

Lecture 4: Linear Classification
Intro to Machine Learning

Recap:
"Use" a model
"Learn" a model
\rightarrow
\downarrow
\boxed{h}
Regression
Algorithm
\rightarrow
\(\mathcal{D}_\text{train}\)
\rightarrow
🧠⚙️
hypothesis class
loss function
hyperparameters
regressor
\in \mathbb{R}^d
\in \mathbb{R}
g
\downarrow
\downarrow
x
Recap:
"Use" a model
"Learn" a model
\rightarrow
\downarrow
train, optimize, tune, adapt ...
adjusting/updating/finding \(\theta\)
gradient based
\boxed{h}
Regression
Algorithm
\rightarrow
\(\mathcal{D}_\text{train}\)
\rightarrow
🧠⚙️
hypothesis class
loss function
hyperparameters
regressor
\in \mathbb{R}^d
\in \mathbb{R}
g
\downarrow
\downarrow
x
predict, test, evaluate, infer ...
plug in the \(\theta\) found
no gradients involved
Today:
{"good", "better", "best", ...}
\(\{0,1\}\)
\(\{😍, 🥺\}\)
{"Fish", "Grizzly", "Chameleon", ...}
Classification
Algorithm
🧠⚙️
hypothesis class
loss function
hyperparameters
classifier
\in \mathbb{R}^d
\in \text{a discrete set}
\downarrow
x
g
\downarrow
\rightarrow
\boxed{h}
\(\mathcal{D}_\text{train}\)
\rightarrow
Outline
- Linear (binary) classifiers
- to use: separator, normal vector
- to learn: very difficult!
- Linear logistic (binary) classifiers
- Linear multi-class classifiers
-
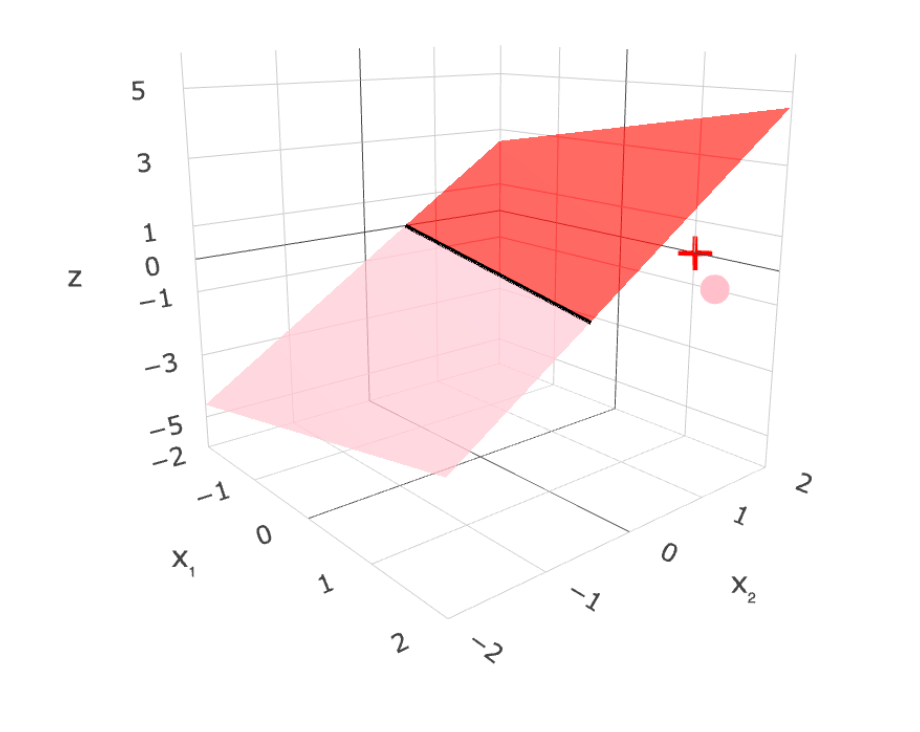
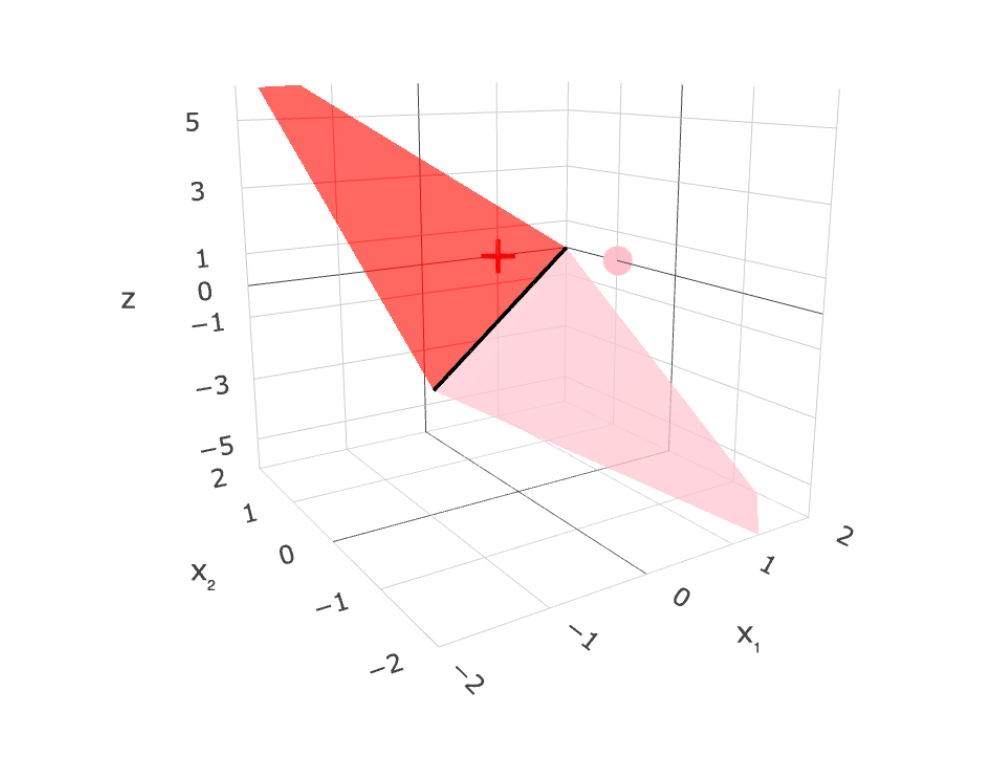
Linear (binary) classifiers
- to use: separator, normal vector
- to learn: very difficult!
- Linear logistic (binary) classifiers
- Linear multi-class classifiers
linear regressor
linear binary classifier
features
parameters
linear combination
predict
\(x \in \mathbb{R}^d\)
\(\theta \in \mathbb{R}^d, \theta_0 \in \mathbb{R}\)
\(\theta^T x +\theta_0\)
\(g = z\)
\(=z\)
if \(z > 0\)
otherwise
\left\{
\begin{array}{l}
\\
\\
\end{array}
\right.
\(1\)
0
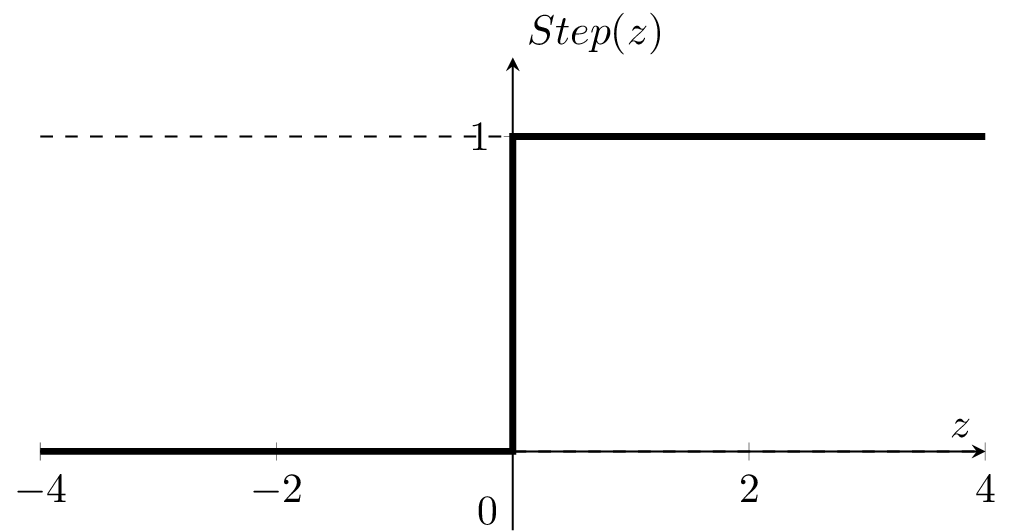
today, we refer to \(\theta^T x +\theta_0\) as \(z\) throughout.
\(g=\)
label
\(y\in \mathbb{R}\)
\(y\in \{0,1\}\)
Outline
-
Linear (binary) classifiers
- to use: separator, normal vector
- to learn: very difficult!
- Linear logistic (binary) classifiers
- Linear multi-class classifiers
\mathcal{L}_{01}(g, y)=\left\{\begin{array}{ll}
0 & \text { if } \text{guess} = \text{label} \\
1 & \text { otherwise }
\end{array}\right .
- To learn a model, need a loss function.
g = \operatorname{step}\left(z\right) = \operatorname{step}\left(\theta^{\top} x+\theta_0\right)
- Very intuitive, and easy to evaluate 😍
- One natural loss choice:
y
\mathcal{L}_{01}(g, y) = 0
\mathcal{L}_{01}(g, y) = 0
\mathcal{L}_{01}(g, y) = 0
\mathcal{L}_{01}(g, y) = 1
\({J}_{01}(\theta)\) very hard to optimize (NP-hard) 🥺
- "Flat" almost everywhere (zero gradient \(\nabla_{\theta}{J}_{01}(\theta)\))
- "Jumps" elsewhere (no gradient)
linear binary classifier
features
parameters
linear combo
predict
\(x \in \mathbb{R}^d\)
\(\theta \in \mathbb{R}^d, \theta_0 \in \mathbb{R}\)
\(\theta^T x +\theta_0\)
\(=z\)
loss
\mathcal{L}_{01} = \left\{\begin{array}{ll}
0 & \text { if } g = y \\
1 & \text { otherwise }
\end{array}\right .
g = z
linear regressor
- closed-form formula
- gradient descent
optimize
method
if \(z > 0\)
otherwise
\left\{
\begin{array}{l}
\\
\\
\end{array}
\right.
\(1\)
0
\(g=\)
\(y \in \mathbb{R}\)
\(y \in \{0,1\}\)
training error almost "flat" w.r.t \(\theta,\) gradient gives very little info
\mathcal{L}(g, y)
\mathcal{L}_{\text{squared}} = (g - y)^2
\(\mathcal{L}_{01}(g, y)\) is "flat" and discrete in \(g\)
\(g\) is "flat" and discrete in \(\theta\)
Outline
- Linear (binary) classifiers
-
Linear logistic (binary) classifiers
- to use: sigmoid
- to learn: negative log-likelihood loss
- Linear multi-class classifiers
linear binary classifier
features
parameters
linear combo
predict
\(x \in \mathbb{R}^d\)
\(\theta \in \mathbb{R}^d, \theta_0 \in \mathbb{R}\)
\(\theta^T x +\theta_0\)
\(=z\)
linear logistic binary classifier
if \(z > 0\)
otherwise
\left\{
\begin{array}{l}
\\
\\
\end{array}
\right.
\(1\)
0
if \(\sigma(z) > 0.5\)
otherwise
\left\{
\begin{array}{l}
\\
\\
\end{array}
\right.
\(1\)
0
Sigmoid \(\sigma\left(\cdot\right):\) confidence or estimated likelihood that \(x\) belongs to the positive class
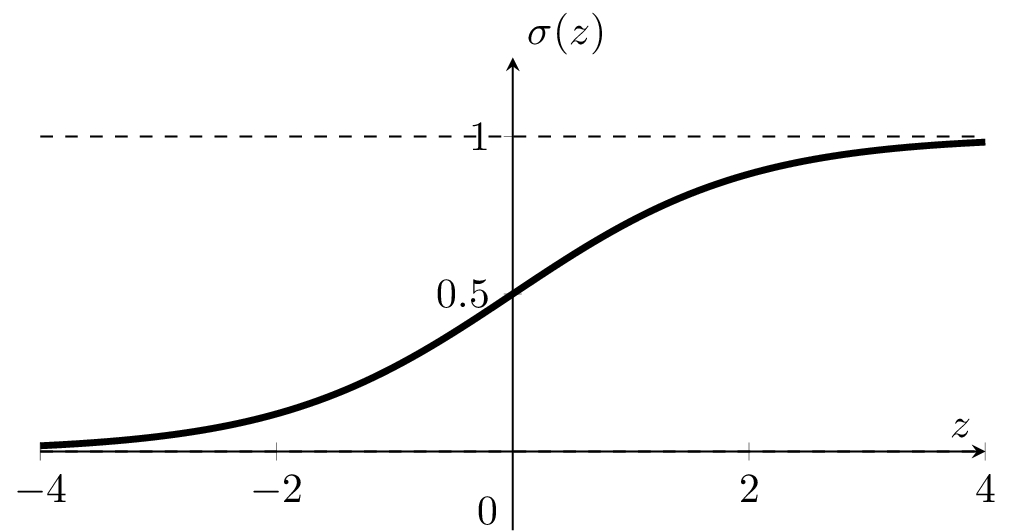
:= \frac{1}{1+e^{-z}}
- \(\theta\), \(\theta_0\) can flip, squeeze, expand, or shift the \(\sigma\left(x\right)\) graph horizontally
- \(\sigma\left(\cdot\right)\) monotonic, very elegant gradient (see hw/lab)
linear logistic binary classifier
1d feature
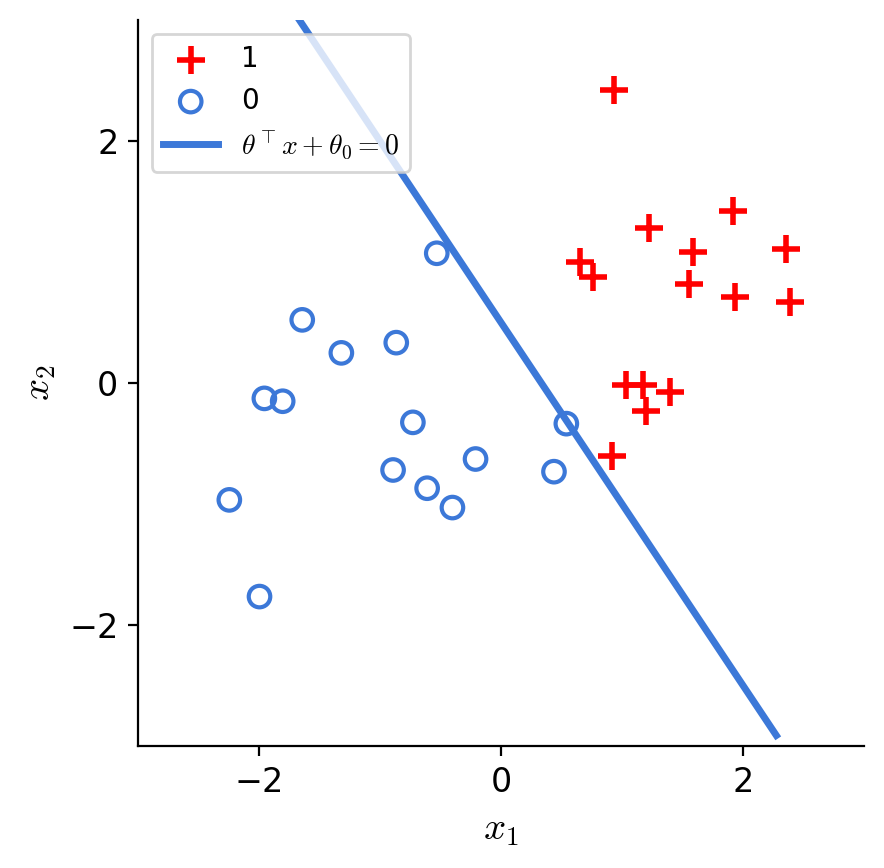
2d features
features: \(x \in \mathbb{R}^d\)
parameters: \(\theta \in \mathbb{R}^d, \theta_0 \in \mathbb{R}\)
the logit \(z\):
z = \theta^{\top} x + \theta_0
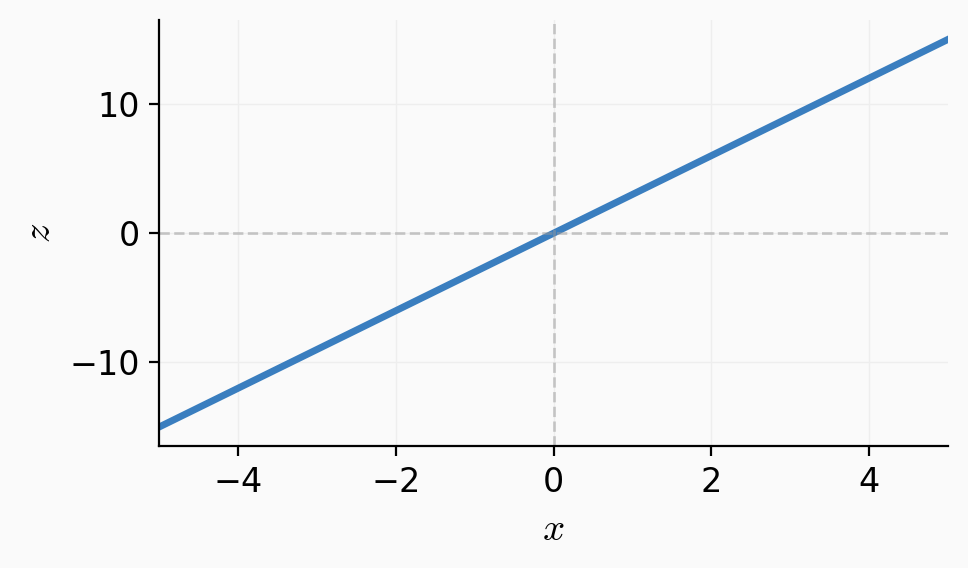
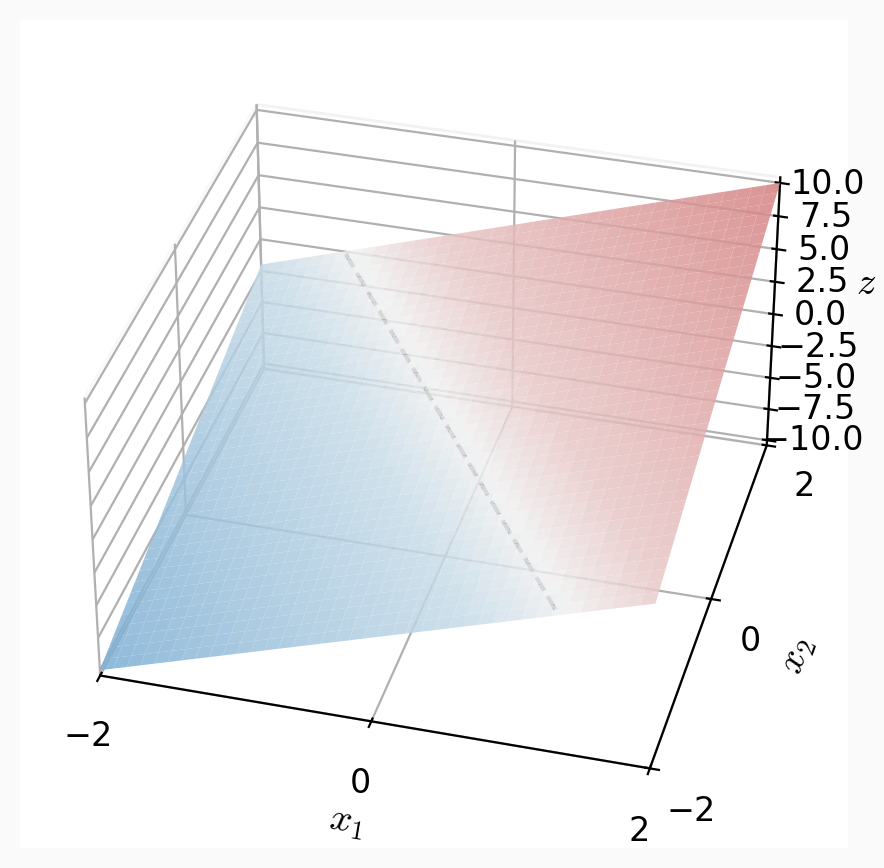
apply sigmoid:
\sigma(z) = \frac{1}{1+e^{-z}}
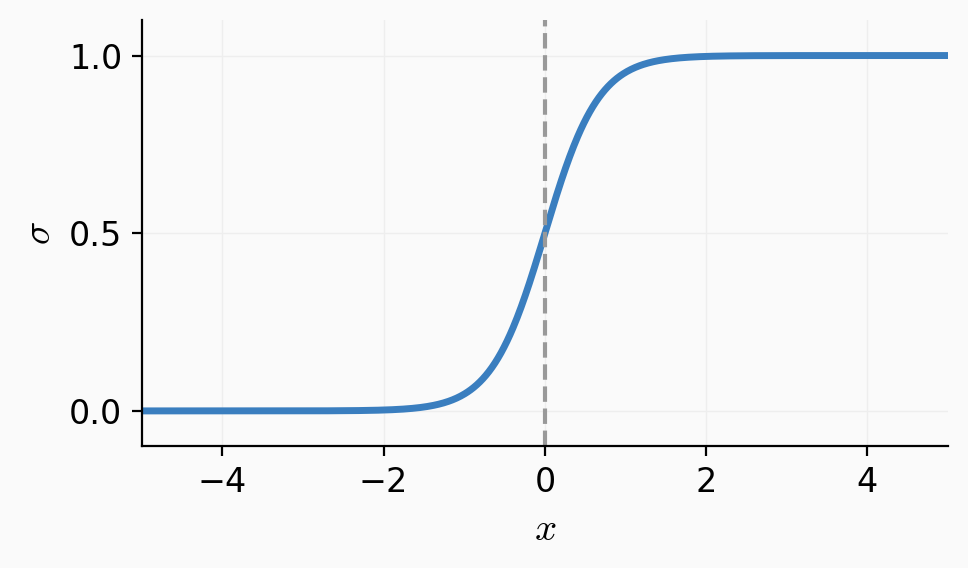
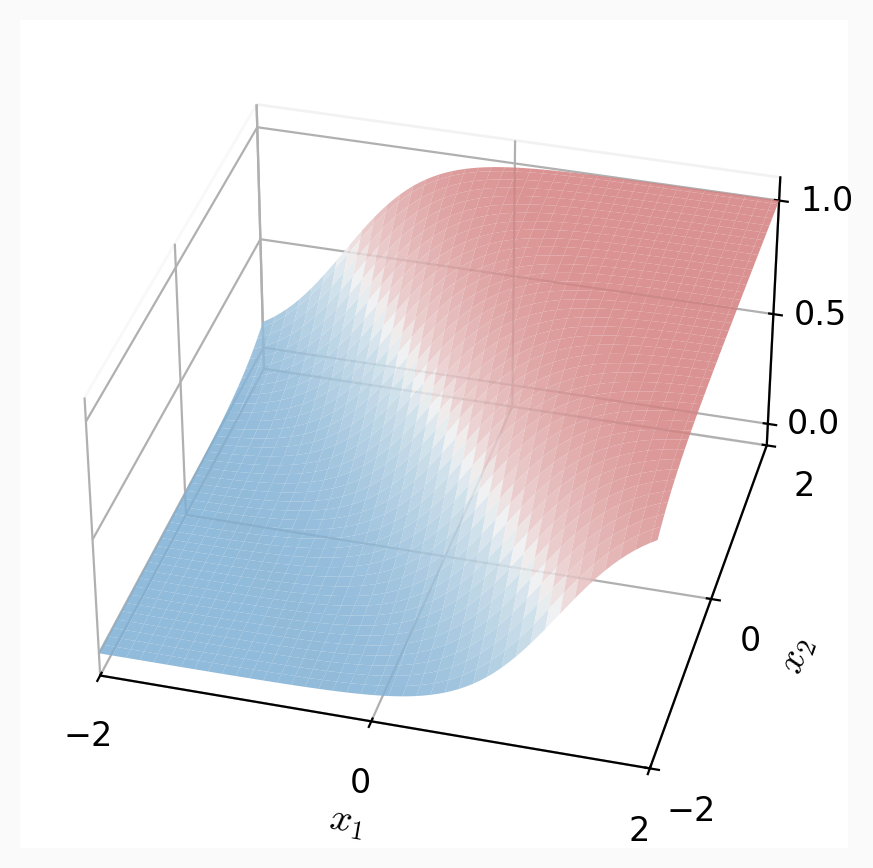
Predict 1 if \(\sigma(z) > 0.5\), else 0.
\sigma(z) = 0.5 \;\Longleftrightarrow\; z = 0
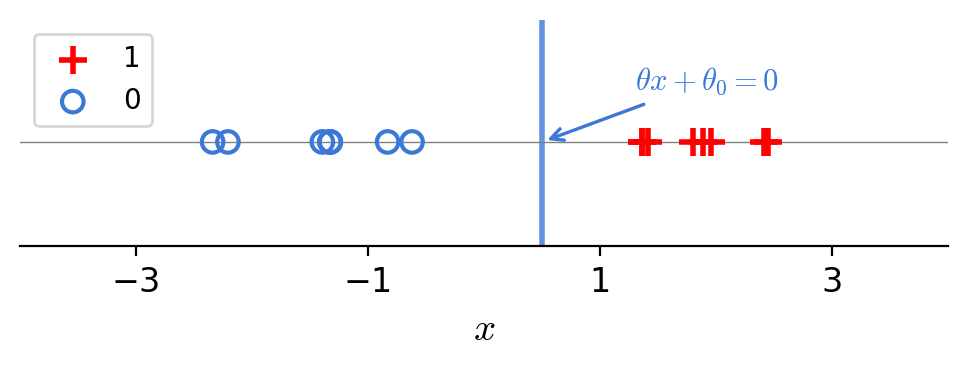
\Longleftrightarrow\; \theta^{\top} x + \theta_0 = 0
separator is linear in feature \(x\)!
Outline
- Linear (binary) classifiers
- Linear logistic (binary) classifiers
- to use: sigmoid
- to learn: negative log-likelihood loss
- Linear multi-class classifiers
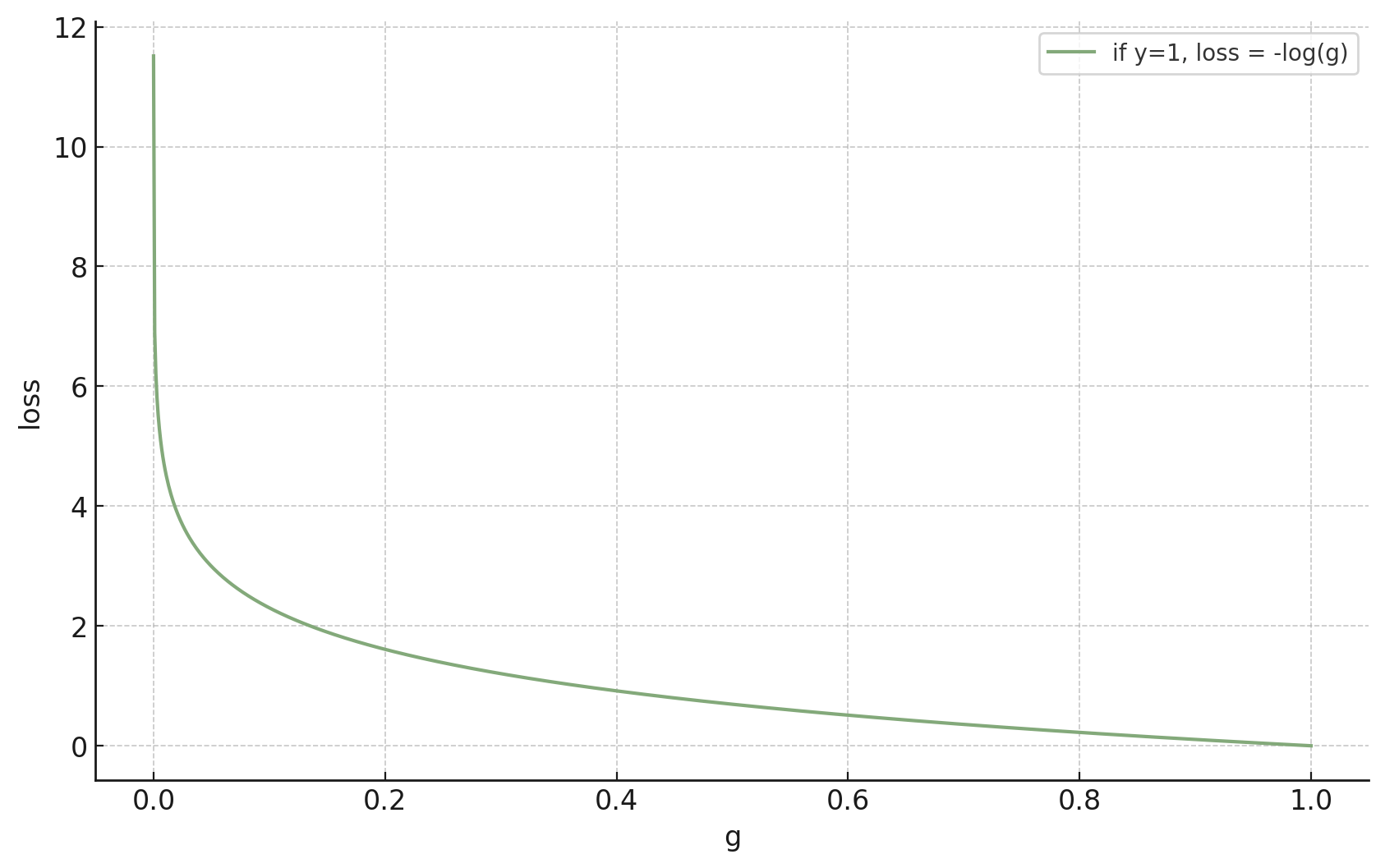
Example: a single training data from \(y = 1\) class
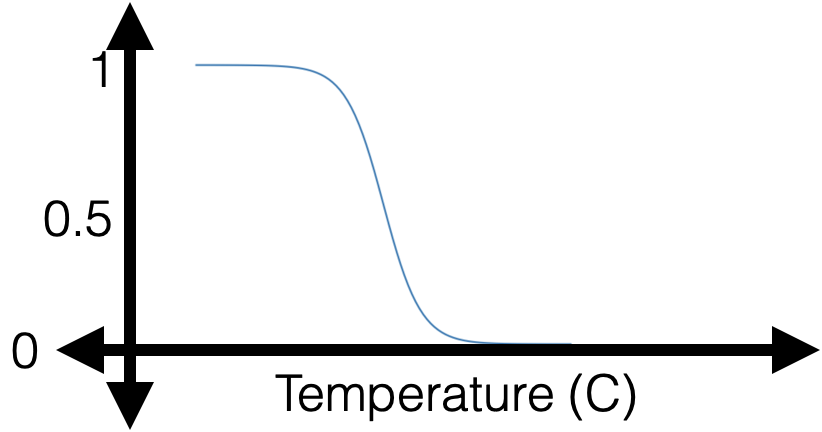
😍
🥺
\mathcal{L}_{\text {nll }}({ g, y })
😍
🥺
g
g
= - \log g

\(g\) near \(1\)
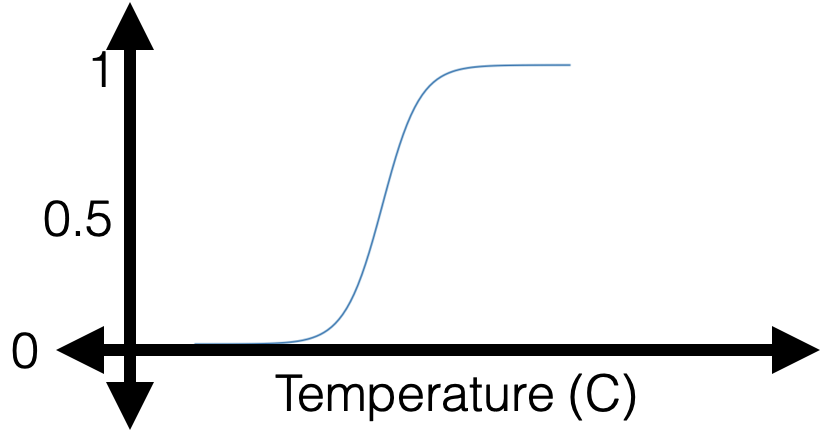
\(g\) near \(0\)
want a smooth loss \(\mathcal{L}(g, y)\) to reward \(g\) closer to \(y\)?
negative
log
likelihood
😍
🥺
😍
🥺
g
g
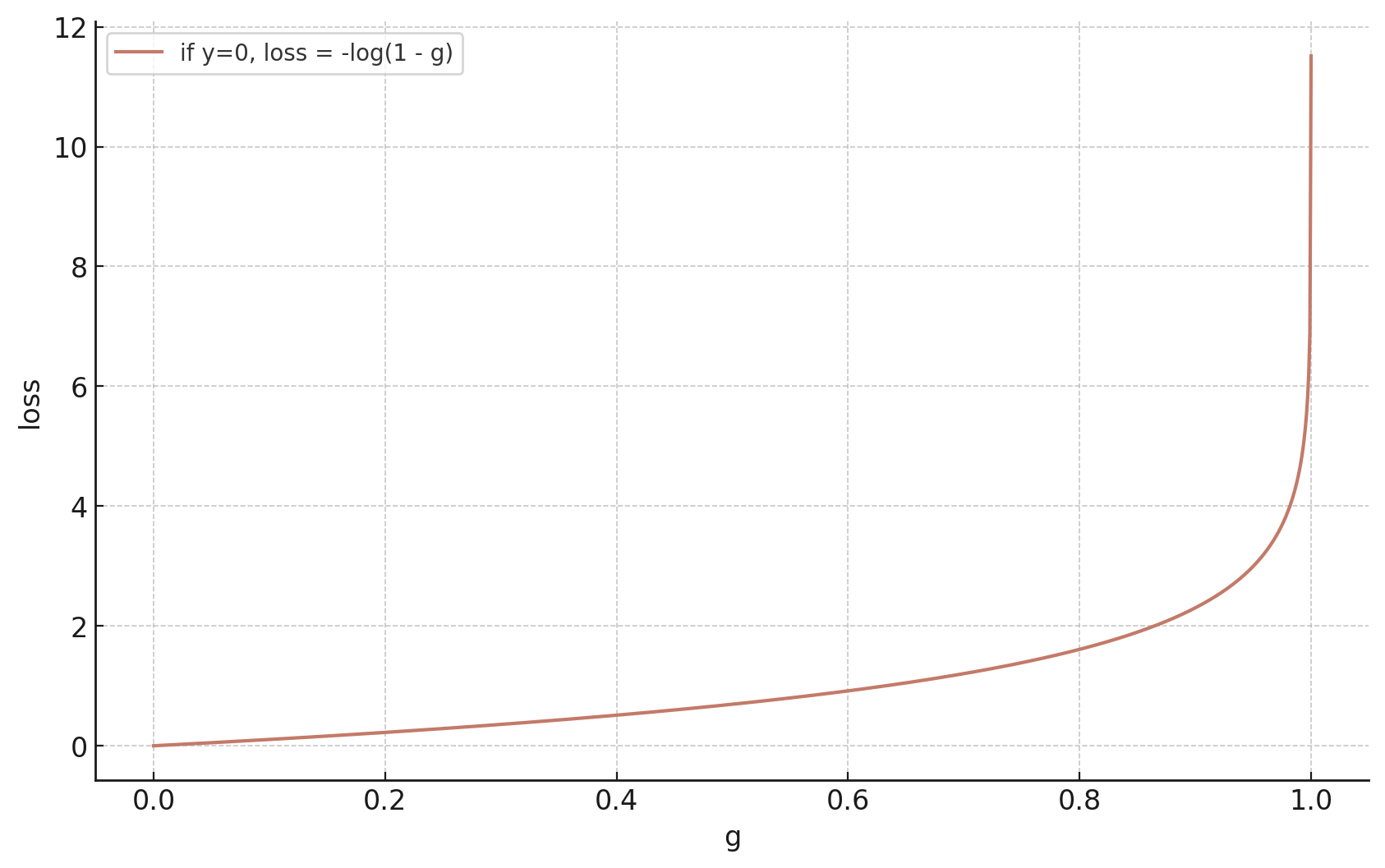
Example: a single training data from \(y = 0 \) class
\(1-g = 1-\sigma\left(\cdot\right):\) the model's predicted likelihood that \(x\) belongs to the negative class.
:=-\log(1-g)
\mathcal{L}_{\text{nll}}(g, 0)
Because the actual label \(y \in \{0,1\},\)
\mathcal{L}_{\text {nll }}(g,y)
= \left\{\begin{array}{ll}-\log(g) & \text{ if } y=1 \\-\log(1-g) & \text{ if } y=0\end{array}\right.
\Leftrightarrow -\left[y \log g + (1-y) \log(1-g)\right]
- When \(y = 1:\)
- \left[\textcolor{#bbbbbb}{y} \log g + {\color{#bbbbbb} \left(1-y \right) \log \left(1-g \right)}\right]
= - \log g
- When \(y = 0\)
- \left[{\color{#bbbbbb} y \log g} + {\color{#bbbbbb} \left(1-y \right)} \log \left(1-g\right)\right]
= - \left[\log \left(1-g \right)\right]
Read as: \(\sum\) (true label for class \(k\)) \(\cdot\) \(-\log\)(predicted prob of class \(k\)).
Since \(y \in \{0,1\}\), only the true class's term survives.
linear binary classifier
linear logistic binary classifier
features
label
parameters
linear combo
predict
loss
optimize via
\(x \in \mathbb{R}^d\)
\(y \in \{0,1\}\)
\(\theta \in \mathbb{R}^d, \theta_0 \in \mathbb{R}\)
\(\theta^T x +\theta_0 = z\)
\left\{\begin{array}{ll}1 & \text { if } z>0 \\0 & \text { otherwise }\end{array}\right .
\left\{\begin{array}{ll}0 & \text { if } g = y \\1 & \text { otherwise }\end{array}\right .
NP-hard to learn
\left\{\begin{array}{ll}1 & \text { if } g = \sigma(z)>0.5 \\0 & \text { otherwise }\end{array}\right .
\left\{\begin{array}{ll}-\log(g) & \text{ if } y=1 \\-\log(1-g) & \text{ if } y=0\end{array}\right.
\Leftrightarrow -\left[y \log g + (1-y) \log(1-g)\right]
gradient descent
training data: \( x= 1, y=1\)
:=-\log(g)
\mathcal{L}_{\text{nll}}(g, 1)
- If the data set is linearly separable, logistic classifier (-log(\sigma) has no (finite) minimizing \(\theta\)
- in theory, \(\theta\) tends to have large magnitude => overly confident
- common to add ridge penalty \(\lambda ||\theta||^2\)
Outline
- Linear (binary) classifiers
- Linear logistic (binary) classifiers
-
Linear multi-class classifiers
- to use: softmax
- to learn: one-hot encoding, cross-entropy loss
Video edited from: HBO, Silicon Valley
🌭
\(x\)
\(\theta^T x +\theta_0\)
\(z \in \mathbb{R}\)
to predict {hotdog, or not_hotdog}, a scalar logit \(z\) suffices
raw score for hotdog
\sigma(z) \in (0,1)
\(1-\sigma\left(\cdot\right):\) predicted probability that \(x\) belongs to not_hotdog
\(\sigma\left(\cdot\right):\) predicted probability that \(x\) belongs to hotdog
normalizing (squashing)
implicitly determines
for \(K > 2\) classes, a single scalar \(z\) no longer suffices — use \(K\) logit scores to keep track
\(\theta \in \mathbb{R}^d, \theta_0 \in \mathbb{R}\)
🌭
\(x\)
\(\theta^T x +\theta_0\)
\(z \in \mathbb{R^3}\)
\text{softmax}(z) \\
\in \mathbb{R^3}
predicted probability that \(x\) belongs to hotdog
normalizing (squashing)
for \(K\) classes, use \(K\) logit scores.
e.g. \(K = 3\): \(\{\)hot-dog, pizza, veggie\(\}\)
predicted probability that \(x\) belongs to pizza
predicted probability that \(x\) belongs to veggie
\(K\) logits
one raw score each category
\(\theta \in \mathbb{R}^{d \times K},\)
\(\theta_0 \in \mathbb{R}^{K}\)
\begin{bmatrix}
1 \\
2 \\
3
\end{bmatrix}
=\begin{bmatrix}
\frac{e^{1}}{e^{1} + e^{2} + e^{3}} \\[6pt]
\frac{e^{2}}{e^{1} + e^{2} + e^{3}} \\[6pt]
\frac{e^{3}}{e^{1} + e^{2} + e^{3}}
\end{bmatrix}
=\begin{bmatrix}
0.0900 \\[6pt]
0.2447 \\[6pt]
0.6653
\end{bmatrix}
\operatorname{softmax}
\left(
\begin{array}{l}
\\
\\
\\
\end{array}
\right.
\left)
\begin{array}{l}
\\
\\
\\
\end{array}
\right.
outputs all \(\in [0,1]\), sum to \(1\)
max among the \(K\) logits
"soft" max'd in the output
\operatorname{softmax}(z) :=
\begin{bmatrix}
\frac{\exp(z_1)}{\sum_{k=1}^K \exp(z_k)} \\[6pt]
\vdots \\[6pt]
\frac{\exp(z_K)}{\sum_{k=1}^K \exp(z_k)}
\end{bmatrix}
softmax:
\mathbb{R}^K \to \mathbb{R}^K
e.g.
sigmoid
= \frac{\exp(z)}{\exp(z) +\exp (0)}
\sigma(z):=\frac{1}{1+\exp (-z)}
\mathbb{R} \to \mathbb{R}
predict the category with the highest softmax score
\operatorname{softmax}(z) :=
\begin{bmatrix}
\frac{\exp(z_1)}{\sum_{k=1}^K \exp(z_k)} \\[6pt]
\vdots \\[6pt]
\frac{\exp(z_K)}{\sum_{k=1}^K \exp(z_k)}
\end{bmatrix}
softmax:
\mathbb{R}^K \to \mathbb{R}^K
predict positive if \(\sigma(z)>0.5 = \sigma(0)\)
unifying rule: predict the class with the largest logit
implicit logit for the negative class
features
parameters
linear combo
predict
\(x \in \mathbb{R}^d\)
\(\theta \in \mathbb{R}^d, \theta_0 \in \mathbb{R}\)
\(\theta^T x +\theta_0\)
\(=z \in \mathbb{R}\)
linear logistic
binary classifier
one-out-of-\(K\) classifier
\(\theta \in \mathbb{R}^{d \times K},\)
\(=z \in \mathbb{R}^{K}\)
\(\theta^T x +\theta_0\)
predict positive if \(\sigma(z)>\sigma(0)\)
predict the class with the highest softmax score
\operatorname{softmax}(z) =
\begin{bmatrix}
\frac{\exp(z_1)}{\sum_{k=1}^K \exp(z_k)} \\[6pt]
\vdots \\[6pt]
\frac{\exp(z_K)}{\sum_{k=1}^K \exp(z_k)}
\end{bmatrix}
\sigma(z) = \frac{\exp(z)}{\exp(0) +\exp (z)}
\(\theta_0 \in \mathbb{R}^{K}\)
Outline
- Linear (binary) classifiers
- Linear logistic (binary) classifiers
-
Linear multi-class classifiers
- to use: softmax
- to learn: one-hot encoding, cross-entropy loss
One-hot encoding:
- Generalizes from \(\{0,1\}\) binary labels
Training data
| \(x\) | \(y\) | |||
| ( | 🌭 | , | "hot-dog" | ) |
| ( | 🍕 | , | "pizza" | ) |
| ( | 🥗 | , | "veggie" | ) |
| ( | 🥦 | , | "veggie" | ) |
| \(\vdots\) | ||||
\longrightarrow
K = 3
Training data
| \(x\) | \(y\) | |||
| ( | 🌭 | , | \(\begin{bmatrix}1\\0\\0\end{bmatrix}\) | ) |
| ( | 🍕 | , | \(\begin{bmatrix}0\\1\\0\end{bmatrix}\) | ) |
| ( | 🥗 | , | \(\begin{bmatrix}0\\0\\1\end{bmatrix}\) | ) |
| ( | 🥦 | , | \(\begin{bmatrix}0\\0\\1\end{bmatrix}\) | ) |
| \(\vdots\) | ||||
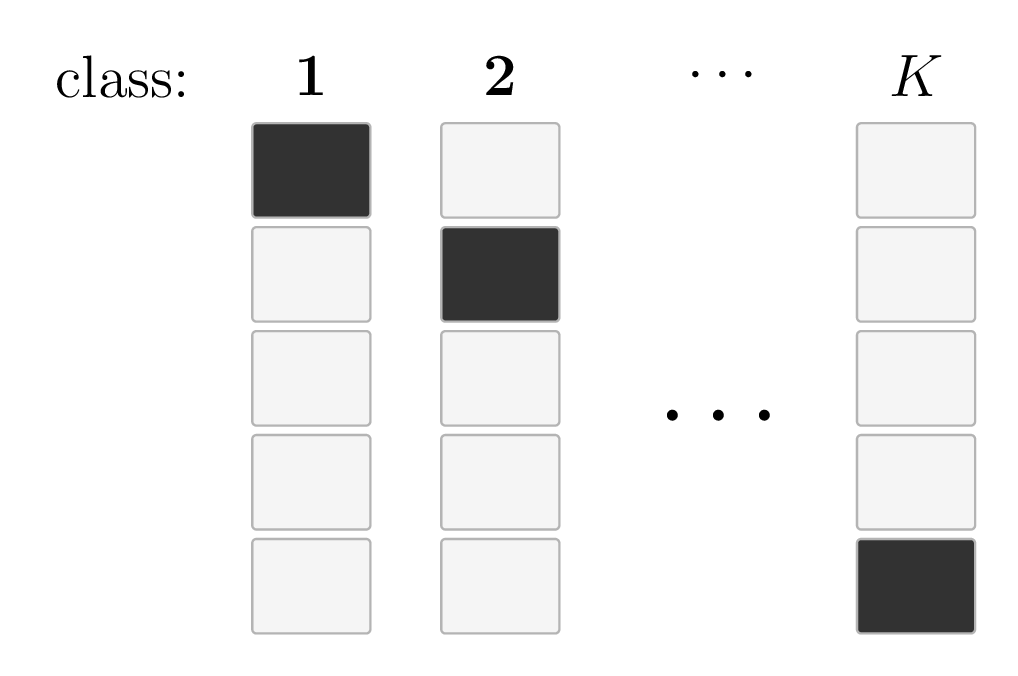
- Encode the \(K\) classes as an \(\mathbb{R}^K\) vector, with a single 1 (hot) and 0s elsewhere
in general, for \(K\) classes:
\mathcal{L}_{\mathrm{nllm}}({g}, y)=-\sum_{{k}=1}^{{K}}y_{{k}} \cdot \log \left({g}_{{k}}\right)
- Generalizes negative log likelihood loss \(\mathcal{L}_{\mathrm{nll}}({g}, {y})= - \left[y \log g +\left(1-y \right) \log \left(1-g \right)\right]\)
-
Despite the \(K\)-term sum, only the term corresponding to its true class label contributes, since all other \(y_k=0\)
Negative log-likelihood \(K\)-class loss (aka, cross-entropy)
\(y:\)one-hot encoding label
\(y_{{k}}:\) \(k\)th entry in \(y\), either 0 or 1
\(g:\) softmax output
\(g_{{k}}:\) probability or confidence of belonging in class \(k\)
🌭
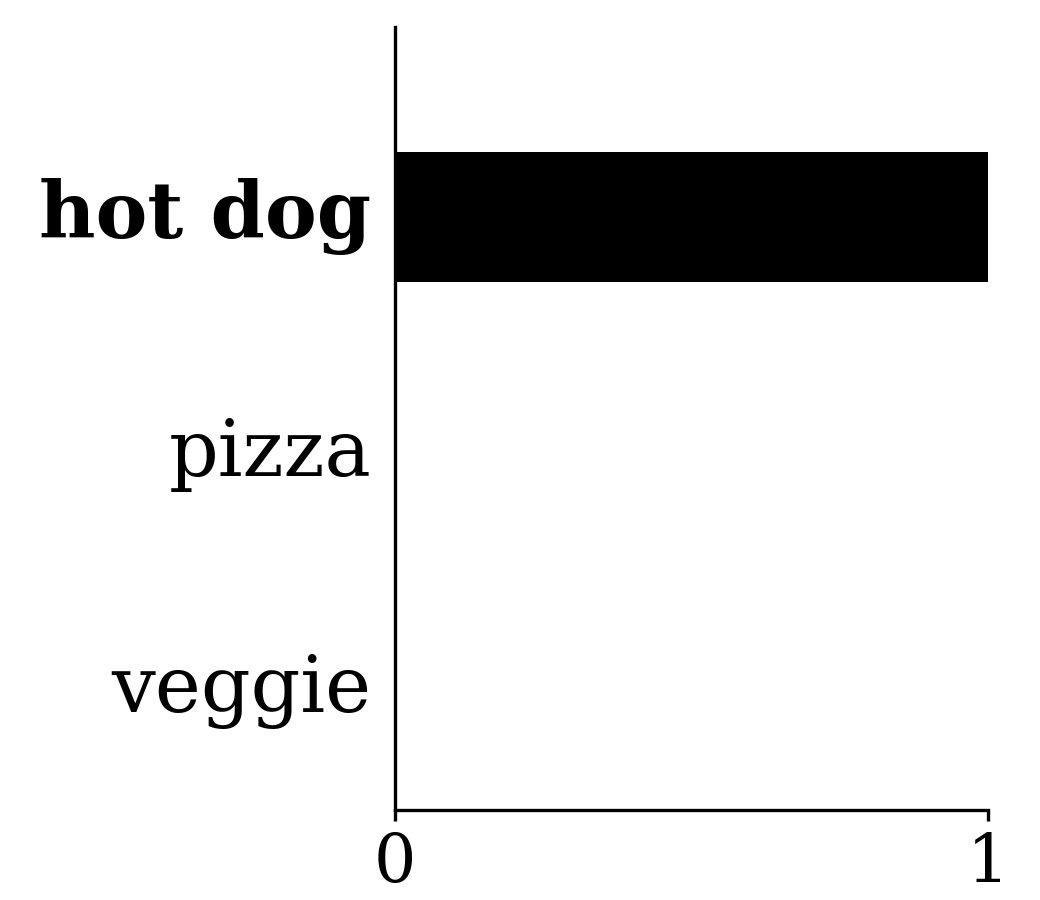
y \text{ (true label)}
= [1,\; 0,\; 0]
current prediction \(g=\text{softmax}(\cdot)\)
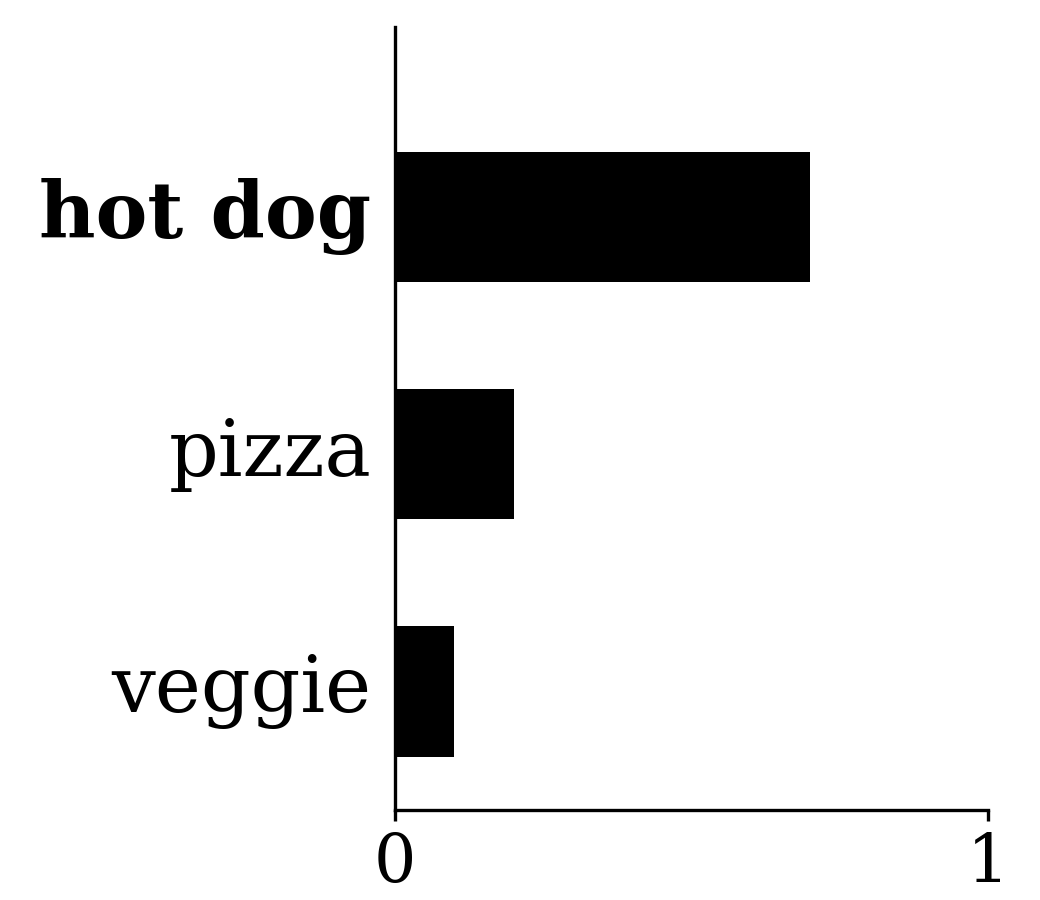
= [0.7,\; 0.2,\; 0.1]
\xrightarrow{\;-\log\;}
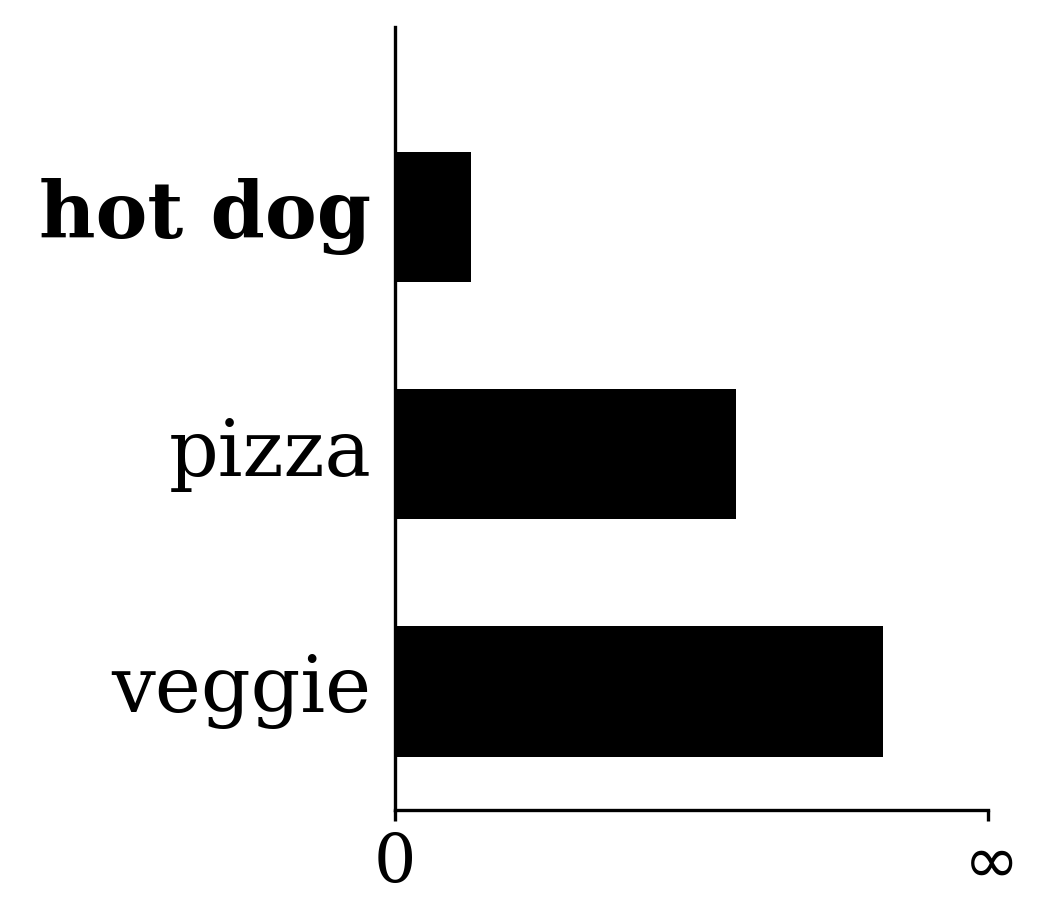
-\!\log(g)
\approx [0.36,\; 1.61,\; 2.30]
\odot
\mathcal{L}_{\mathrm{nllm}} = -\sum_{k} y_k \cdot \log(g_k)
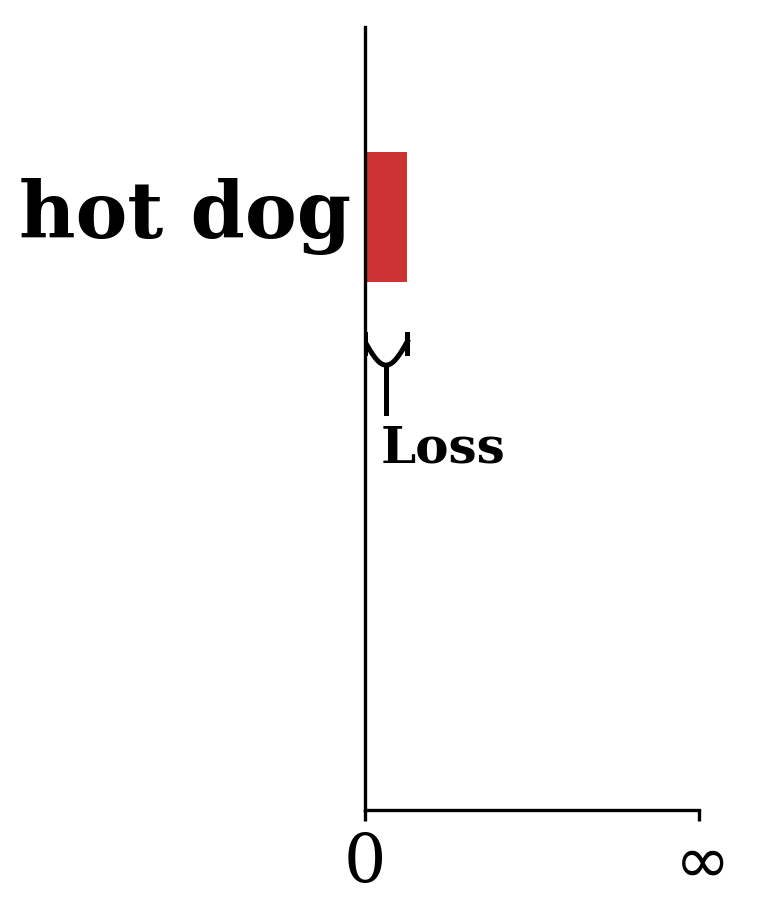
\text{Loss} \approx 0.36
To reduce the loss, \(g_{\text{hotdog}}\) needs to go up — this signal flows smoothly back to \(\theta\) through \(-\!\log\) and softmax, so we can optimize via gradient descent.
Summary
Classification predicts a label from a discrete set; a linear binary classifier separates the feature space with a hyperplane defined by \(\theta, \theta_0\).
The 0-1 loss is natural for classification but NP-hard to optimize.
The sigmoid \(\sigma(z)\) gives a smooth, probabilistic step function; paired with the NLL loss, we can train via (S)GD.
Regularization remains important for logistic classifiers.
Multi-class classification generalizes via one-hot encoding and softmax.
6.390 IntroML (Spring26) - Lecture 4 Linear Classification
By Shen Shen




