first
if (d[v] + w < d[u] && !inQueue[u]) {
d[u] = d[v] + w;
nexts.push(u);
inQueue[u] = true;
}
}
}
return d;
}struct Edge {
int v, w;
};
vector<int> Dijkstra(int origin, const vector<vector<Edge>> &graph) {
vector<int> d(graph.size(), INF);
vector<bool> visited(graph.size(), false);
d[origin] = 0;
priority_queue<Edge, vector<Edge>,
[](const Edge &a, const Edge &b) -> bool {
return a.w > b.w;
}
> nexts;
nexts.push({origin, 0});
while (!nexts.empty()) {
Edge cur = nexts.top();
nexts.pop();
if (visited[cur.v]) continue;
visited[cur.v] = true;
for (const Edge& e : graph[cur.v]) {
if (cur.w + e.w >= d[e.v]) continue;
d[e.v] = cur.w + e.w;
nexts.push({e.v, d[e.v]});
}
}
return d;
}struct Edge {
int v, w;
friend bool operator<(const Edge& a, const Edge& b) {
return a.w > b.w;
}
};
vector<vector<Edge>> graph;
vector<int> Dijkstra(int origin) {
vector<int> d(graph.size(), INF);
vector<bool> visited(graph.size(), false);
d[origin] = 0;
priority_queue<Edge> nexts;
nexts.push({origin, 0});
while (!nexts.empty()) {
Edge cur = nexts.top();
nexts.pop();
if (visited[cur.v]) continue;
visited[cur.v] = true;
for (const Edge& e : graph[cur.v]) {
if (cur.w + e.w >= d[e.v]) continue;
d[e.v] = cur.w + e.w;
nexts.push({e.v, d[e.v]});
}
}
return d;
}吃點毒
單點源 Ver.
vector<int> DAG_shortest_path(int origin, const vector<vector<pair<int, int>>> &graph) {
vector<int> sort_result = topological_sort(graph);
vector<int> result(graph.size(), INF);
result[origin] = 0;
int origin_index = 0;
while (sort_result[origin_index] != origin) origin_index++;
for (int u = origin_index; u < graph.size(); u++)
for (const auto &[v, w] : graph[sort_result[u]])
result[v] = min(result[v], result[sort_result[u]] + w);
return result;
}處理負環
處理負權
帶環
時間複雜度
處理負環
處理負權
帶環
時間複雜度
處理負環
處理負權
帶環
時間複雜度
帶負權/負環時用
一般情況最常用
僅 DAG 上可用
一樣,處理不了負環
但是負權會是好的
vector<vector<int>> Floyd_Warshall(const vector<vector<pair<int, int>>> &graph) {
vector<vector<int>> result(graph.size(), vector<int>(graph.size(), INF));
for (int i = 0; i < graph.size(); i++) result[i][i] = 0;
for (int u = 0; u < graph.size(); u++)
for (const auto &[v, w] : graph[u])
result[u][v] = w;
for (int k = 0; k < graph.size(); k++)
for (int u = 0; u < graph.size(); u++)
for (int v = 0; v < graph.size(); v++)
result[u][v] = min(result[u][v], result[u][k] + result[k][v]);
return result;
}0 到 4 最短路:0->2->3->4 = 0
0 到 4 最短路:0->2->3->4 = 0
全部 +2
0 到 4 最短路:0->2->3->4 = 0
全部 +2
最短路:0->1->4 = 5
0->1->4 總共被 +4
0->2->3->4 總共被 +6
vector<vector<int>> Johnson(vector<vector<pair<int, int>>> graph) {
vector<int> h(graph.size(), 0);
for (int i = 0; i < graph.size(); i++)
for (int u = 0; u < graph.size(); u++)
for (const auto &[v, w] : graph[u])
h[v] = min(h[v], h[u] + w);
for (int u = 0; u < graph.size(); u++)
for (auto &[v, w] : graph[u])
w += h[u] - h[v];
vector<vector<int>> result;
for (int u = 0; u < graph.size(); u++) result[u] = Dijkstra(u, graph);
for (int u = 0; u < graph.size(); u++)
for (int v = 0; v < graph.size(); v++)
result[u][v] -= h[u] - h[v];
return result;
}我好像沒看到有學長的簡報裡有這東西(?
會不會用上是個好問題
Lowest Common Ancestor, LCA
depth = 0
depth = 1
depth = 2
namespace BinaryLifting {
vec<vec<int>> ancestors;
vec<int> depths;
void dfs(int cur, int pre, int cur_depth, const vec<vec<int>> &tree) {
depths[cur] = cur_depth;
ancestors[0][cur] = pre;
for (const int &nxt : tree[cur])
if (nxt != pre)
dfs(nxt, cur, cur_depth + 1, tree);
}
void build_ancestor_table(const vec<vec<int>> &tree) {
depths.resize(tree.size());
ancestors.resize(std::__lg(tree.size()) + 1);
for (auto &_list : ancestors) _list.resize(tree.size());
dfs(0, 0, 0, tree);
for (int i = 0; i < ancestors.size() - 1; i++)
for (int u = 0; u < tree.size(); u++)
ancestors[i + 1][u] = ancestors[i][ancestors[i][u]];
}
}是共祖
不是共祖
起點
右界
cur
mid
i = 2
是共祖
不是共祖
起點
右界
cur
mid
i = 1
是共祖
不是共祖
起點
右界
cur
mid
i = 1
是共祖
不是共祖
起點
右界
cur
mid
i = 0 break
是共祖
不是共祖
起點
右界
cur
i = 0 break
namespace BinaryLifting {
int LCA(int u, int v) {
if (depths[v] > depths[u]) std::swap(u, v);
for (int diff = depths[u] - depths[v], i = 0; diff; diff >>= 1, i++)
if (diff & 1)
u = ancestors[i][u];
if (u == v) return u;
for (int i = ancestors.size() - 1; i >= 0; i--)
if (ancestors[i][u] != ancestors[i][v])
u = ancestors[i][u], v = ancestors[i][v];
return ancestors[0][u];
}
}思考練習:把RMQ轉化成LCA
Disjoint Set Union Algorithm, DSU
「我是你今晚的噩夢。」
「參加資讀就別想逃過我的魔爪。」
– Robert Endre Tarjan,
沒有說過
「不少他發明的算法都以他的名字命名,以至於有時會讓人混淆幾種不同的算法。」
– 維基百科
Dis - 不, Joint - 共同, Set - 集合
有交集
Dis - 不, Joint - 共同, Set - 集合
不交集
簡單來說,各集合彼此之間沒有交集
啊啊爛了,1 和 2 回傳的代表元素不同
查詢
struct DSU {
vector<int> master;
DSU(int n) {
master.resize(n);
for (int i = 0; i < n; i++) master[i] = i;
}
int find(int i) {
if (master[i] == i) return i;
return find(master[i]);
}
};struct DSU {
void combine(int a, int b) {
master[find(a)] = find(b);
}
};合併
看起來的樣子
看起來的樣子
Merge(2, 3)
查詢完後有效降低樹高了!
查詢完後有效降低樹高了!
但這樣單次查詢還是 O(n) 耶...
樹高:根到最遠點路徑長
樹高:根到最遠點路徑長
樹高:根到最遠點路徑長
新樹高:
struct DisjointSet {
vector<int> master, depth;
DisjointSet(int n) {
master.resize(n);
depth.resize(n, 0);
for (int i = 0; i < n; i++) master[i] = i;
}
int find(int n) {
if (n == master[n]) return n;
return (master[n] = find(master[n]));
}
void combine(int a, int b) {
a = find(a), b = find(b);
if (a == b) return;
if (depth[a] < depth[b]) swap(a, b);
else if (depth[a] == depth[b]) depth[a]++;
master[b] = a;
}
};綜合
APCS 2023 十月場 P3 / ZJ m372
Minimum Spanning Tree, MST.
namespace MST {
struct DSU {
vector<int> master, depth;
DSU(int n) {
master.resize(n);
depth.resize(n, 0);
for (int i = 0; i < n; i++) master[i] = i;
}
int find(int n) {
return (n == master[n]) ? n : (master[n] = find(master[n]));
}
void combine(int a, int b) {
a = find(a), b = find(b);
if (a == b) return;
if (depth[a] < depth[b]) swap(a, b);
else if (depth[a] == depth[b]) depth[a]++;
master[b] = a;
}
};
vector<vector<pair<int, int>>> Kruskal(const vector<vector<pair<int, int>>> &graph) {
DSU components(graph.size());
vector<pair<int, pair<int, int>>> edges; // {w, {u, v}}
vector<vector<pair<int, int>>> result(graph.size());
for (int u = 0; u < graph.size(); u++)
for (const auto &[v, w] : graph[u])
edges.push_back({w, {u, v}});
sort(edges.begin(), edges.end());
for (const auto &[w, e] : edges) {
#define u e.first
#define v e.second
if (components.find(u) != components.find(v)) {
components.combine(u, v);
result[u].push_back({v, w}), result[v].push_back({u, w});
}
}
#undef u
#undef v
return result;
}
}事實上如果原本圖就用邊串列存會方便很多
如果用鄰接串列存圖建議用下一個寫法
typedef pair<int, int> pii;
typedef pair<int, pii> pipii;
typedef vector<vector<pair<int, int>>> Graph;
Graph Prim(const Graph &graph) {
// edge: {w, v}
Graph result(graph.size());
vector<bool> visited(graph.size(), false);
priority_queue<pipii, vector<pipii>, greater<pipii>> nexts;
#define w first
#define u second.first
#define v second.second
visited[0] = true;
for (const auto &[nxt_w, nxt_v] : graph[0])
nexts.push({nxt_w, {0, nxt_v}});
while (!nexts.empty()) {
auto cur_edge = nexts.top();
nexts.pop();
if (visited[cur_edge.v]) continue;
visited[cur_edge.v] = true;
result[cur_edge.u].push_back({cur_edge.w, cur_edge.v});
result[cur_edge.v].push_back({cur_edge.w, cur_edge.u});
for (const auto &[nxt_w, nxt_v] : graph[cur_edge.v])
nexts.push({nxt_w, {cur_edge.v, nxt_v}});
}
#undef u
#undef v
#undef w
return result;
}Connectivity.
「我是你今晚的噩夢。」
「參加資讀就別想逃過我的魔爪。」
– Robert Endre Tarjan,
沒有說過
「不少他發明的算法都以他的名字命名,以至於有時會讓人混淆幾種不同的算法。」
– 維基百科
樹邊:DFS Tree 中的邊
返祖邊:剩下不是樹邊的邊
因為左邊沒有邊能不經過紅點到達右邊,所以它是割點
因為左右邊所有點都能不經過紅點到達彼此,所以它不是割點
以紅點為根的子樹中,左邊一定要經過紅點到達其他部分
所以紅點是割點
以紅點為根的子樹中所有點都可以不經由紅點連到其他部分,所以它不是割點
你會發現,你的 DFS 樹應該長這樣
而非這樣
using Graph = vector<vector<int>>;
vector<bool> cut_vertex(const Graph &graph) {
int n = graph.size();
vector<int> dfn(n, 0), low(n, 0);
vector<bool> result(n, false);
int time = 0;
auto dfs = [&](int cur, int pre, auto &&dfs) -> void {
dfn[cur] = low[cur] = ++time;
for (const int &nxt : graph[cur]) {
if (nxt == pre) continue;
if (dfn[nxt]) {
low[cur] = min(low[cur], dfn[nxt]);
}
else {
dfs(nxt, cur, dfs);
if (low[nxt] > dfn[cur]) result[cur] = true;
low[cur] = min(low[cur], dfn[nxt]);
}
}
};
int child_count = 0;
for (const auto &child : graph[0]) {
if (dfn[child]) continue;
child_count++;
dfs(child, 0, dfs);
}
if (child_count > 1) result[0] = true;
return result;
}void bridge(int cur, int pre, const vector<vector<int>> &graph, vector<pair<int, int>> &result, vector<int> &dfn, vector<int> &low) {
static int cur_dfn = 0;
dfn[cur] = ++cur_dfn;
low[cur] = dfn[cur];
for (const auto &nxt : graph[cur]) {
if (nxt == pre) continue;
if (!dfn[nxt]) {
bridge(nxt, cur, graph, result, dfn, low);
low[cur] = min(low[cur], low[nxt]);
if (low[nxt] > dfn[cur]) result.push_back({cur, nxt});
}
else {
low[cur] = min(low[cur], dfn[nxt]);
}
}
}如果不是簡單圖記得處理重邊
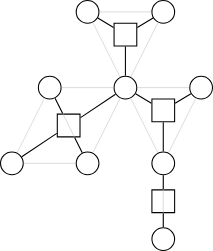
Components.
「我是你今晚的噩夢。」
「參加資讀就別想逃過我的魔爪。」
– Robert Endre Tarjan,
沒有說過
「不少他發明的算法都以他的名字命名,以至於有時會讓人混淆幾種不同的算法。」
– 維基百科
「我是你今晚的噩夢。」
「參加資讀就別想逃過我的魔爪。」
– Robert Endre Tarjan,
沒有說過
「不少他發明的算法都以他的名字命名,以至於有時會讓人混淆幾種不同的算法。」
– 維基百科
「等等,那個 2 剛剛是不是出現了三次」
←當你到這裡時,會發現 low[nxt] = dfn[cur]
cur
nxt
cur
nxt
這是剛剛經過的子樹
cur
nxt
將它連起來
cur
nxt
接著是來到這裡
cur
nxt
這是我們 BCC 還沒用過的點 / stack 還剩下的範圍
cur
nxt
建方點,連起來
cur
nxt
還有一個
cur
nxt
還有一個
完成圓方樹
vector<vector<int>> block_cut_tree(const vector<vector<int>> &graph) {
int dfs_clock = 0;
stack<int> path;
vector<vector<int>> result;
result.reserve(graph.size() * 2);
vector<int> dfn(graph.size(), 0);
vector<int> low(graph.size(), INF);
auto dfs = [&](int cur, auto &&dfs) -> void {
low[cur] = dfn[cur] = ++dfs_clock;
path.push(cur);
for (const auto &nxt : graph[cur]) {
if (!dfn[nxt]) {
dfs(nxt, dfs);
low[cur] = min(low[cur], dfn[nxt]);
if (low[nxt] == dfn[cur]) { // find cut vertex / BCC
result.push_back(vector<int>(0));
int square = result.size() - 1;
for(int v = -1; v != nxt; path.pop()) {
v = path.top();
result[v].push_back(square);
result[square].push_back(v);
}
result[square].push_back(cur);
result[cur].push_back(square);
}
}
else {
low[cur] = min(low[cur], dfn[nxt]);
}
}
};
dfs(0, dfs);
return result;
}其實邊雙連通也可以用 stack 喔
「我是你今晚的噩夢。」
「參加資讀就別想逃過我的魔爪。」
– Robert Endre Tarjan,
沒有說過
「這傢伙讓我做簡報做到腦中風。」
– 海之音
返祖邊
樹邊
前向邊
交錯邊
跑看看
返祖邊
樹邊
前向邊
交錯邊
跑看看
返祖邊
樹邊
前向邊
交錯邊
跑看看
返祖邊
樹邊
前向邊
交錯邊
跑看看
返祖邊
樹邊
前向邊
交錯邊
跑看看
返祖邊
樹邊
前向邊
交錯邊
跑看看
返祖邊
樹邊
前向邊
交錯邊
跑看看
返祖邊
樹邊
前向邊
交錯邊
跑看看
返祖邊
樹邊
前向邊
交錯邊
跑看看
返祖邊
樹邊
前向邊
交錯邊
跑看看
返祖邊
樹邊
前向邊
交錯邊
跑看看
返祖邊
樹邊
前向邊
交錯邊
跑看看
返祖邊
樹邊
前向邊
交錯邊
跑看看
返祖邊
樹邊
前向邊
交錯邊
跑看看
返祖邊
樹邊
前向邊
交錯邊
跑看看
返祖邊
樹邊
前向邊
交錯邊
樹 0 節點
樹 1 節點
樹 2 節點
樹邊
樹 0 節點
返祖
前向
交錯
樹 1 節點
樹 2 節點
樹邊
樹 0 節點
返祖
前向
交錯
樹 1 節點
樹 2 節點
樹邊
樹 0 節點
返祖
前向
交錯
樹 1 節點
樹 2 節點
樹邊
樹 0 節點
返祖
前向
交錯
樹 1 節點
樹 2 節點
樹邊
樹 0 節點
返祖
前向
交錯
樹 1 節點
樹 2 節點
樹邊
樹 0 節點
返祖
前向
交錯
樹 1 節點
樹 2 節點
樹邊
樹 0 節點
返祖
前向
交錯
樹 1 節點
樹 2 節點
樹邊
樹 0 節點
返祖
前向
交錯
樹 1 節點
樹 2 節點
樹邊
樹 0 節點
返祖
前向
交錯
樹 1 節點
樹 2 節點
樹邊
樹 0 節點
返祖
前向
交錯
樹 1 節點
樹 2 節點
樹邊
樹 0 節點
返祖
前向
交錯
樹 1 節點
樹 2 節點
樹邊
樹 0 節點
返祖
前向
交錯
樹 1 節點
樹 2 節點
樹邊
子樹 0
返祖
前向
交錯
子樹 1
子樹 2
超級源點
Case 1: 指到的已經被分派 SCC
已經找到對應「割點」
樹邊
返祖
前向
交錯
分支 0
分支 1
子樹根
Case 2: 指到的還沒被分派 SCC
但之後會縮點
Case 3: 指到的還沒被分派 SCC
且之後不會縮點
vector<int> tarjan_SCC(const vector<vector<int>> &graph) {
vector<int> scc(graph.size(), 0);
vector<int> dfn(graph.size(), 0);
vector<int> low(graph.size(), INF);
stack<int> path;
int dfs_clock = 0;
int scc_id = 0;
auto dfs = [&](int cur, auto &&dfs) -> void {
low[cur] = dfn[cur] = ++dfs_clock;
path.push(cur);
for (const auto &nxt : graph[cur]) {
if (scc[nxt]) continue;
if (!dfn[nxt]) dfs(nxt, dfs), low[cur] = min(low[cur], low[nxt]);
else low[cur] = min(low[cur], dfn[nxt]);
}
if (dfn[cur] == low[cur]) {
++scc_id;
for (int v = -1; v != cur; path.pop()) {
v = path.top();
scc[v] = scc_id;
}
}
};
for (int v = 0; v < graph.size(); v++)
if (!dfn[v]) dfs(v, dfs);
return scc;
}原先 A > B > C
A 可以單向走到 B,B 可以單向走到 C
A
B
C
原先 A > B > C
反向後 A 走不到 B,B 走不到 C
這時如果在 A 裡面不管怎麼走都不會走到 B
B 可能會走到 A,但走不到 C
在走 B 前確認完 A 有哪些人,不要碰
A
B
C
vector<int> KosarajuSCC(const vector<vector<int>> &graph) {
vector<vector<int>> hparg(graph.size());
for (int u = 0; u < graph.size(); u++)
for (const auto &v : graph[u])
hparg[v].push_back(u);
vector<int> sort_result;
sort_result.reserve(graph.size());
vector<bool> visited(graph.size(), false);
auto dfs = [&](int cur, auto &&dfs) -> void {
visited[cur] = true;
for (const auto &nxt : graph[cur])
if (!visited[nxt]) dfs(nxt, dfs);
sort_result.push_back(cur);
};
for (int v = 0; v < graph.size(); v++)
if (!visited[v]) dfs(v, dfs);
vector<int> scc(graph.size(), 0);
int scc_id = 0;
auto sfd = [&](int cur, auto &&sfd) -> void {
scc[cur] = scc_id;
for (const auto &nxt : hparg[cur])
if (!scc[nxt]) sfd(nxt, sfd);
};
for (auto v_pt = scc.rbegin(); v_pt != scc.rend(); v_pt++)
if (!scc[*v_pt]) ++scc_id, sfd(*v_pt, sfd);
}會這麼長是因為建反圖等等的都在裡面
實際上算法本體不到 20 行
重點是他不是 Tarjan ,他很直觀
同色代表同個弱連通分量
Other Classes.
System of Difference Constraints, 2-SAT
題目應該在最短路有混一點(
題單待補
有人要猜猜看總簡報頁數嗎
By 海之音
名詞解釋: - 由各種線條、形狀、色彩等描繪成的形象或畫面。 - 疆域。 - 欲念。 動詞解釋: - 繪畫、描繪。 - 策劃、考慮。 - 謀取、謀求。



